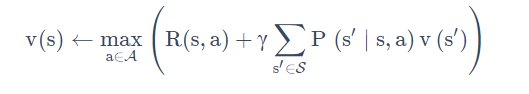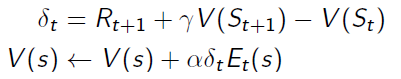1. 强化学习
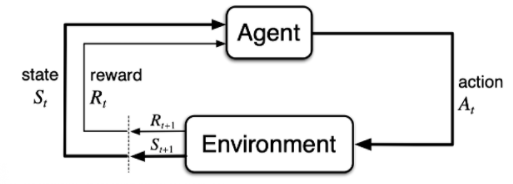
强化学习的两大主体:agent和environment- 强化学习讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment)里面去极大化它能获得的奖励。
- 当前的 agent 去跟环境交互,你就会得到一堆观测。你可以把每一个观测看成一个
轨迹(trajectory).一场游戏叫做一个episode(回合)或者trial(试验)。 - 有效动作的集合经常被称为
动作空间(action space),动作空间分为离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces)。 - 对于一个强化学习 agent,它可能有一个或多个如下的组成成分:
- 首先 agent 有一个
策略函数(policy function),agent 会用这个函数来选取下一步的动作。 - 然后它也可能生成一个
价值函数(value function)。我们用价值函数来对当前状态进行估价,它就是说你进入现在这个状态,可以对你后面的收益带来多大的影响。当这个价值函数大的时候,说明你进入这个状态越有利。 - 另外一个组成成分是
模型(model)。模型表示了 agent 对这个环境的状态进行了理解,它决定了这个世界是如何进行的。它由两个部分组成:概率和奖励函数。
- 强化学习中,
探索和利用是两个很核心的问题,如何平衡两者的关系非常重要
2. 序列决策过程简介
- 历史是观测(observation)、行为、奖励的序列:
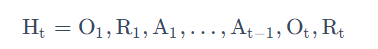
你可以把整个游戏的状态看成关于这个历史的函数:
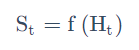
- 环境有自己的函数 S t e = f e ( H t ) S_{t}^{e}=f^{e}\left(H_{t}\right) Ste=fe(Ht)来更新状态,在 agent 的内部也有一个函数 S t a = f a ( H t ) S_{t}^{a}=f^{a}\left(H_{t}\right) Sta=fa(Ht)来更新状态。
- 当 agent 的状态跟环境的状态等价的时候,我们就说这个环境是
full observability,在这种情况下面,强化学习通常被建模成一个 Markov decision process(MDP)的问题. - 当 agent 只能看到部分的观测,我们就称这个环境是部分可观测的
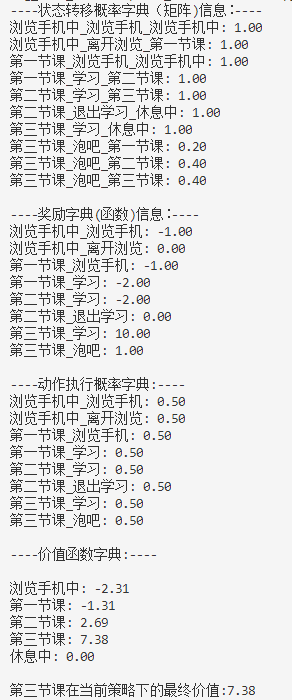
(partially observed)。在这种情况下面,强化学习通常被建模成一个 POMDP 的问题。部分可观测马尔可夫决策过程(Partially Observable Markov Decision Processes, POMDP)。POMDP 可以用一个 7 元组描述:(S,A,T,R,Ω,O,γ),其中 S 表示状态空间,为隐变量,A 为动作空间,T(s’|s,a)为状态转移概率,R为奖励函数,Ω(o∣s,a) 为观测概率,O 为观测空间,γ 为折扣系数。
3. Agents的类型
- 根据 agent 学习的东西不同,我们可以把 agent 进行归类:
基于价值的 agent(value-based agent)。
这一类 agent 显式地学习的是价值函数,
隐式地学习了它的策略。策略是从我们学到的价值函数里面推算出来的。基于价值迭代的强化学习算法有 Q-learning、 Sarsa 等基于策略的 agent(policy-based agent)。
这一类 agent 直接去学习 policy,就是说你直接给它一个状态,它就会输出这个动作的概率。
在基于策略的 agent 里面并没有去学习它的价值函数。基于策略迭代的强化学习算法有策略梯度算法等- 把 value-based 和 policy-based 结合起来就有了
Actor-Critic agent。这一类 agent 把它的策略函数和价值函数都学习了,然后通过两者的交互得到一个最佳的行为。
- agent 到底有没有学习这个环境模型来分类:
- 第一种是
model-based(有模型)RL agent,它通过学习这个状态的转移来采取动作。 - 另外一种是
model-free(免模型)RL agent,它没有去直接估计这个状态的转移,也没有得到环境的具体转移变量。它通过学习价值函数和策略函数进行决策。Model-free 的模型里面没有一个环境转移的模型。