先来个名言,日本著名设计师山本耀司曾说:
“我从来不相信什么懒洋洋的自由,我向往的自由是通过勤奋和努力实现的更广阔的人生,那样的自由才是珍贵的、有价值的;我相信一万小时定律,我从来不相信天上掉馅饼的灵感和坐等的成就。做一个自由又自律的人,靠势必实现的决心认真地活着。”
1
了解原理
我们先了解下心理学行为主义学习理论的中
泛化律
。别问我为什么一篇技术文章为何突然跑心理学理论,这是 mixlab 的文章特色:
一篇文章尽量涉及2个以上不同领域的内容,跨界思考之间的关联性
。
1.1 心理学行为主义学习理论
巴甫洛夫在研究狗的进食行为时发现,当铃声和喂食反复配对后,只给狗听铃声,不呈现食物,狗也会分泌唾液。根据这一实验现象,巴甫洛夫提出经典性条件作用,其中的
泛化律
:
条件反射一旦确立,其他类似最初条件刺激的刺激也可引起条件反射
。例如,谚语“一朝被蛇咬,十年怕草绳”,人见到蛇感到害怕是以往建立的条件反射,而由于草绳类似蛇这个条件刺激,因此当见到与蛇类似的草绳也会引起条件反射。
1.2 行为主义学习理论在教育领域
行为主义学习在教育领域的案例,例如,父母
不断给
孩子关心和
鼓励
,孩子就会把学习和愉快的体验联系起来,然后,更加喜欢学习。当孩子有强烈的“问问题”意愿时,父母如果没有满足他们,他们的积极性就会不断被磨灭。
1.3 Q-learning 的原型
此部分的理解先要对强化学习的
Environment、 Agent、Actions、Observation、Reward 、Policy
有基础的认识,才可继续。
Q-learning 从行为主义学习理论启发而来,最早由 Watkins 在 1989 提出核心思想原型,当时提出记忆矩阵 W(a,s) 记忆了“
智能体
”以往的经验,当新的外部刺激时,“智能体”会产生对应的条件反射,W(a,s) 类似于我们今天所说的 Q-learning 中的
Q-table
。
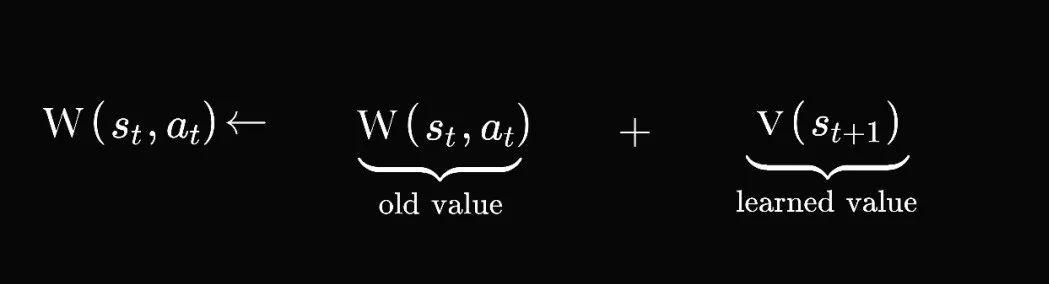
核心思想:
1 智能体 Agent 在状态 st ,采取行为 at;
2 后移至下一个状态 st+1;
3 估计价值 v(st+1);
4 更新记忆矩阵,见上图;
5 反复1-4过程,更新记忆矩阵。
