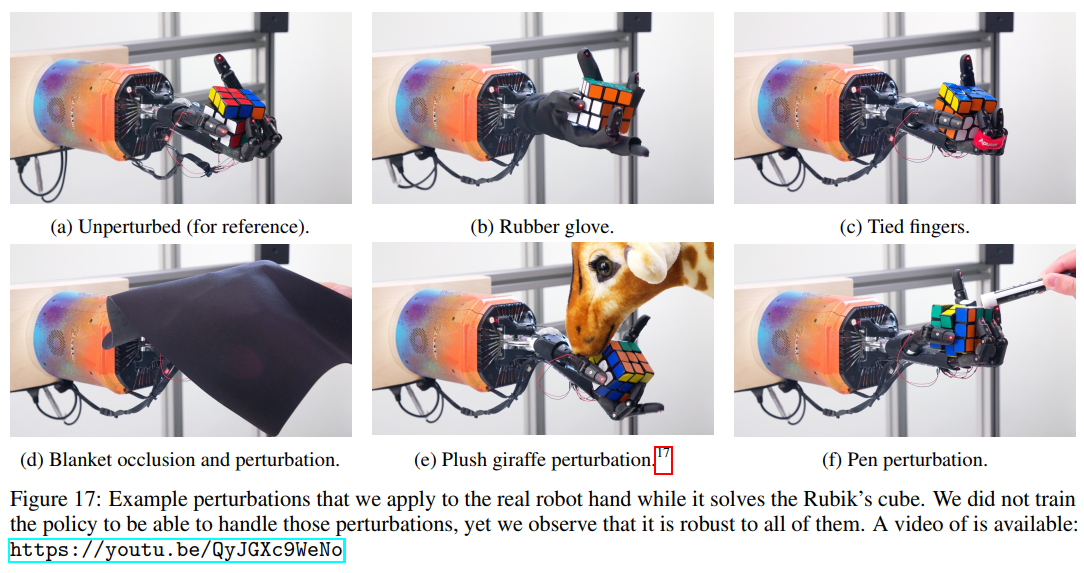
基于强化学习的五指灵巧手操作
- 1. 引言
- 2. 论文解读
- 2.1 背景
- 2.2 论文中所用到的强化学习方法
- 2.3 实验任务和系统
- 2.4 仿真到实物的迁移
- 2.5 分布式RL训练——从状态中学到控制策略
- 2.6 ResNet——从视觉中得到状态估计
- 2.7 实验结果
- 3. 总结
1. 引言
本文介绍一篇OpenAI团队出品,2018年挂在arXiv上,2020年被机器人领域顶刊 The International Journal of Robotics Research 接收的文章:Learning dexterous in-hand manipulation
论文传送门:Learning dexterous in-hand manipulation.(这是arXiv上的版本,IJRR的版本可以自行通过谷歌学术搜索,两者在内容的顺序组织上有所不同,整体内容一致,本文按照IJRR的版本进行介绍)
此论文中所用到的方法都是其他学者提出的强化学习方法,此论文最大的亮点是真正地去解决机器人操作的强化学习sim2real问题,采用了仿真和真实情况的标定,仿真训练的随机化等技巧来解决这一问题。且对sim2real的很多问题进行了讨论。最终用强化学习方法解决了传统控制方法(非学习类的方法)无法解决的操作问题。
虽然此论文没有原创性的方法,但是能够把当时的sota方法融合起来,扎扎实实地把强化学习算法用在实际机械手上,光这一点就很值得尊敬了。
2. 论文解读
2.1 背景
Shadow Dexterous Hand (ShadowRobot, 2005) 是一款以人手灵巧性为设计目标的机械手,它有5个手指,共24个自由度。此机械手从2005年开始在市场上销售,但是并没有被广泛地使用,因为其控制系统过于复杂。有的学者在仿真中实现了 in-hand manipulation,但没有尝试迁移到实物;有的学者直接在实物上训练,但由于实物训练的低效性和高成本性,学到的行为非常有限。
本文的工作是在仿真环境下训练机械手,并在实物上进行了部署验证,尽管仿真环境和实物环境有很大差别,但是作者通过广泛地随机化(extensive randomizations)、记忆增强控制策略(memory augmented control polices)、分布式强化学习训练(training at large scale with
distributed reinforcement learning)的方式来实现仿真到真实环境的迁移。
真实五指机械手操作翻转物体的过程如下图所示:

2.2 论文中所用到的强化学习方法
