

















最大化 Expected cumulative reward 期望累计奖励




Q(s0,a0)表示:当状态为s0,做a0的动作,期望累计奖励是Q。

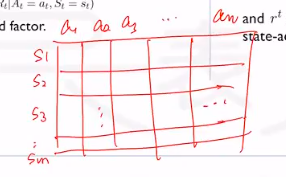
如果我们有n个action,m个state,理论上我们将有nm的Q值。笛卡尔积。
这个表就是Q table。

Q就是在初始状态为s0和a0的时候,最终可以获得的累积reward的最大值是多少。


因为γ在公式中是t次方,所以随着t的增加,γ**t是不断减小的,所以它是衰减因子 discounted factor。a1和s2是初始状态






Q(), 括号里是初始的state和action。当Q1(s1,a1)=5,然后经历了s2,a1这个值。那么就是Q2 (s1,a1=5+2=7




target policy: 是为了更新Q value
behavior policy:是为了更新action。
如果target和behavior结果一直,就是on-policy algorithm。否则就是off-policy algorithm。off-policy就是有时候policy可能抑制action的发生,所以它不会去执行这个action。







spring boot
数据分析
星辰处理器
单元测试
注解处理器
react.js
二叉树
cloud alibaba
OTA
渲染
技术美术
分享功能
社区论坛
hidapi
制图表达
volatile
微信授权功能
condition
哈夫曼树
session_key
5328笔记 Advanced ML Chapter10-Reinforcement Learning
相关文章

富文本编辑器实现word图片自动上传
图片的复制无非有两种方法,一种是图片直接上传到服务器,另外一种转换成二进制流的base64码 目前限chrome浏览器使用 首先以um-editor的二进制流保存为例: 打开umeditor.js,找到UM.plugins[autoupload],然后找到autoUpl…

windows平台下载android源代码
最近观看《android核心分析》,所以很多细节都没有详细看代码很难理解。请记住,印象不深。感觉是最好再一起去的源代码,返回下载android源代码,遇到了许多问题,最后开始下载。合并流程,鉴于网上的教程非常多…

架构之路(三) 单元测试
实事求是的讲,写《【野生程序员】:优先招聘》的时候,是带着情绪的。其后也有反思,是不是我杞人忧天了?尤其是下面开始的几条评论,如“都是混口饭吃的不容易”,“何以内外之分,中华儿…

富文本编辑器实现一键上传word图片
1.4.2之后官方并没有做功能的改动,1.4.2在word复制这块没有bug,其他版本会出现手动无法转存的情况 本文使用的后台是Java。前端为Jsp(前端都一样,后台如果语言不通得自己做 Base64编码解码)
因为公司业务需要支持IE8 …

5328笔记 Advanced ML Chapter11-Causal Inference
辛普森悖论的原因是样本数量不匹配。TreatmentA对大小结实治愈率都高过TreatmentB,但是总的治愈率却低于B。 当添加了Age后,biking和cholesterol的关系从正相关变为了负相关。 correlation正相关,causation因果关系 从上面冰激凌的例子…
【C/C++学院】0813-C与CPP不同以及命名空间简介/函数重载与函数默认参数/泛型auto/Newdelete...
C与CPP不同以及命名空间简介 命名空间在软件设计中的作用就是为了实现迭代式开发。 命名空间的别名 #include <iostream>namespace runrunrunrun
{int a(10);char *str("gogogo");namespace run //命名空间的嵌套{int a(9);}
}
namespace runrunrunrun //命…

Advanced ML Chapter12-Multi-Task Learning
下面的要训练m次。 假设所有任务之间,有共同的一个参数ω0. ωi ω0 Δωi的意思是ωi在ω0的基础上,有一个变化量 Δωi λ Δ||ω||2加了正则想,如果多任务的相关性比较强,那么loss就比较低,训练的比较好。但是…

富文本编辑器实现一键复制word图片
由于工作需要必须将word文档内容粘贴到编辑器中使用
但发现word中的图片粘贴后变成了file:///xxxx.jpg这种内容,如果上传到服务器后其他人也访问不了,网上找了很多编辑器发现没有一个能直接解决这个问题
考虑到自己除了工作其他时间基本上不使用window…