我们继续第一篇文章所提到的“小孩学走路”的例子,孩子是一个 Agent ,她在状态 st (即,她走的每一步)采取了行为 at ( 步行的姿势 ),移动到下一个 st+1 。当她完成每一个任务的时,孩子会获得奖励 Reward(比如,一些糖果),她以此来估计价值 v(st +1) ,然后她更新她的经验,即记忆矩阵,更新方式见上图。Agent 不断地练习,重复1-4步,直至学会走路的方法 Policy 为止,这里的 Policy 指的是记忆矩阵 W(a,s)。
1.4 Q-learning 的核心公式
把上文提到的记忆矩阵 W(a,s) 用 Q
动作效用函数
action-utility function 替换。Q 用于
评价在特定状态下采取某个动作的优劣
,可以将之理解为智能体 Agent 的大脑,常称为 Q-table ,一般是个矩阵,用 tensorflow.js 的代码试下:
tf.zeros([3,4]).print(); /* 3代表3种state,4代表4种action,Q-table 如下: Tensor [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]] */
算法就是要训练出最终的 Q-table ,最终的 Q-table 有可能长下面这样:
/* 代表了各个state及action 对应的“价值”: Tensor [[0, 0.2, 12.3, 0], [2.1, 0, 4.5, 0], [0, 12, 1, 0.5]] */
我们把上文更新记忆矩阵的公式细化下,主要增加
学习率
learning rate 及
折扣因子
discount factor:
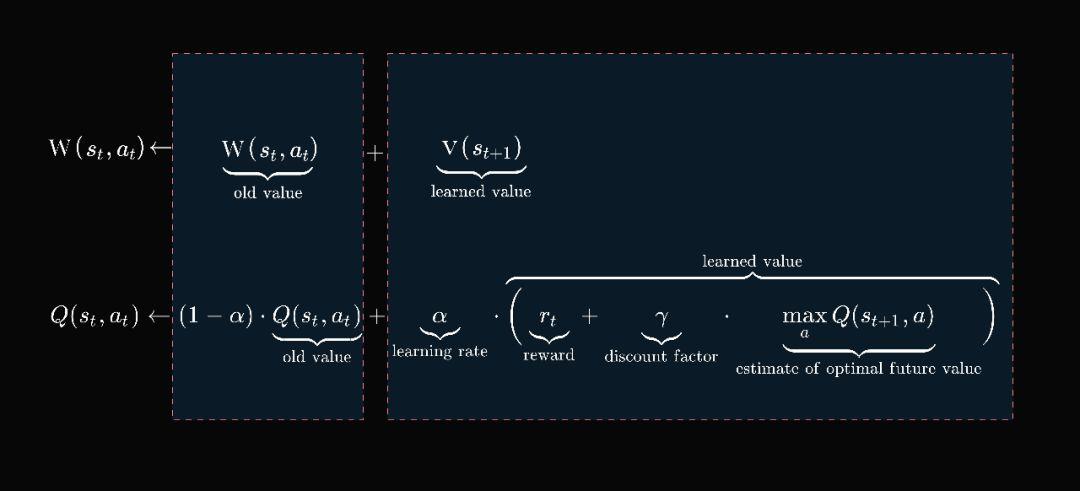
其中,
学习速率越大,保留之前训练的效果就越少;学习率=0,不考虑之前的训练结果;折扣因子越大,更多地考虑远期收益;折扣因子越小,更多地考虑眼前的收益
。
1.5 应用举例
我们结合示例,看下 Q-learning 适合运用的场景,有3种常见的:
1)1维空间:
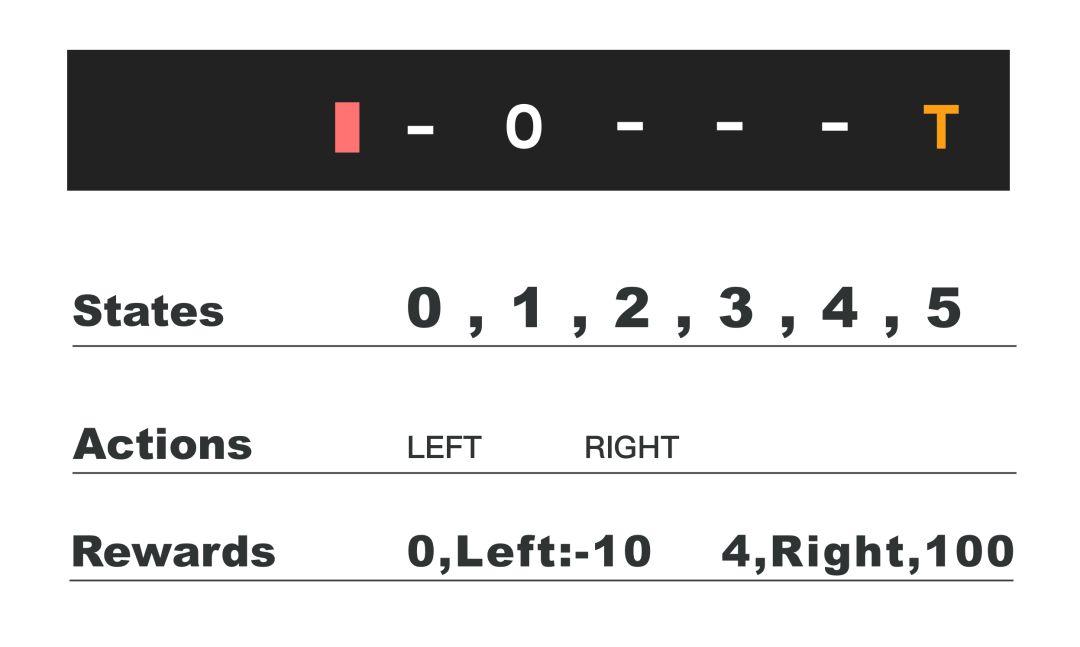