首先讲述本文中的符号约定:状态空间 S \mathcal{S} S,动作空间 A \mathcal{A} A,初始状态的分布 p ( s 0 ) p\left(s_{0}\right) p(s0),奖励函数 r : S × A → R r: \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R} r:S×A→R,转移概率 p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} \mid s_{t}, a_{t}\right) p(st+1∣st,at),折扣因子 γ ∈ [ 0 , 1 ] \gamma \in[0,1] γ∈[0,1],回报 R t = ∑ i = t ∞ γ i − t r i R_{t}=\sum_{i=t}^{\infty} \gamma^{i-t} r_{i} Rt=∑i=t∞γi−tri,动作价值函数 Q π ( s t , a t ) = E [ R t ∣ s t , a t ] Q^{\pi}\left(s_{t}, a_{t}\right)=\mathbb{E}\left[R_{t} \mid s_{t}, a_{t}\right] Qπ(st,at)=E[Rt∣st,at],状态价值函数 V π ( s t ) = E [ R t ∣ s t ] V^{\pi}\left(s_{t}\right)=\mathbb{E}\left[R_{t} \mid s_{t}\right] Vπ(st)=E[Rt∣st],优势函数 A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) A^{\pi}\left(s_{t}, a_{t}\right)=Q^{\pi}\left(s_{t}, a_{t}\right)-V^{\pi}\left(s_{t}\right) Aπ(st,at)=Qπ(st,at)−Vπ(st)
强化学习优化目标是最大化初始回报期望 E [ R 0 ∣ s 0 ] \mathbb{E}\left[R_{0} \mid s_{0}\right] E[R0∣s0]
本文中用到的强化学习技术有三个:广义优势估计器(Generalized Advantage Estimator,GAE),邻近策略优化(Proximal policy optimization, PPO),域随机化(domain randomization)
接下来介绍GAE技术。因为在强化学习中,状态价值函数 V ( s t ) V(s_t) V(st)通常用神经网络来估计,所以对于一个状态价值 V ( s t ) V(s_t) V(st),我们需要知道它的“真值”,而“真值”通常用 k k k步回报来估计( k = 1 k=1 k=1是最常见的),即:
