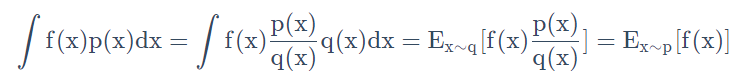Policy Gradient

在强化学习中有3个组成部分:演员(actor)、环境(environment)和·奖励函数(reward function)·
在强化学习中,环境跟奖励函数不是你可以控制的,环境跟奖励函数是在开始学习之前,就已经事先给定的。唯一能做的就是调整演员里面的策略(policy),使得演员可以得到最大的奖励。演员里面会有一个策略,这个策略决定了演员的行为。

策略一般写成π。假设用深度学习的技术来做强化学习的话,策略就是一个网路。网络里面就有一堆参数,我们用 θ 来代表 \piπ 的参数。
网络的输入就是现在机器看到的东西,如果让机器打电玩的话,机器看到的东西就是游戏的画面。机器看到什么东西,会影响你现在训练到底好不好训练。举例来说,在玩游戏的时候, 也许你觉得游戏的画面前后是相关的,也许你觉得你应该让你的策略,看从游戏初始到现在这个时间点,所有画面的总和。你可能会觉得你要用到 RNN 来处理它,不过这样子会比较难处理。要让你的机器,你的策略看到什么样的画面,这个是你自己决定的。让你知道说给机器看到什么样的游戏画面,可能是比较有效的。
输出就是机器要采取什么样的行为。
上图就是具体的例子,
策略就是一个网络;
输入 就是游戏的画面,它通常是由像素(pixels)所组成的;
输出就是看看说有哪些选项是你可以去执行的,输出层就有几个神经元。
假设你现在可以做的行为有 3 个,输出层就是有 3 个神经元。每个神经元对应到一个可以采取的行为。
输入一个东西后,网络就会给每一个可以采取的行为一个分数。你可以把这个分数当作是概率。演员就是看这个概率的分布,根据这个概率的分布来决定它要采取的行为。比如说 70% 会向左走,20% 向右走,10% 开火等等。概率分布不同,演员采取的行为就会不一样。

接下来用一个例子来说明演员是怎么样跟环境互动的。
首先演员会看到一个游戏画面,我们用 s1来表示游戏初始的画面。接下来演员看到这个游戏的初始画面以后,根据它内部的网络,根据它内部的策略来决定一个动作。假设它现在决定的动作 是向右,它决定完动作 以后,它就会得到一个奖励,代表它采取这个动作以后得到的分数。
我们把一开始的初始画面记作 s1, 把第一次执行的动作记作 a1,把第一次执行动作完以后得到的奖励记作 r1。不同的书会有不同的定义,有人会觉得说这边应该要叫做 r2,这个都可以,你自己看得懂就好。演员决定一个行为以后,就会看到一个新的游戏画面,这边是 s2
。然后把这个 s2输入给演员,这个演员决定要开火,然后它可能杀了一只怪,就得到五分。这个过程就反复地持续下去,直到今天走到某一个时间点执行某一个动作,得到奖励之后,这个环境决定这个游戏结束了。比如说,如果在这个游戏里面,你是控制绿色的船去杀怪,如果你被杀死的话,游戏就结束,或是你把所有的怪都清空,游戏就结束了。

一场游戏叫做一个回合(episode)或者试验(trail)。
把这场游戏里面所得到的奖励都加起来,就是总奖励(total reward),称之为回报(return),用R表示。
演员要想办法去最大化它可以得到的奖励。

在强化学习里面,除了环境跟演员以外,还有奖励函数(reward function)。
奖励函数根据在某一个状态采取的某一个动作决定现在这个行为可以得到多少的分数,他是一个函数,给他s1,a1,他告诉你得到r1。给他s2,a2,他告诉你得到r2。若把所有r都加起来,就可以得到R(
τ
\tau
τ),代表某一个轨迹
τ
\tau
τ 的奖励。
在某一场游戏里面, 某一个回合里面,我们会得到 R。我们要做的事情就是调整演员内部的参数
θ
\theta
θ, 使得 R 的值越大越好。在给定某一组参数
θ
\theta
θ 的情况下,我们会得到的 R(
θ
\theta
θ)的期望值是多少。
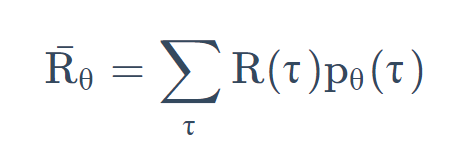
可以根据 \thetaθ 算出某一个轨迹
τ
\tau
τ 出现的概率,接下来计算这个
τ
\tau
τ 的总奖励是多少。总奖励使用这个 \tauτ 出现的概率进行加权,对所有的
τ
\tau
τ 进行求和,就是期望值。给定一个参数,你会得到的期望值。
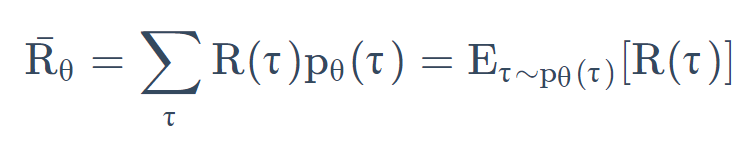
我们还可以写成上式那样,从 p θ(
τ
\tau
τ)这个分布采样一个轨迹
τ
\tau
τ,然后计算 R(
τ
\tau
τ)的期望值,就是你的期望的奖励。 我们要做的事情就是最大化期望奖励。

怎么最大化期望奖励呢?我们用的是梯度上升(gradient ascent),因为要让它越大越好,所以是梯度上升。梯++度上升在更新参数的时候要加。
Tips
1、Add a baseline
 如果给定状态 s 采取动作 a 会给你整场游戏正的奖励,就要增加它的概率。如果状态 s 执行动作 a,整场游戏得到负的奖励,就要减少这一项的概率。
如果给定状态 s 采取动作 a 会给你整场游戏正的奖励,就要增加它的概率。如果状态 s 执行动作 a,整场游戏得到负的奖励,就要减少这一项的概率。
但在很多游戏里面,奖励总是正的,就是说最低都是 0。比如说打乒乓球游戏, 你的分数就是介于 0 到 21 分之间,所以 R 总是正的。假设你直接套用这个式子, 在训练的时候告诉模型说,不管是什么动作你都应该要把它的概率提升。 在理想上,这么做并不一定会有问题。因为虽然说 R 总是正的,但它正的量总是有大有小,你在玩乒乓球那个游戏里面,得到的奖励总是正的,但它是介于 0~21分之间,有时候你采取某些动作可能是得到 0 分,采取某些动作可能是得到 20 分。

假设你在某一个状态有 3 个动作 a/b/c可以执行。根据下式
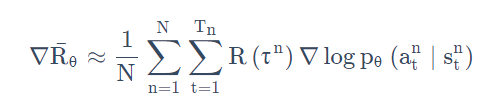
你要把这 3 项的概率,对数概率都拉高。 但是它们前面权重的 R 是不一样的。 R 是有大有小的,权重小的,它上升的就少,权重多的,它上升的就大一点。 因为这个对数概率是一个概率,所以动作 a、b、c 的对数概率的和要是 0。 所以上升少的,在做完归一化(normalize)以后, 它其实就是下降的,上升的多的,才会上升。

这是一个理想上的状况,但是实际上,我们是在做采样就本来这边应该是一个期望(expectation),对所有可能的 s 跟 a 的对进行求和。 但你真正在学的时候不可能是这么做的,你只是采样了少量的 s 跟 a 的对而已。 因为我们做的是采样,有一些动作可能从来都没有采样到。在某一个状态,虽然可以执行的动作有 a/b/c,但你可能只采样到动作 b,你可能只采样到动作 c,你没有采样到动作 a。但现在所有动作的奖励都是正的,所以根据这个式子,它的每一项的概率都应该要上升。你会遇到的问题是,因为 a 没有被采样到,其它动作的概率如果都要上升,a 的概率就下降。 所以 a 不一定是一个不好的动作, 它只是没被采样到。但只是因为它没被采样到, 它的概率就会下降,这个显然是有问题的,要怎么解决这个问题呢?你会希望你的奖励不要总是正的。
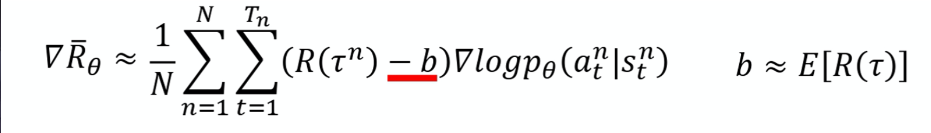
2、Assign Suitable Credit
如果我们看下面这个式子的话,
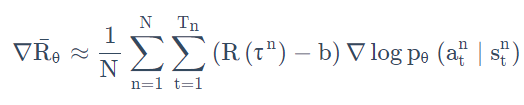
我们原来会做的事情是,在某一个状态,假设你执行了某一个动作 a,它得到的奖励,它前面乘上的这一项 R(
τ
\tau
τn)-b。
只要在同一个回合里面,在同一场游戏里面, 所有的状态跟动作的对都会使用同样的奖励项(term)进行加权,这件事情显然是不公平的,因为在同一场游戏里面 也许有些动作是好的,有些动作是不好的。 假设整场游戏的结果是好的, 并不代表这个游戏里面每一个行为都是对的。若是整场游戏结果不好, 但不代表游戏里面的所有行为都是错的。所以我们希望可以给每一个不同的动作前面都乘上不同的权重。每一个动作的不同权重, 它反映了每一个动作到底是好还是不好。

举个例子, 假设这个游戏都很短,只有 3–4 个互动, 在sa执行 a1得到 5 分。在 sb 执行 a2得到 0 分。在 sc执行 a3得到 -2 分。 整场游戏下来,你得到 +3 分,那你得到 +3 分 代表在 sb执行动作 a2是好的吗?并不见得代表 sb执行 a2是好的。因为这个正的分数,主要来自于在 sa执行了 a1,跟在 sb 执行 a2是没有关系的,也许在 sb执行 a2反而是不好的, 因为它导致你接下来会进入 sc,执行 a3被扣分,所以整场游戏得到的结果是好的, 并不代表每一个行为都是对的。
一个做法是计算这个对的奖励的时候,不把整场游戏得到的奖励全部加起来,只计算从这一个动作执行以后所得到的奖励

本来的权重是整场游戏的奖励的总和,现在改成从某个时间 tt 开始,假设这个动作是在 tt 这个时间点所执行的,从 tt 这个时间点一直到游戏结束所有奖励的总和,才真的代表这个动作是好的还是不好的。
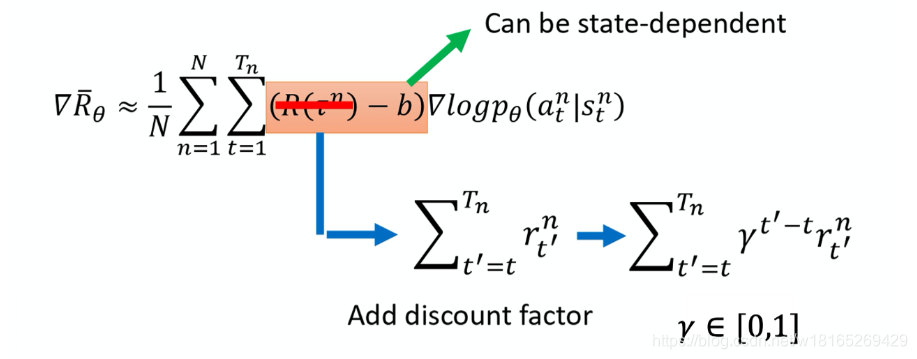
接下来再更进一步,我们把未来的奖励做一个折扣(discount),由此得到的回报被称为Discounted Return(折扣回报)。