0代表智能体,它只能向左或向右移动,最右边是宝藏的位置,最左边是陷井,于是states有6个,分别是智能体可能出现的位置,如果智能体在state为0,采取 action 为 Left 将落入陷阱,我们设置收益为-10,如果智能体在state 为4的位置,采取action 为Right ,则获得宝藏,收益为100,这是把1维空间的问题对应为 Q-learning 算法的过程。其他代码详见莫烦的教程。
2)房间:
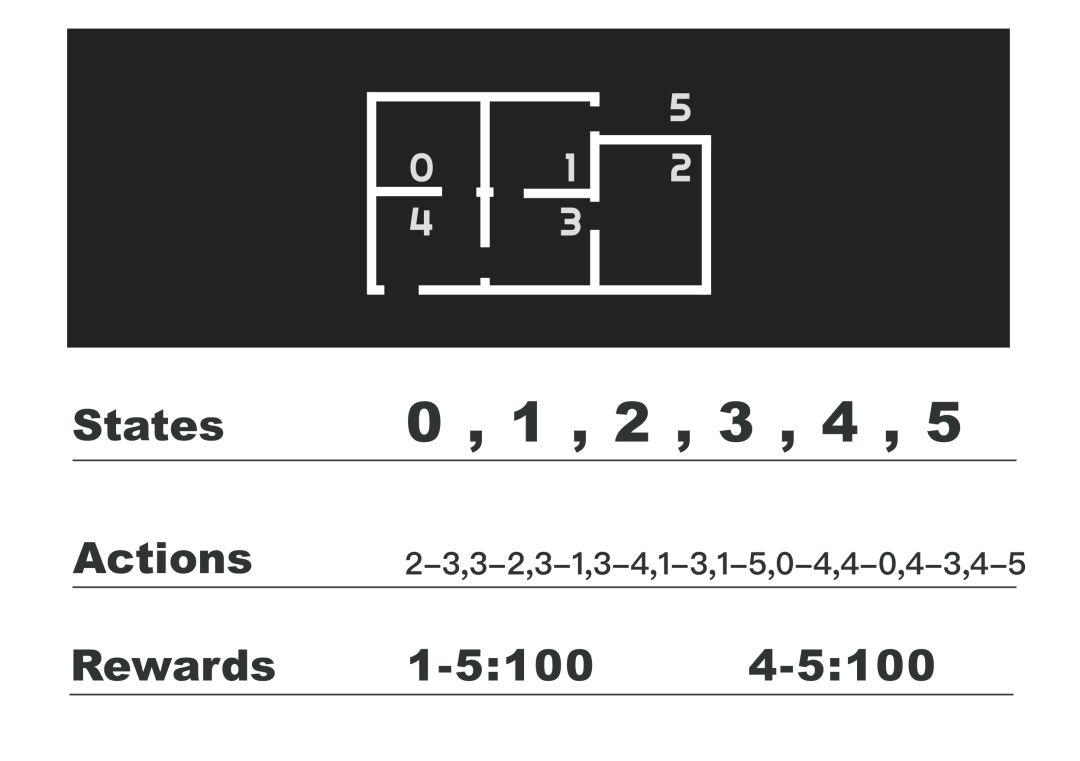
老外举的例子,state代表智能体在哪个房间,action代表从一个房间达到另一个房间的动作,接下来定义收益,例如在房间1的时候,采取移动到房间5的动作,则收益为100。更多详见网上相关文章。
3)2维迷宫:
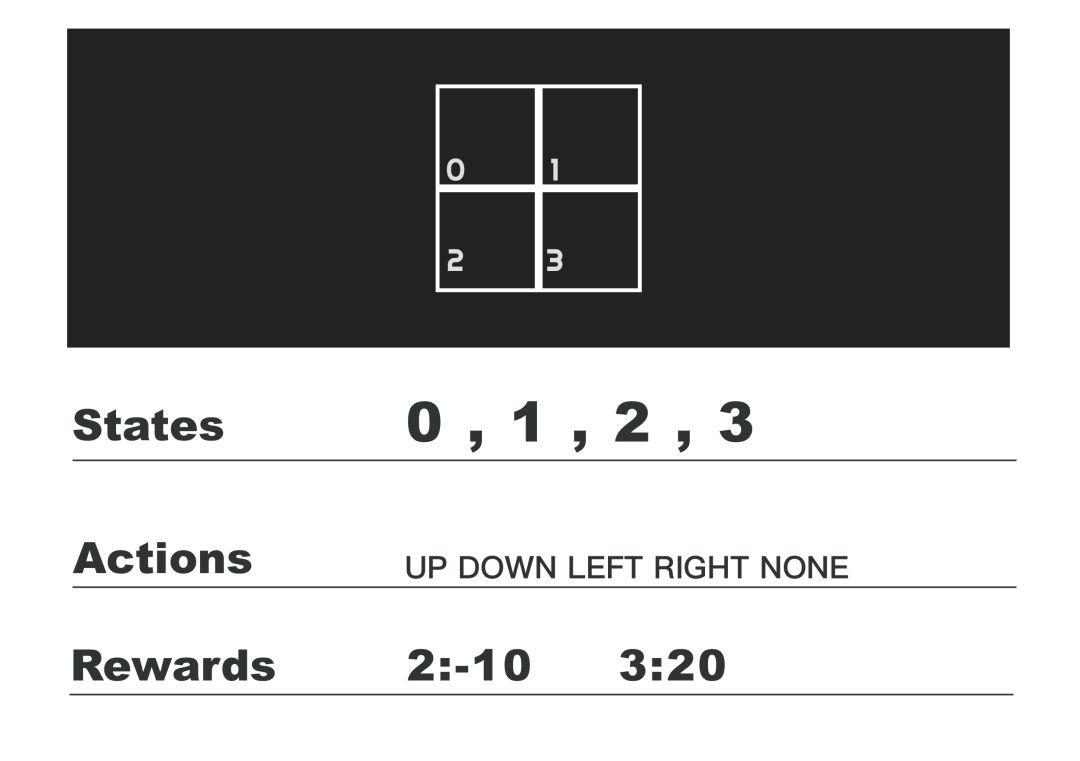
这类的例子是用的最多的,state代表智能体在哪个方块内,action 可以是向上、向下、向左、向右、停留,state为3时,掉入陷阱,收益为-10,state为4时,获得奖励,收益为20,下文会以此为例子进行代码示例。
1.6 Deep Q Network
2013年 DeepMind 在 NIPS 上发表 Playing Atari with Deep Reinforcement Learning 一文,提出了 DQN(
Deep Q Network
)算法,实现端到端学习玩 Atari 游戏,即只有像素输入,看着屏幕玩游戏。卷积神经网络 CNN 被用于替代上文中提到的 Q 函数,CNN 输出层的神经元个数等于所有允许的动作数。
卷积神经网络或者全连接神经网络都可以用来压缩状态空间,构造近似的 Q 函数 Q(s, a)
。关于 Deep Q Network ,留待下一篇再详细展开。
2
动手编程
继续以迷宫为例,位置2为陷阱,位置3为奖励所在。
2.1 初始化训练参数
const GAMMA = 0.7, //折扣因子 EPISODES_MAX = 100, //最大回合数 ALPHA = 0.1; //学习率
2.2 定义actions,states,rewards
const actions_array = [0, 1, 2, 3, 4], actions_labels = ['UP', 'DOWN', 'LEFT', 'RIGHT', 'NONE'], actions_byState = [ [1, 3, 4], [1, 2, 4], [0, 3, 4], [0, 