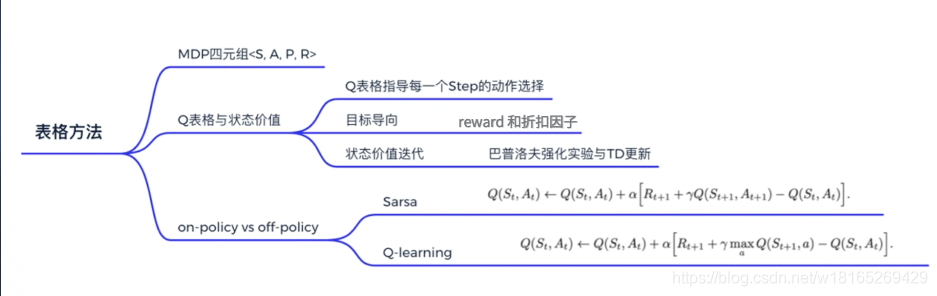
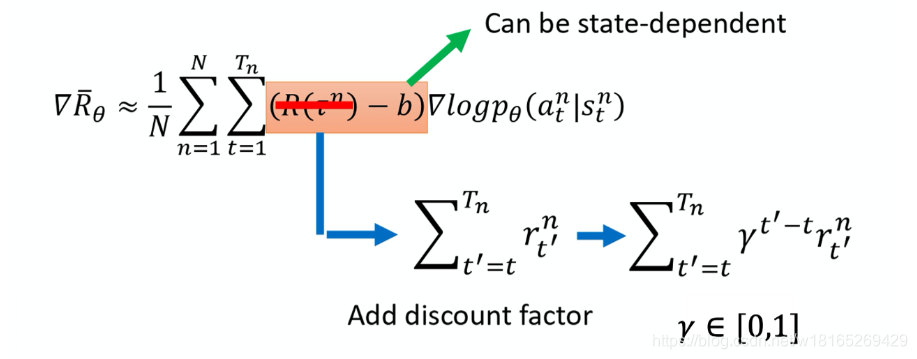
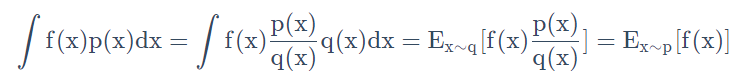Tabular Methods
本章通过最简单的表格型的方法(tabular methods)来讲解如何使用value_based方法求解强化学习。
Model-based

如上图所示。去跟环境交互时,只能走完完整的一条路。这里面产生了一系列的一个决策过程,这就是跟环境交互产生了一个经验。**使用P函数(probability function)和R函数(reward function)去描述环境。**P函数就是状态转移函数的概率,P函数实际上反应的是环境的一个随机性。
当我们知道P函数和R函数时,我们就说这个MDP是已知的,可以通过policy iteration 和 value iteration 来找最佳的策略
例如上图所示,在熊发怒的情况下,如果选择装死,假设熊看到人装死就一定会走的话,我们就称在这里面的状态转移概率就是 100%。但如果说在熊发怒的情况下,我选择跑路而导致可能跑成功以及跑失败,出现这两种情况。那我们就可以用概率去表达一下说转移到其中一种情况的概率大概 10%,另外一种情况的概率大概是 90% 会跑失败。
如果知道这些状态转移概率和奖励函数的话,我们就说这个环境是已知的,因为我们是用这两个函数去描述环境的。 如果是已知的话,我们其实可以用动态规划去计算说,如果要逃脱熊,那么能够逃脱熊概率最大的最优策略是什么。很多强化学习的经典算法都是 model-free 的,就是环境是未知的。
Model-free

因为现实世界中人类第一次遇到熊之前,我们根本不知道能不能跑得过熊,所以刚刚那个 10%、90% 的概率也就是虚构出来的概率。熊到底在什么时候会往什么方向去转变的话,我们经常是不知道的。
我们是处于一个未知的环境里,也就是说这一系列的决策的P函数和R函数都是未知的,这就是model-based和model-free的一个最大的区别。
化学习要像人类一样去学习,人类学习的话就是一条路一条路地去尝试一下,先走一条路,看看结果到底是什么。多试几次,只要能活命的。我们可以慢慢地了解哪个状态会更好,
我们用价值函数 V(s)来代表这个状态是好的还是坏的。
用 Q 函数来判断说在什么状态下做什么动作能够拿到最大奖励,用 Q 函数来表示这个状态-动作值。
Model-based和Model-free

