前期知识可查看:
案例介绍
寻路案例:(强烈建议学习上述前期知识里的【强化学习】 Q-Learning 尤其是看懂前面的小案例)
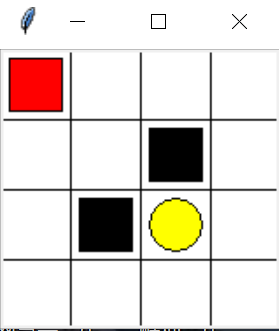
- 红色为可移动的寻路个体
- 黑色为惩罚位置【奖励= -1】
- 黄色为目标位置【奖励= +1】
- 其他区域为常规状态【奖励= 0】
寻路个体其实位置如图中所示的左上角,目标是移动到黄色位置,采用Q-Learning算法,能够让个体自主探索,最后找到最好的可以从起始点到终点位置的路径,同时绕过黑色区域
程序
该案例的程序分为三个部分:
- maze_env.py : 该案例的环境部分,即:该图片以及这些颜色块的搭建,采用了Tkinter
- RL_brain.py:该案例的Q-Learning的大脑,智能体的大脑部分,所有决策都在这部分
- run_this.py:该案例的主要实施流程以及更新
1. maze_env.py
环境部分采用了Tkinter搭建这些图片以及这些颜色块,有兴趣的可以仔细分析代码,暂时不细说
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
def update():
for t in range(10):
s = env.reset()
while True:
env.render()
a = 1
s, r, done = env.step(a)
if done:
break
if __name__ == '__main__':
env = Maze()
env.after(100, update)
env.mainloop()2. RL_brain.py
该部分为Q-Learning的大脑部分,所有的巨册函数都在这儿
(1)参数初始化,包括算法用到的所有参数:行为、学习率、衰减率、决策率、以及q-table
(2)方法1:选择动作:随机数与决策率做对比,决策率为0.9,90%情况选择下一个反馈最大的奖励的行为,10%情况选择随机行为
(3)方法2:学习更新q-table:通过数据参数(该状态、该行为、该行为对该状态的奖励、下一个状态),计算该行为在该状态下的真实值与估计值,然后更新q-table里的预估值
(4)方法3:用来将新的状态作为索引添加在q-table里
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate # 学习率
self.gamma = reward_decay # 衰减率
self.epsilon = e_greedy # 决策率
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64) # 初始化q-table
# 选择动作
def choose_action(self, observation):
self.check_state_exist(observation) # 检查该状态是否在q-table中存在,如不存在则添加
# 行为选择
if np.random.uniform() < self.epsilon:
# 如果随机数小于0.9 则选择最优行为
state_action = self.q_table.loc[observation, :]
# 有一些行为可能存在相同的最大预期值,则在最大预期值行为里随机选择
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# 如果随机数大于0.9 则随机选择
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_) # 检擦新的状态是否存在与q-table
q_predict = self.q_table.loc[s, a] # 获取该行为在该状态下的估计的奖励预期值
if s_ != 'terminal': # 如果新的状态不是最终目的地
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # 真实值=该行为对该状态的奖励+衰减率*下一个状态下行为的最大反馈奖励
else: # 如果到达了最终目的地,没有下一个行为,因此不需要学习了,真实值=该行为对该状态的奖励
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # 更新q-table
# 检查状态是否存在,若不存在将作为索引添加在 q-table中,行为的值初始化为0
def check_state_exist(self, state):
if state not in self.q_table.index:
# 如果该状态不在q-table的索引里存在,则将该状态添加到q-table中,
# q-table是dataframe类型,字典的索引为状态,值的表头有四种【0,1,2,3】,分别代表前、后、左、右的行为
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)3. run_this.py
该脚本就是算法实施的主要流程:

(1)引入了环境(maze_env)和大脑(RL_brain)
(2)环境reset()给出了初始状态(Initialize s)
(3)循环开始(Repeat)
- 刷新环境
- 挑选动作(Choose a from s)
- 从环境中获取该动作对该状态的反馈(下一个状态、该行为对该状态的奖励、是否到达终点)(observe r, s')
- 开始学习,输入参数(该状态、该行为、该行为对该状态的奖励、下一个状态)——对比估计值和现实值,学习完之后将更新q-table(Q(s,a))
- 更新个体状态到新的状态(s<--s')
- 判断是否到达终点:跳出循环(until s is terminal)
from maze_env import Maze # 环境模块
from RL_brain import QLearningTable # 大脑
def update(): # (Repeat)
for episode in range(100): # 100个回合
observation = env.reset() # 初始化观察值 (Initialize s)
while True:
env.render() # 刷新环境
action = RL.choose_action(str(observation)) # 挑选动作 (Choose a from s)
observation_, reward, done = env.step(action) # 在环境里施加动作,获取下一个状态、行为对于该状态的奖励、是否完成 (observe r, s')
# 一个回合之后的学习,将该状态,该行为,该行为对于该状态的奖励,以及下一个状态 输入到学习的方法中
RL.learn(str(observation), action, reward, str(observation_)) # Q(s,a))
observation = observation_ # 更新个体状态 (s<--s')
if done:
break # 如果反馈达到目的地,跳出循环 (until s is terminal)
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()完成之后,在run_this.py里运行就可以看到学习探索路径的过程了
代码以及学习过程来源:莫烦Python教学(十分感谢莫烦大佬的教学视频)