2, 4] ], states_array = [0, 1, 2, 3], rewards_array = [0, 0, -10, 20]; var actions = new Actions(actions_labels, actions_array, actions_byState); var states = new States(states_array, rewards_array);
2.2 初始化 Q-table 矩阵
var Q = new QTable(states_array.length, actions_array.length);
2.2 选择起始 state
var state = states.randomChooseOne(); //随机选取一个state
2.3 选择当前 state 下的一个可能 action
var action = actions.randomChooseOne(state);
目前选择 action 的策略是
随机
的, Q-learning 并非每次迭代都沿当前 Q 值最高的路径前进。
2.4 换移到下一个state ( s’ )
var state_n = states.nextState(action, state);
2.5 使用 Bellman Equation ,更新 Q-table
var reward = states.getReward(state_n); var actions_n = actions.actionsByState[state_n]; var futureValue = Q.getFutureValue(state_n, actions_n); Q.update(state, action, reward, futureValue);
其中,学习率代码里用 ALPHA 表示,折扣因子用 GAMMA 表示。learned value 代码为:
learnedValue=reward+GAMMA*max(qs)
用于更新 Q-table 的值:
var value = (1 - ALPHA) * q_table.get(state, action) + ALPHA * (reward + GAMMA * tf.tensor1d(qs).max().dataSync()[0]);