Policy iteration 和 value iteration 都需要得到环境的转移和奖励函数,所以在这个过程中,agent 没有跟环境进行交互。
在很多实际的问题中,MDP 的模型有可能是未知的,也有可能模型太大了,不能进行迭代的计算。比如 Atari 游戏、围棋、控制直升飞机、股票交易等问题,这些问题的状态转移太复杂了。
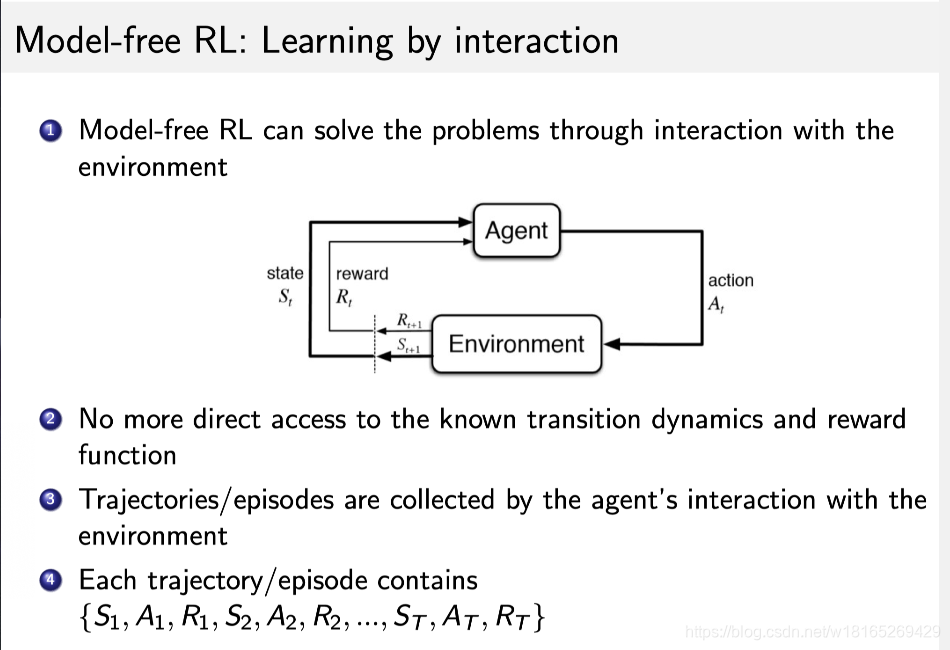
在这种情况下,我们使用 model-free 强化学习的方法来解。
Model-free 没有获取环境的状态转移和奖励函数,我们让 agent 跟环境进行交互,采集到很多的轨迹数据,agent 从轨迹中获取信息来改进策略,从而获得更多的奖励。
Q-table

接下来介绍Q函数,在多次尝试和熊打交道之后,人类就可以对熊的不同状态去做出判断,我们可以用状态动作价值来表达说在某个状态下,为什么动作1会比动作2好,因为动作1的价值比动作2要高,这个价值就叫做Q函数
如果Q表格是一张已经训练好的表格的话,那这一张表格就像是一本生活手册,就知道在熊发怒的时候,装死的价值会更高一点。在熊离开的时候,我们肯能偷偷逃跑的会比较容易获救。

Q:为什么可以用未来的总收益来评价当前这个动作是好是坏?
A:如上图所示,假设一辆车在路上,当前是红灯,直接走的收益很低,因为违反交通规则,这就是当前的单步收益。可如果这是一辆正在运送病人的救护车,把病人送到医院的收益非常高,而且越快收益越大。在这种情况下,我们很可能应该要闯红灯,因为未来的收益太高了。这也是强化学习需要去学习远期收益,因为在现实世界中奖励往往是有延迟的。所以我们一般会从当前状态开始,把后续有可能会收到所有收益加起来计算当前动作的Q的价值,让Q的价值可以真正地代表当前这个状态下,动作真正的价值。
但有的时候把目光放得太长远不好,因为如果事情很快就结束的话,你考虑到最后一步的收益无可厚非。如果是一个持续的没有尽头的任务,即持续式任务(Continuing Task),你把未来的收益全部相加,作为当前的状态价值就很不合理。
Monte-Calor Policy Evaluation

蒙特卡罗(Monte-Calor,MC)方法是基于采样地方法,让agent跟环境进行交互,就会得到很多轨迹,每个轨迹都有对应地return:

把每个轨迹地return进行平均,就可以知道某一个策略下面对应的状态地价值。
MC是用经验平均回报(empirical mean return)的方法来估计。
MC方法不需要MDP的转移函数和奖励函数,并且不需要动态规划那样用bootstrapping的方法。
MC的局限性:只能用于有终止的MDP。

为了得到评估 v(s)v(s),我们进行了如下的步骤:
在每个回合中,如果在时间步 t 状态 s 被访问了,那么
状态 s 的访问数 N(s)增加 1,
状态 s 的总的回报 S(s) 增加 Gt
状态 s 的价值可以通过 return 的平均来估计,即 v(s)=S(s)/N(s)。
根据大数定律,只要我们得到足够多的轨迹,就可以趋近这个策略对应的价值函数。 我们可以把 Monte-Carlo 更新的方法写成 incremental MC 的方法:
我们可以把 Monte-Carlo 更新的方法写成 incremental MC 的方法:
我们采集数据,得到一个新的轨迹。
对于这个轨迹,我们采用增量的方法进行更新,如下式所示:
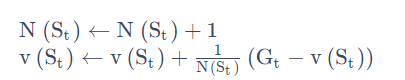
我们可以直接把 1/N(St)变成 \alphaα (学习率),α 代表着更新的速率有多快,我们可以进行设置。
我们再来看一看DP和MC方法的差异。:
动态规划算法也是常用的估计价值函数的方法,在动态规划算法里面,我们使用了bootstrapping的思想。bootstrapping的意思是我们基于之前估计的量来估计一个量。
DP就是用Bellman expectation backup,就是通过上一时刻Vi-1(s’)来更新当前时刻Vi(s)这个值,不停迭代,最后可以收敛。

MC是通过empirical mean return(实际得到的收益)来更新它,对应树上面蓝色的轨迹,我们得到的是一个实际的轨迹,实际的轨迹上的状态已经是决定的,采取的行为都是决定的。MC得到的是一条轨迹,这条轨迹表现出来就是这个蓝色的从起始到最后终止状态的轨迹。现在知识更新这个轨迹上的所有状态,跟这个轨迹没有关系的状态都没有更新。
MC相对于DP的优势
MC可以在不知道环境的情况下work,而DP是model-based。
MC只需要更新一条轨迹的状态,而DP需更新所有的状态。
Temporal Difference

为了更好的理解时序差分(Temporal Difference,TD)这种更新方法,先给出他的物理意义。
我们先理解一下巴普洛夫的条件反射实验,这个实验讲的是小狗会对盆里面的食物无条件产生刺激,分泌唾液。一开始小狗对于铃声这种中性刺激是没有反应的,可是我们把这个铃声和食物结合起来,每次先给它响一下铃,再给它喂食物,多次重复之后,当铃声响起的时候,小狗也会开始流口水。盆里的肉可以认为是强化学习里面那个延迟的 reward,声音的刺激可以认为是有 reward 的那个状态之前的一个状态。多次重复实验之后,最后的这个 reward 会强化小狗对于这个声音的条件反射,它会让小狗知道这个声音代表着有食物,这个声音对于小狗来说也就有了价值,它听到这个声音也会流口水。
 巴普洛夫效应揭示的是中性刺激(铃声)跟无条件刺激(食物)紧紧挨着反复出现的时候,条件刺激也可以引起无条件刺激引起的唾液分泌,然后形成这个条件刺激。
巴普洛夫效应揭示的是中性刺激(铃声)跟无条件刺激(食物)紧紧挨着反复出现的时候,条件刺激也可以引起无条件刺激引起的唾液分泌,然后形成这个条件刺激。
这种中性刺激跟无条件刺激在时间上面的结合,我们就称之为强化。 强化的次数越多,条件反射就会越巩固。小狗本来不觉得铃声有价值的,经过强化之后,小狗就会慢慢地意识到铃声也是有价值的,它可能带来食物。更重要是一种条件反射巩固之后,我们再用另外一种新的刺激和条件反射去结合,还可以形成第二级条件反射,同样地还可以形成第三级条件反射。
在人的身上是可以建立多级的条件反射的,举个例子,比如说一般我们遇到熊都是这样一个顺序:看到树上有熊爪,然后看到熊之后,突然熊发怒,扑过来了。经历这个过程之后,我们可能最开始看到熊才会瑟瑟发抖,后面就是看到树上有熊爪就已经有害怕的感觉了。也就说在不断的重复试验之后,下一个状态的价值,它是可以不断地去强化影响上一个状态的价值的。
下面正式介绍TD方法
TD是介于MC和DP之间的方法。
TD是model-free的,不需要MDP的转移矩阵和奖励函数。
TD可以从不完整的episode中学习,结合了bootstrapping的思想。
上图是TD算法的框架:
目的:对于给定的策略,在线地算出它的价值函数,即一步一步的算
最简单的算法是TD(0),每往前走一步,就做一步bootstrapping,用得到的估计回报(estimated return)来更新上一时刻的值。
轨迹回报Rt+1+
γ
\gamma
γv(St+1)被称为TD target,TD target 是带衰减的未来收益的总和。TD target由两部分组成:
走了某一步后得到的实际奖励Rt+1,
利用bootstrapping方法,通过之前的来估计v(St+1),然后加了一个折扣系数,即
γ
\gamma
γv(St+1),具体过程如下所示:
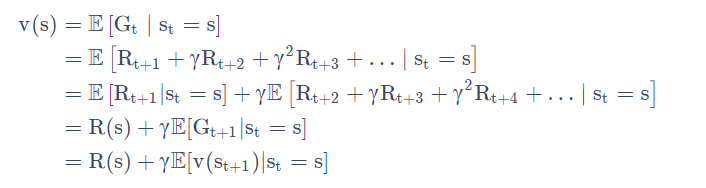
TD errorδ=R t+1+
γ
\gamma
γv(St+1)-v(St)
可以类比于 Incremental Monte-Carlo 的方法,写出如下的更新方法:
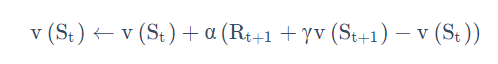
对比MC和TD

在 MC 里面Gi,t是实际得到的值(可以看成 target),因为它已经把一条轨迹跑完了,可以算每个状态实际的 return。
TD 没有等轨迹结束,往前走了一步,就可以更新价值函数。
TD只执行一步,状态的值就更新。
MC全部走完之后,到了终止状态之后,再更新它的值。
TD可以在线学习,每走一步就可以更新,效率高。
MC必须等到游戏结束才可以学习。
TD可以从不完整序列上进行学习。
MC只能从完整学列上进行学习。
TD可以在连续的环境下(没有终止)进行学习。
MC只能在有终止的情况下学习。
TD利用了马尔可夫性质,在马尔科夫环境下有更高的学习效率。
MC没有假设环境具有马尔可夫性质,利用采样的价值来估计某一个状态的价值,在不是马尔科夫的环境下更加有效。
TD 能够在知道结果之前就开始学习,相比 MC,其更快速、灵活。
 我们可以把 TD 进行进一步的推广。之前是只往前走一步,即 one-step TD,TD(0)。
我们可以把 TD 进行进一步的推广。之前是只往前走一步,即 one-step TD,TD(0)。
我们可以调整步数,变成n-step TD。比如 TD(2),即往前走两步,然后利用两步得到的 return,使用 bootstrapping 来更新状态的价值。
这样就可以通过 step 来调整这个算法需要多少的实际奖励和 bootstrapping。
通过调整步数,可以进行一个 MC 和 TD 之间的 trade-off,如果 n=∞, 即整个游戏结束过后,再进行更新,TD 就变成了 MC。
n-step 的 TD target 如下式所示:
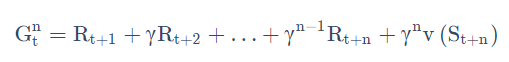
得到 TD target 之后,我们用增量学习(incremental learning)的方法来更新状态的价值: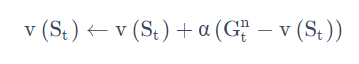
Bootstrapping and Sampling for DP,MC and TD
Bootstrapping:更新时使用了估计:
MC 没用 bootstrapping,因为它是根据实际的 return 来更新。
DP 用了 bootstrapping。
TD 用了 bootstrapping。
Sampling:更新时通过采样得到一个期望:
MC 是纯 sampling 的方法。
DP 没有用 sampling,它是直接用 Bellman expectation equation 来更新状态价值的。
TD 用了 sampling。TD target 由两部分组成,一部分是 sampling,一部分是 bootstrapping。
Model-free Control
Q: 当我们不知道 MDP 模型情况下,如何优化价值函数,得到最佳的策略?
A: 我们可以把 policy iteration 进行一个广义的推广,使它能够兼容 MC 和 TD 的方法,即Generalized Policy Iteration(GPI) with MC and TD。

Policy iteration 由两个步骤组成:
根据给定的当前的 policy \piπ 来估计价值函数;
得到估计的价值函数后,通过 greedy 的方法来改进它的算法。
这两个步骤是一个互相迭代的过程。

得到一个价值函数过后,我们并不知道它的奖励函数和状态转移,所以就没法估计它的 Q 函数。所以这里有一个问题:当我们不知道奖励函数和状态转移时,如何进行策略的优化。在这里插入图片描述
针对上述情况,我们引入了广义的 policy iteration 的方法。
我们对 policy evaluation 部分进行修改:用 MC 的方法代替 DP 的方法去估计 Q 函数。
当得到 Q 函数后,就可以通过 greedy 的方法去改进它。

上图是用 MC 估计 Q 函数的算法。
假设每一个 episode 都有一个 exploring start,exploring start 保证所有的状态和动作都在无限步的执行后能被采样到,这样才能很好地去估计。
算法通过 MC 的方法产生了很多的轨迹,每个轨迹都可以算出它的价值。然后,我们可以通过 average 的方法去估计 Q 函数。Q 函数可以看成一个 Q-table,通过采样的方法把表格的每个单元的值都填上,然后我们使用 policy improvement 来选取更好的策略。
算法核心:如何用 MC 方法来填 Q-table。
 为了确保 MC 方法能够有足够的探索,我们使用了 ε-greedy exploration。
为了确保 MC 方法能够有足够的探索,我们使用了 ε-greedy exploration。
ε-greedy 的意思是说,我们有 1−ε 的概率会按照 Q-function 来决定 action,通常ε 就设一个很小的值,1−ε 可能是 90%,也就是 90% 的概率会按照 Q-function 来决定 action,但是你有 10% 的机率是随机的。通常在实现上ε 会随着时间递减。在最开始的时候。因为还不知道那个 action 是比较好的,所以你会花比较大的力气在做 exploration。接下来随着训练的次数越来越多。已经比较确定说哪一个 Q 是比较好的。你就会减少你的 exploration,你会把 \varepsilonε 的值变小,主要根据 Q-function 来决定你的 action,比较少做 random,这是 ε-greedy。

当我们使用 MC 和ε-greedy 探索这个形式的时候,我们可以确保价值函数是单调的,改进的。
上图是带ε-greedy 探索的 MC 算法的伪代码。

与 MC 相比,TD 有如下几个优势:
低方差。
能够在线学习。
能够从不完整的序列学习。
所以我们可以把 TD 也放到 control loop 里面去估计 Q-table,再采取这个 ε-greedy improvement。这样就可以在 episode 没结束的时候来更新已经采集到的状态价值。
TD 是给定了一个策略,然后我们去估计它的价值函数。接着我们要考虑怎么用 TD 这个框架来估计 Q-function。

Sarsa 所作出的改变很简单,就是将原本我们 TD 更新 V 的过程,变成了更新 Q,如下式所示:
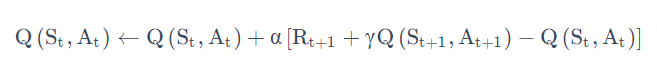 这个公式就是说可以拿下一步的 Q(St+1,At+1) 值 来更新我这一步的 Q 值Q(St,At)。
这个公式就是说可以拿下一步的 Q(St+1,At+1) 值 来更新我这一步的 Q 值Q(St,At)。
Sarsa 是直接估计 Q-table,得到 Q-table 后,就可以更新策略。

Sarsa 算法由于每次更新值函数需要知道当前的状态(state)、当前的动作(action)、奖励(reward)、下一步的状态(state)、下一步的动作(action),即(St,At+1,Rt+1,St+1,At+1)这几个值 ,由此得名 Sarsa 算法。它走了一步之后,拿到了St,At+1,Rt+1,St+1,At+1)之后,就再做一次更新。

Q-learning

**On-policy与Off-policy


我们再通过对比的方式来进一步理解Q-learning。Q-learning 是 off-policy 的时序差分学习方法,Sarsa 是 on-policy 的时序差分学习方法。
Summary