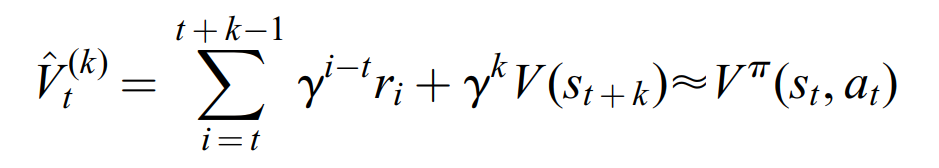
其中
V
^
t
(
k
)
\hat{V}_{t}^{(k)}
V^t(k)称为
k
k
k步回报估计器(k-step return estimator),
k
k
k是用来平衡偏差和方差的,
k
k
k越大,偏差小方差大,反之,偏差大方差小。
如果用一个式子将所有的 V ^ t ( k ) ( k = 1 , … , N ) \hat{V}_{t}^{(k)} (k=1,\dots,N) V^t(k)(k=1,…,N)都给融入进去,就能进一步地得到方差与偏差之间的平衡,从而得到更好的估计(这也是 λ \lambda λ return 的思想,想要了解 λ \lambda λ return与GAE之间的来龙去脉,可以参考:强化学习中值函数与优势函数的估计方法),即GAE技术:
V ^ t G A E = ( 1 − λ ) ∑ k > 0 λ k − 1 V ^ t ( k ) ≈ V π ( s t , a t ) \hat{V}_{t}^{\mathrm{GAE}}=(1-\lambda) \sum_{k>0} \lambda^{k-1} \hat{V}_{t}^{(k)} \approx V^{\pi}\left(s_{t}, a_{t}\right) V^tGAE=(1−λ)k>0∑λk−1V^t(k)≈Vπ(st,at)
A ^ t G A E = V ^ t G A E − V ( s t ) ≈ A π ( s t , a t ) \hat{A}_{t}^{\mathrm{GAE}}=\hat{V}_{t}^{\mathrm{GAE}}-V\left(s_{t}\right) \approx A^{\pi}\left(s_{t}, a_{t}\right) A^tGAE=V^tGAE−V(st)≈Aπ(st,at)
用 V ^ t G A E \hat{V}_{t}^{\mathrm{GAE}} V^tGAE和 A ^ t G A E \hat{A}_{t}^{\mathrm{GAE}} A^tGAE来估计动作的价值和优势,常常会得到更好的效果。
接下来介绍PPO算法。PPO算法是最流行的on-policy算法之一,此算法同时优化随机策略和值函数的估计器。PPO算法的策略优化目标为最大化目标函数 L P P O L_{PPO} LPPO,其表达式为:
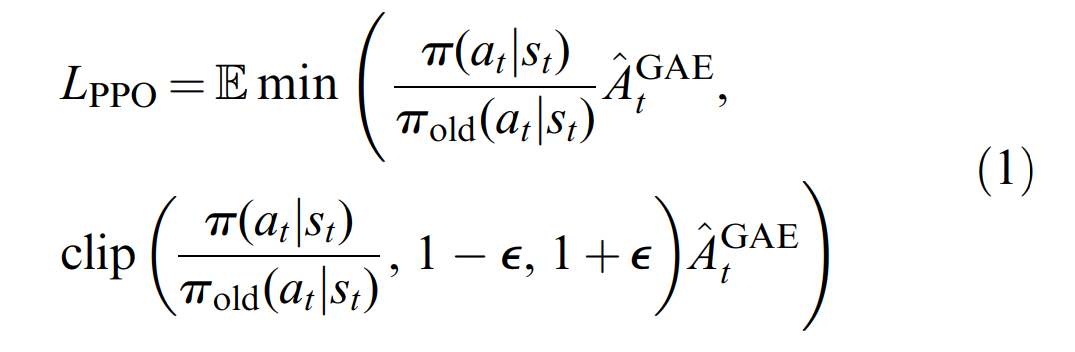
其中: π ( a t ∣ s t ) π old ( a t ∣ s t ) \frac{\pi\left(a_{t} \mid s_{t}\right)}{\pi_{\text {old }}\left(a_{t} \mid s_{t}\right)} πold (at∣st)π(at∣st) 代表当前策略 π \pi π下与生成数据的旧行为策略 π o l d \pi_{old} πold下采取同一动作 a t a_t at的概率之比,即重要性采样。 ϵ \epsilon ϵ控制clipping的量,通常为0.2。
这种函数鼓励(因为是最大化,不是最小化)策略采取优于平均水平(即:正优势)的行动,而clipping是阻止对策略进行较大的改变(通过限制在特定数据点上改变策略所能获得的收益),因为过大的策略变化会导致PPO算法的近似失效。此外,为了促进探索,通常的做法是在优化目标中加入熵奖励,以鼓励策略分布具有高熵。
PPO算法的值函数估计器是通过监督学习来训练的,估计器是用神经网络(通常就是最简单的MLP网络),估计器的预测值为 V ( s t ) V(s_t) V(st),估计器的真值为 V ^ t G A E \hat{V}_{t}^{\mathrm{GAE}} V^tGAE,loss函数用常用的MSE loss即可。
关于域随机化的论文可以参考:Domain randomization for transferring deep neural networks from simulation to the real world,它的主要思想是通过对仿真环境的各个方面大量地随机化,使得仿真迁移到实物时能有较好的效果。
2.3 实验任务和系统
本文的实验任务:将物体放在机械手的手掌上,然后目标是使物体的姿态与期望姿态一致,一旦目标达成,就切换到下一新目标,直到物体从手掌上滑落。实验中尝试了两种物体:方块和八棱柱。
下面首先介绍实物硬件系统,再介绍仿真系统。
硬件系统设置包括一个Shadow Dexterous Hand,一个 PhaseSpace 跟踪系统,以及一个RGB视觉摄像机系统,如下图所示:

Shadow Dexterous Hand 是由20对肌腱驱动的24个自由度的机械手,其中16个自由度是独立控制,剩下的8个关节(自由度)是由4对耦合关节控制。
PhaseSpace 跟踪系统 是用来定位指尖,执行校准程序,并作为基于RGB图像的目标跟踪的ground truth。
RGB 摄像机是为了估计机械手的姿态。当然PhaseSpace 跟踪系统也能估计姿态,而这里用三个Basler RGB 相机来做基于视觉的姿态估计是为了与PhaseSpace 进行对比,后来作者发现仅用RGB 摄像机的效果只比用PhaseSpace 跟踪系统差一点点。
对于机械手的控制方式,在high-level的控制器中,是使用基于Python的神经网络策略,在GPU上运行。每隔80毫秒,它就会查询PhaseSpace传感器信息,然后用神经网络进行推理以获得动作,这大约需要25毫秒。策略输出一个动作,该动作指定相对于当前关节位置的位置变化。然后它将操作发送给low-level控制器;在low-level的控制器中,是作为一个独立的进程用C++实现,该控制器接收high-level给的相对动作,将其转换为关节的绝对角度并将其固定到合理范围(不能超过关节限位角),然后将动作的每个分量作为PD控制器的目标,每5毫秒,PD控制器查询Shadow Hand关节角度传感器,然后尝试达到其所需位置。
由于此机械手用到了26个霍尔效应传感器,故还用PhaseSpace系统进行了关节传感器的校准,详细过程不再展开。
接下来来看仿真环境的搭建,整个仿真环境都在mujoco引擎下搭建,用到了Unity渲染,效果图如下图所示:

此仿真环境的状态空间为60维,包括:所有关节的角度和速度,物体的位置、姿态、以及其线速度和角速度。物体的初始状态是将物体以随机姿态放置在手掌上,然后执行100次随机动作后的状态(如果在此期间物体掉落,则重新初始化,不算在强化学习的整个训练轨迹中)。
目标设置:用四元数来表示物体的期望姿态,容许误差为0.4rad。
动作空间为20维,action为手部关节的角度(正如前文所述,驱动器是20对肌腱)
在时间步t时的奖励函数为: r t = d t − d t + 1 r_t=d_t-d_{t+1} rt=dt−dt+1,其中 d t d_t dt是在transition之前的期望物体姿态与当前物体姿态之间的旋转角度,而 d t + 1 d_{t+1} dt+1是在transition之后的期望物体姿态与当前物体姿态之间的旋转角度。当在容许误差0.4rad的范围内完成了目标时,会获得额外奖励 r = 5 r=5 r=5,当物体从手中掉落时,会获得额外奖励 r = − 20 r=-20 r=−20。从 r t r_t rt的形式可以看到,这样的奖励是引导机械手逐步地缩短与期望姿态的“距离”,因为 r t r_t rt 大于0,说明 d t + 1 d_{t+1} dt+1比 d t d_t dt小,那么 t + 1 t+1 t+1时刻就比 t t t时刻更靠近目标姿态。
一个episode结束的标志:策略执行了50个连续的目标,或者在8秒内未完成当前目标,或物体掉落。
为了让仿真能够迁移到实物,作者还进行了模型标定,使得mujoco的xml模型和物理设备能够更好地匹配。具体做法是:在物理机器人上记录一个 trajectory,然后对参数进行优化,最小化 simulated trajectory与real trajectory之间的误差,这共牵涉到264个需要调整的值。(非常庞大的调参工程)
2.4 仿真到实物的迁移
即使是进行了非常复杂的模型标定,在sim2real的过程中仍存在reality gap。比如:在仿真环境中是用力矩控制关节,但实际上是用肌腱驱动器控制关节运动;在仿真环境中是使用固体接触模型,但实际上应该使用可形变物体的接触模型。正是因为这些gap的存在,使得在仿真环境中训练得到的模型不太可能在实物上有很好的效果。
目前遇到的窘境是:强化学习需要百万级别的训练样本,我们不可能直接在实物上去直接获得这些样本;而如果用仿真来训练,然后迁移到实物上,reality gap的存在使得实物效果并不好。
作者想到的一种解决方案是:谨慎地选择传感模式以及对仿真环境大量地随机化。这样的做法可以防止策略过拟合某一种特定仿真场景,从而更可能地迁移到实物。
在对环境观测部分中,即使 Shadow Dexterous Hand 有内置的传感器,作者认为也不应该作为强化学习的状态输入,因为它存在很多依赖于状态的噪声,在仿真环境中难以模拟。因此作者仅用纯视觉的方式作为强化学习的状态输入,即:观测指尖用PhaseSpace markers ,观测物体姿态用PhaseSpace markers 或者 the vision-based pose estimator。
正如前文所述,想要实现sim2real,域随机化是很重要的。当然,随机化也不能任意随机,作者的随机都是在前述标定的合理数值附近进行随机,且对高不确定性的东西随机(比如驱动器参数),而不对低不确定性的东西随机(比如物体尺寸)。文中详细地讨论了各个随机的参数,以及如此做的目的,这里就不展开了,下图是在仿真环境中的随机效果图:

2.5 分布式RL训练——从状态中学到控制策略
为了能够实现sim2real,对环境做了大量的随机化,正是因为策略需要处理对同一问题的大量变体问题,所以作者采用分布式RL系统来使策略能够训练地更好。
整体的RL方法为PPO方法,下面介绍策略网络与价值网络的结构。
策略网络(Policy network):LSTM网络(因为变体问题较多,需要具备记忆功能)和用ReLU激活函数的全连接网络,如下图左侧网络结构所示。注意PPO的输出为一个动作分布。
价值网络(Value network)与策略网络结构相同,如下图右侧网络结构所示。
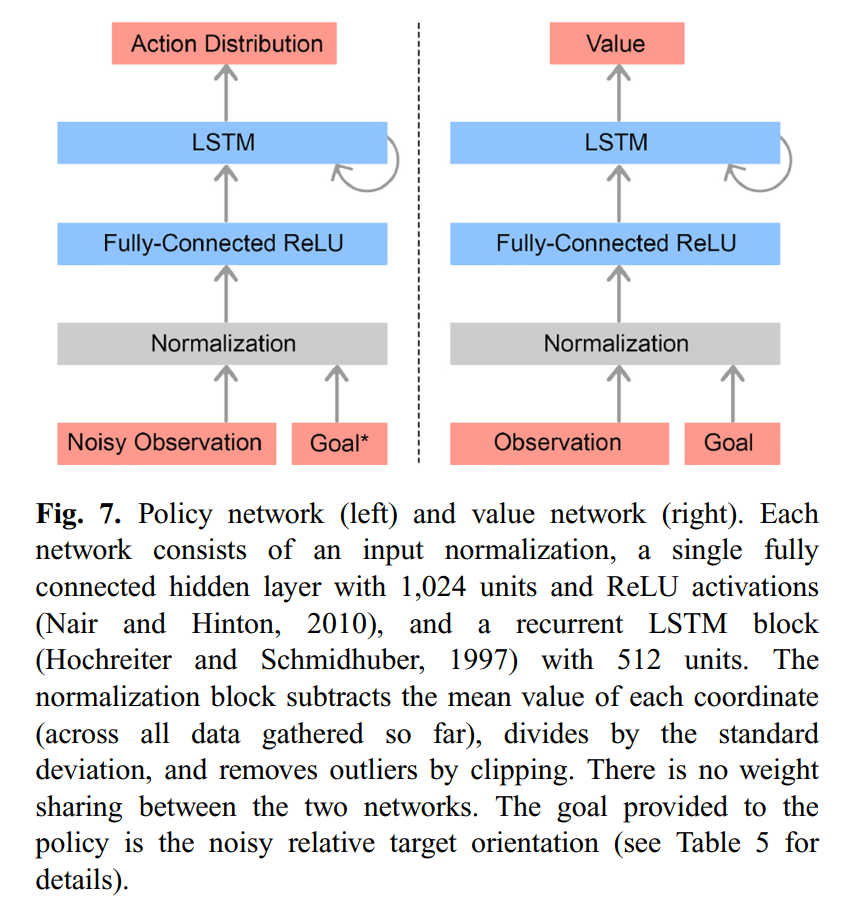
这两个网络的输入如下表所示:
因为价值网络只在训练中用到,所以作者使用了非对称Actor–Critic的方法(Asymmetric Actor–Critic,它利用了价值网络可以获得真实机器人系统无法获得的信息这一事实,可以参考论文Asymmetric actor critic for image-based robot learning)
分布式训练结果如下图所示:
2.6 ResNet——从视觉中得到状态估计
关于物体的位置和姿态,则是使用纯视觉的方法来估计。具体而言是,用三个不同视角的RGB摄像头再加上CNN网络,ResNet结构等来提取。视觉网络结构如下图所示:
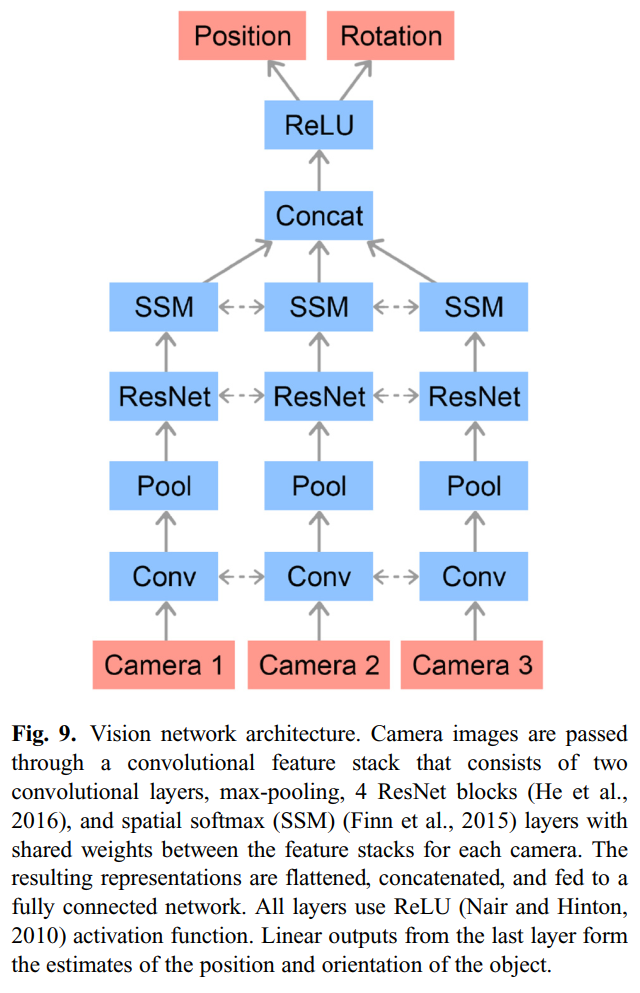
视觉网络结构的网络参数为:

既然是视觉的神经网络模型,那么自然是采用监督学习的方式进行训练,即最小化模型预测的物体状态和实际物体状态之间的最小均方误差(MSE Loss)。
注意,RGB摄像机也是完全在仿真环境下搭建,整个视觉神经网络(即:vision-based pose estimator)也都是用仿真数据训练得到的,后面直接将仿真训练得到的vision-based pose estimator用于实物,把实际的图像作为输入,得到物体位置和姿态。(真正意义上的sim2real,OpenAI真滴强)
2.7 实验结果
在仿真环境中训练好后,就部署在实际的机械手上,操作对象有两个——方块和八棱柱。当然,总体趋势是,尽管随机化和校准缩小了仿真和现实的gap,但它仍然存在,在真实系统上的性能比在模拟中更差。而且所谓的校准,如果一旦出现机器人损坏,那么校准就要重新开始,这是非常繁琐的工作,而OpenAI在实验中确实遭遇到了机械手频繁损坏的情况。
为了成功地实现仿真到真实实验的迁移,作者进行了一项关于randomizations 和 policies with memory capabilities 的重要性的消融实验。然后作者考虑了所提方法的样本复杂度。最后作者验证了所提的vision pose estimator在仅用图像的情况下就能获得很好的性能。
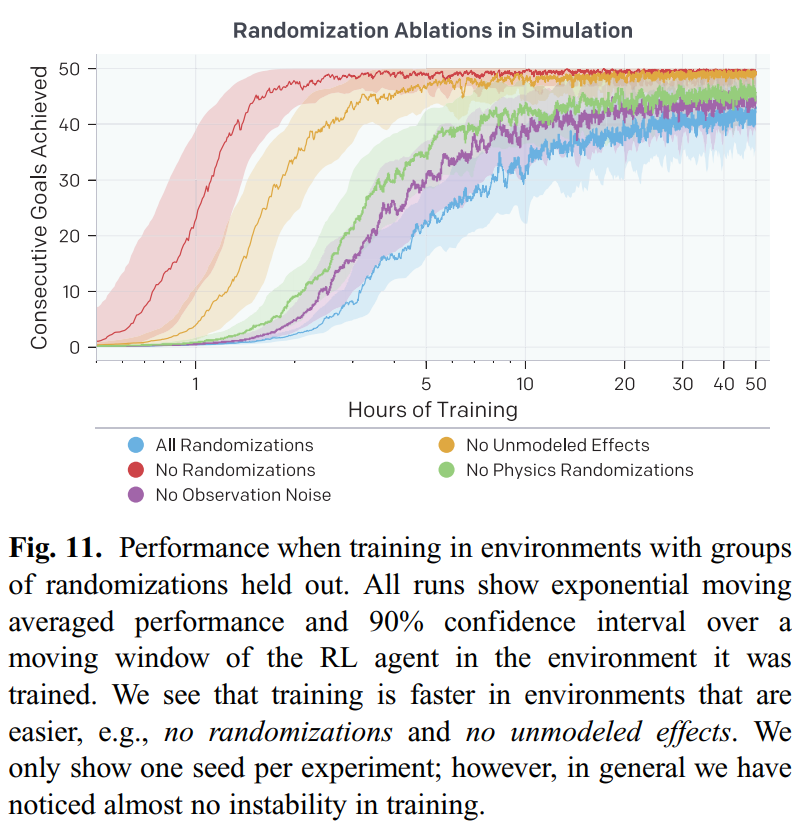
我们来看关于randomizations的消融实验。作者在具有各种随机化的环境中训练了五种独立的RL策略:所有都随机化(基线化),没有观测噪声,没有未建模的影响,没有物理随机化,没有随机化(基本模拟器,即没有域随机化)。(注意,这些具体的随机化参数我并没有讲述,感兴趣的朋友可以直接参考原论文)
这五种独立的RL策略在仿真环境中的训练曲线如下图所示,可以看到 all randomizations 和 no observation noise 收敛最慢,no randomizations 收敛最快。但是迁移到真实环境中就发现,all randomizations 和 no observation noise 的效果还不错,而no randomizations的效果就很差了。
再来看关于policies with memory capabilities的消融实验。作者对策略网络和价值网络做了三种尝试,如下表所示,其中FF代表前向神经网络(即全连接网络),LSTM代表长短期记忆网络。可以看到,策略网络和价值网络都是LSTM时,效果最好。此实验说明了有一定的记忆能力对于实际的策略来说,是有帮助的。

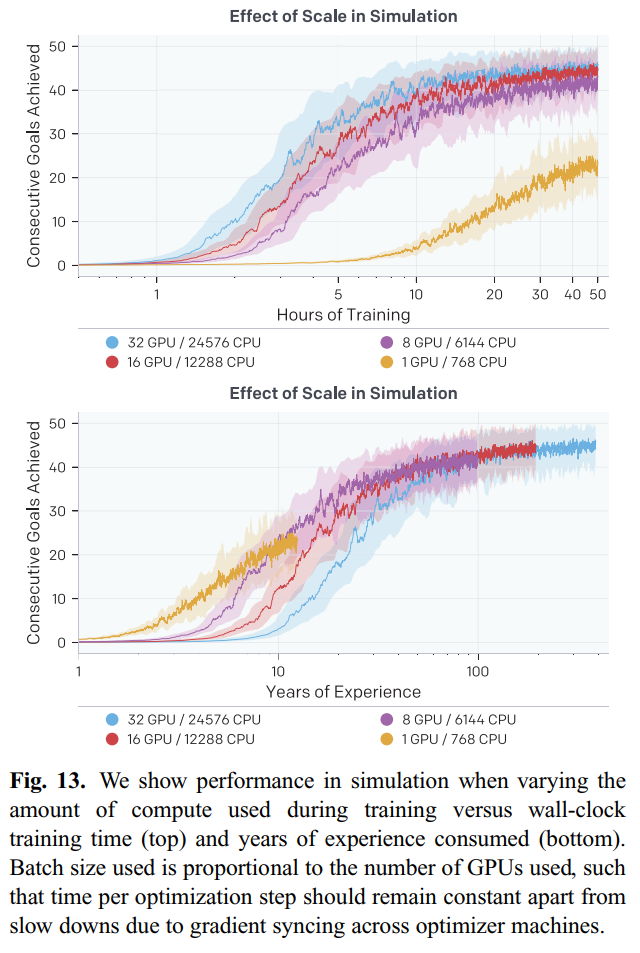
对于所提方法的样本复杂度,作者尝试了用不同计算资源进行训练,如下图所示,发现从1GPU到8GPU训练速度提升明显,但是从8到16再到32,提升就不是很明显了,这种做法的收益并不高。
对于所提的vision pose estimator,其在Unity渲染器下训练的,然后在Unity下、Mujoco下(可以看成sim2sim的迁移)、以及真实图像(可以看成sim2real的迁移)中进行验证,其验证结果如下表所示:
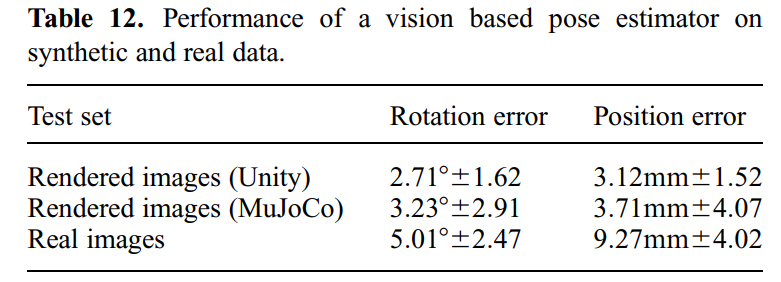
可以看到sim2sim的迁移还是很成功的,但是sim2real就有很大的误差了,这不仅是因为仿真和现实的gap,还因为噪音、遮挡、不完美的标记放置、延迟传感器读数等导致的现实的ground truth很难获得。尽管如此,基于视觉的策略在实际机械手上还是表现地不错。
3. 总结
对于此论文中,真实机械手操作方块的效果视频,可以看论文的Supplementary material部分,视频传在YouTube平台上。
本文中用到的强化学习方法有:广义优势估计器、PPO算法、域随机化。采用ResNet等神经网络模型,用纯视觉感知的方式作为物体位置和姿态的估计,得到不错的效果。文章对于sim2real的很多细节问题都进行了讨论,最终实现了五指灵巧手操作方块和八棱柱,解决了非学习类方法(传统控制方法)无法解决的操作问题。
整个系统地架构如下图所示:
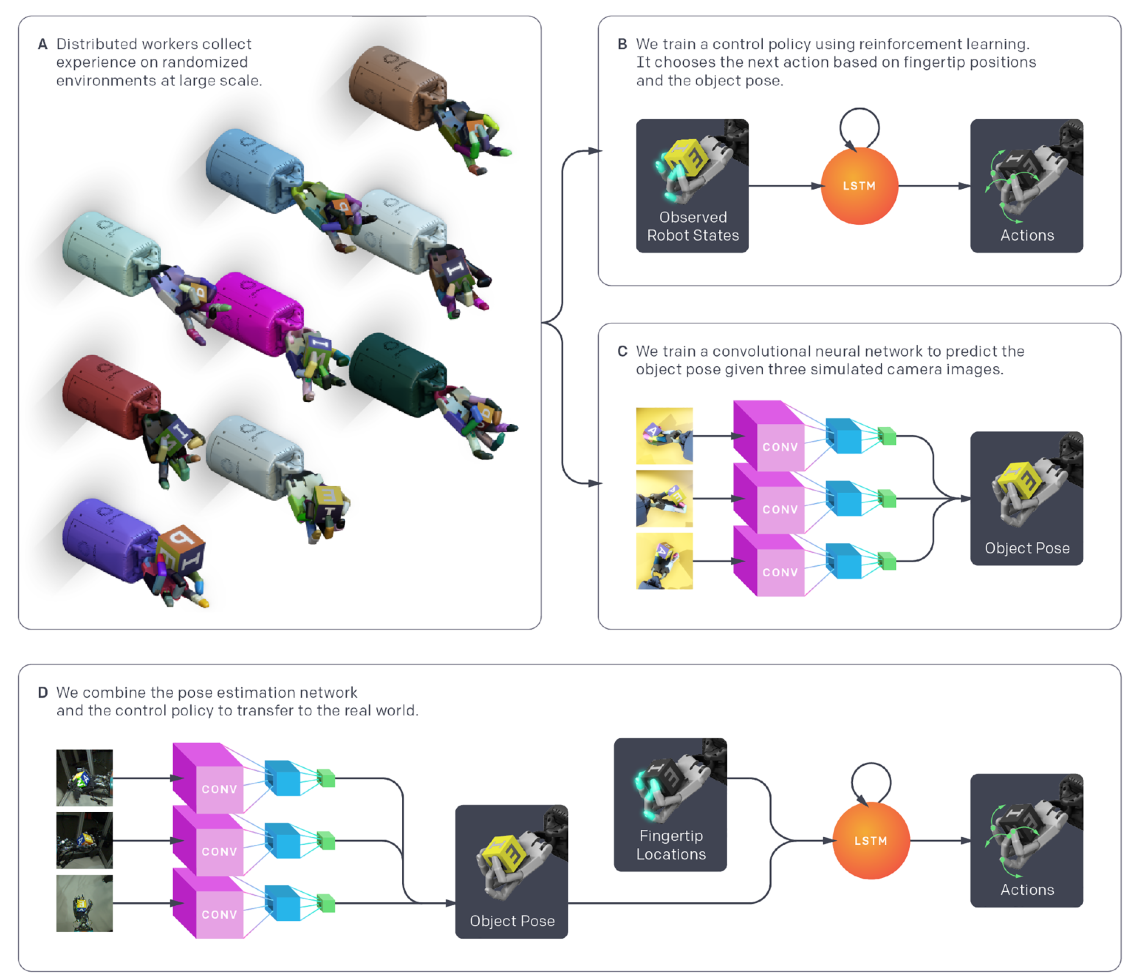
A. 作者使用随机参数和外观的大分布模拟来收集控制策略和 vision-based pose estimator 的数据。
B. 从分布式模拟中,控制策略接收观察到的机器人状态和奖励,并使用RNN和RL方法,将观察映射为动作。
C. vision-based pose estimator 从分布式仿真中收集的场景,并使用卷积神经网络(CNN)从图像中学习预测目标的姿态,CNN网络与控制策略是分开训练的。
D. 为迁移到现实世界中,作者用三个真实相机的图片作为CNN网络的输入,从而预测物体姿态,使用3维动作捕捉系统测量机器人的指尖位置,最后用这两种控制策略产生一个实际机器人的动作。