可以对照下公式:

2.6 将下一个 state 作为当前 state
state = state_n; action = actions.randomChooseOne(state);
2.7 重复2.3-2.6步骤
var episode = 0; while (state != 3 || episode < EPISODES_MAX) { … Q.update(state, action, reward, futureValue); … episode++; };
3
反复实验
主要是修改 ALPHA 及 GAMMA ,还有修改迷宫的维度,增加各种陷阱及奖励等类型,此部分不一一展开,请根据自身情况进行实验。
4
应用场景
强化学习用于游戏比较多,因为我们可以枚举清楚 state 及 action ,reward 也可以量化清楚。太过复杂的场景或维度较多的数据,我们可以尝试用 Deep Q Network 来解决。回到平面设计问题,我们可以尝试配色方案的生成,布局排版数据的生成。
鉴于篇幅,第3-4部分可以在
知识星球
交流。完整代码,可
留言后
获取。
相关资料推荐
:
https://github.com/SarvagyaVaish/FlappyBirdRL/blob/master/README.md
https://planktonfun.github.io/q-learning-js
写此文的感想
:
一开始维护此公众号仅仅是兴趣使然,记录个人的一些经验,到现在把她当产品来考虑,这个得回到 mixlab 同时维护的知乎专栏:《
人工智能+设计修炼指南
》的出发点:
“人工智能+设计”本身是个非常综合性的领域,要求对设计有相关的积累及认识,对人工智能的技术有足够深入的实践,因而需要至少积累2个领域的知识:设计+人工智能。要求掌握的技能包括而不限于:机器学习、深度学习、强化学习、编程、产品设计、用户体验设计等。 修炼指南是一个设计+技术的思维体系,同时是我的学习记录,及对2个领域融合的经验。
mixlab 关于“设计+技术的思维体系”的思考:
一万小时的积累,需要平时的刻意练习,学无止尽,终身学习。
定期的线下交流活动,我们面对面用“设计+编程+人工智能”,共同探索新方向。
一篇文章尽量涉及2个以上不同领域的内容,跨界思考之间的关联性。
近期活动: