Article
文献题目:Reasoning on Knowledge Graphs with Debate Dynamics
文献时间:2020
发表期刊:AAAI
https://github.com/m-hildebrandt/R2D2
摘要
- 我们提出了一种基于辩论动力学的知识边图自动推理新方法。主要思想是将三元组分类的任务构建为两个强化学习代理之间的辩论游戏,它们提取论点 - 知识图中的路径 - 目的是分别促进事实为真(正题)或事实为假(反题)。基于这些论点,称为法官的二元分类器决定事实是真还是假。这两个代理可以被视为稀疏的对抗性特征生成器,它们为正题或反题提供可解释的证据。与其他黑盒方法相比,这些论点使用户能够理解法官的决定。由于这项工作的重点是创建一种可解释的方法来保持具有竞争力的预测准确性,因此我们在三元组分类和链接预测任务上对我们的方法进行了基准测试。因此,我们发现我们的方法在基准数据集 FB15k-237、WN18RR 和 Hetionet 上优于几个基线。我们还进行了一项调查,发现提取的论点为用户提供了丰富的信息。
引言
- 关于现实世界的大量信息可以用实体及其关系来表示。 知识图 (KG) 以三元组 ( s , p , o ) (s, p, o) (s,p,o) 的形式存储有关世界的事实,其中 s s s (subject) 和 o o o (object) 对应于图中的节点, p p p(谓词)表示连接两者的边缘类型。 KG 中的节点代表现实世界的实体,谓词描述实体对之间的关系。
- KG 可用于不同领域的各种人工智能 (AI) 任务,例如自然语言处理中的命名实体消歧 (Han and Zhao 2010)、视觉关系检测 (Baier, Ma, and Tresp 2017) 或协同过滤 (Hildebrandt等人,2019)。大型 KG 的示例包括 Freebase (Bollacker et al. 2008) 和 YAGO (Suchanek, Kasneci, and Weikum 2007)。特别是,谷歌知识图 (Singhal 2012) 是一个著名的综合知识图谱示例,它包含超过 180 亿个事实,用于搜索、问答和各种 NLP 任务。然而,一个主要问题是,大多数现实世界的 KG 是不完整的(即缺少真实事实)或包含虚假事实。旨在解决此问题的机器学习算法尝试根据观察到的连接模式推断缺失的三元组或检测错误事实。此外,许多任务(例如问答或协同过滤)可以根据预测 KG 中的新链接来制定(例如,(Lukovnikov et al. 2017)、(Hildebrandt et al. 2018))。大多数用于 KG 推理的机器学习方法都将实体和谓词嵌入到低维向量空间中。然后可以根据这些嵌入计算三元组的合理性分数。大多数基于嵌入的方法的共同点是它们的黑盒性质,因为它对用户隐藏了促成该分数的因素。在现实世界环境中部署 KG 时,这种缺乏透明度构成了潜在的限制。机器学习社区的可解释性最近受到了关注。许多国家/地区已经制定了需要可解释算法的法律(Goodman and Flaxman 2017)。此外,与单向黑盒配置相比,可理解的机器学习方法能够构建机器和用户相互交互和相互影响的系统。
- 大多数可解释的 AI 方法可以大致分为两组:事后可解释性和集成透明度(Došilovi´c、Brˇci´c 和 Hlupi´c 2018)。 虽然事后可解释性旨在解释已经训练好的黑盒模型的结果(例如,通过逐层相关性传播(Montavon 等人,2017)),但基于透明度的集成方法要么采用内部解释机制,要么采用内部解释机制。 由于模型复杂度低(例如,线性模型),自然可以解释。 由于低复杂性和预测准确性通常是相互冲突的目标,因此通常需要在性能和可解释性之间进行权衡。 这项工作的目标是设计一种具有集成透明度的 KG 推理方法,该方法不会牺牲性能,同时还允许人在循环中。
- 在本文中,我们介绍了 R2D2(Reveal Relations using Debate Dynamics),一种基于强化学习的三元组分类新方法。受到(Irving、Christiano 和 Amodei 2018 年)中提出的通过辩论提高 AI 安全性的概念的启发,我们将三元组分类任务建模为两个代理之间的辩论,每个代理都提出支持论文的论点(三元组是真的)或反义词(三元组是假的)。基于这些论点,称为法官的二元分类器决定事实是真还是假。与大多数基于表示学习的方法相反,可以向用户显示论点,以便他们可以追溯法官的分类,并可能推翻决定或请求额外的论点。因此,R2D2 的集成透明机制不是基于低复杂度的组件,而是基于可解释特征的自动提取。虽然深度学习使手动特征工程在很大程度上变得多余,但这种优势是以产生难以解释的结果为代价的。我们的工作是尝试通过使用深度学习技术自动选择稀疏的、可解释的特征来关闭循环。这项工作的主要贡献如下。
- 据我们所知,R2D2 构成了第一个基于辩论动力学的 KG 推理模型。
- 我们针对数据集 FB15k-237 和 WN18RR 上的三元组分类对 R2D2 进行了基准测试。 我们的研究结果表明,R2D2 在准确性、PR AUC 和 ROC AUC 方面优于所有基线方法,同时更易于解释。
- 为了证明 R2D2 原则上可以用于 KG 补全,我们还评估了它在 FB15k-237 子集上的链接预测性能。 为了包含现实世界的任务,我们在 Hetionet 上使用 R2D2 来寻找基因疾病关联和药物的新目标疾病。 在 k = 3、10 的情况下,R2D2 在两个数据集上的性能优于或跟上所有基线方法的性能,例如 MRR、平均排名和 hits@k。
- 我们进行了一项调查,受访者扮演法官的角色,仅根据提取的论点对陈述的真实性进行分类。 基于多数投票,我们发现十分之九的陈述被正确分类,并且对于每个陈述,受访者的分类与 R2D2 法官的决定一致。 这些发现表明,R2D2 的论点提供了丰富的信息,并且法官与人类直觉一致。
- 本文组织如下。 我们将在下一节简要回顾 KG 和相关文献。 第 3 节描述了 R2D2 的方法。 第 4 节详细介绍了对基准数据集 FB15k-237、WN18RR 和 Hetionet 的实验研究。 特别是,我们将 R2D2 与文献中的各种方法进行了比较,并描述了我们的调查结果。 第 5 节讨论了论点的质量和未来的工作。 我们在第 6 节结束。
背景及相关工作
- 在本节中,我们简要介绍了正式环境中的 KG,并回顾了最相关的相关工作。让 E E E 表示实体集并考虑二元关系集 R R R。知识图 K G ⊂ E × R × E KG ⊂ E × R × E KG⊂E×R×E 是存储为 ( s , p , o ) (s, p, o) (s,p,o) 形式的三元组的事实集合——主语、谓语和宾语。为了指示三元组是真还是假,我们考虑二元特征函数 φ : E × R × E → { 0 , 1 } φ : E × R × E → \{ 0, 1\} φ:E×R×E→{0,1}。对于所有 ( s , p , o ) ∈ K G (s, p, o) ∈ KG (s,p,o)∈KG,我们假设 φ ( s , p , o ) = 1 φ(s, p, o) = 1 φ(s,p,o)=1(即,KG 是真实事实的集合)。然而,如果 KG 中不包含三元组,这并不意味着相应的事实是错误的,而是未知的(开放世界假设)。由于当前使用的大多数 KG 是不完整的,即它们不包含所有真实的三元组或者它们实际上包含错误的事实,因此许多规范的机器学习任务都与 KG 推理有关。 KG 推理大致可以根据以下两个任务进行分类:一是缺失三元组的推断(KG 补全或链接预测),二是预测三元组的真值(三元组分类)。虽然这些任务的不同表述通常在文献中找到(例如,完成任务可能涉及预测主体或客体实体以及一对实体之间的关系),但我们在整个工作中采用以下定义。
- 定义 1(三元组分类和 KG 完成)。 给定一个三元组 ( s , p , o ) ∈ E × R × E (s, p, o) ∈ E × R × E (s,p,o)∈E×R×E,三元组分类关注的是预测真值 φ ( s , p , o ) φ(s, p, o) φ(s,p,o)。 KG 补全是根据对象实体 o ∈ E o ∈ E o∈E 与给定的主题谓词对 ( s , p ) ∈ E × R (s, p) ∈ E × R (s,p)∈E×R 形成真正三元组的可能性来对它们进行排序的任务。
- 在整个工作中,我们假设存在反比关系。 这意味着对于任何关系 p ∈ R p ∈ R p∈R 都存在一个关系 p − 1 ∈ R p^{−1} ∈ R p−1∈R 使得 ( s , p , o ) ∈ K G (s, p, o) ∈ KG (s,p,o)∈KG 当且仅当 ( o , p − 1 , s ) ∈ K G (o, p^{−1} , s) ∈ KG (o,p−1,s)∈KG。 因此,对对象实体进行排名的限制不会导致失去一般性。
- 许多用于 KG 的机器学习方法都可以训练为在这两种设置下运行。 例如,一个形式为 f : E × R × E → [ 0 , 1 ] f : E × R × E → [0, 1] f:E×R×E→[0,1] 且 f ( s , p , o ) ≈ φ ( s , p , o ) f(s, p, o) ≈ φ(s, p, o) f(s,p,o)≈φ(s,p,o) 的三元分类器,导出由 $f(s , p, ·) : E → [0, 1],其中不同对象实体的函数值可用于产生排名。 虽然 R2D2 的架构是为三元组分类而设计的,但我们证明它原则上也可以在 KG 完成设置中工作。 第 4 节报告了这两项任务的性能。
- 表示学习是一种有效且流行的技术,是许多 KG 细化方法的基础。基本思想是将实体和关系都投影到低维向量空间中。然后将三元组的可能性建模为嵌入空间上的函数。基于表示学习的流行补全方法包括平移嵌入方法 TransE (Bordes et al. 2013) 和 TransR (Lin et al. 2015) 以及分解方法 RESCAL (Nickel, Tresp, and Kriegel 2011), DistMult ( Yang et al. 2015)、ComplEx (Trouillon et al. 2016) 和 SimplE (Kazemi and Poole 2018)。基于路径的推理方法遵循不同的理念。例如,在 (Lao, Mitchell, and Cohen 2011) 中提出的路径排名算法 (PRA) 使用加权随机游走的组合进行推断。在 (Xiong, Hoang, and Wang 2017) 中,提出了一种名为 DeepPath 的基于强化学习的路径搜索方法,其中代理选择实体对之间的关系路径。最近,与我们的工作更相关的多跳推理方法 MINERVA 在 (Das et al. 2018) 中被提出。该论文中的基本思想是向代理显示查询主题和谓词,并让他们执行策略引导步行到正确的对象实体。 MINERVA 产生的路径也导致了某种程度的可解释性。然而,我们发现只有积极挖掘正题和反题的论据,从而暴露辩论的双方,才能让用户做出明智的决定。挖掘这两个位置的证据也可以被视为对抗性特征生成,使分类器(判断)对矛盾的证据或损坏的数据具有鲁棒性。
我们的方法
- 我们根据两个对立的代理之间的辩论来制定三元组分类的任务。 因此,查询三元组对应于辩论集中的陈述。 代理人通过挖掘 KG 上的路径作为正题或反题的证据。 更准确地说,它们按顺序遍历图,并根据将过去的转换和查询三元组考虑在内的策略来选择下一跳。 转换被添加到当前路径,扩展了参数。 所有路径都由称为法官的二元分类器处理,该分类器试图根据代理提供的参数区分真假三元组。 图 1 显示了一个典型的辩论。 辩论的主要步骤可以概括如下:

- 图2:R2D2的整体架构; 这两个代理从 KG 中提取论据。 与查询关系query relation和查询对象query object一起,这些参数由判断查询是真还是假的法官 judge 处理。
- 辩论所围绕的查询三元组 query triple 被呈现给两个代理。
- 这两个代理轮流从 KG 中提取路径,作为正题和反题的论据。
- 法官将参数与查询三元组一起处理,并估计查询三元组的真值。
- 虽然法官的参数以有监督的方式进行拟合,但两个代理都经过训练,可以使用强化学习在图形中导航。 概括 (Das et al. 2018) 中提出的正式框架,代理的学习任务通过下面概述的固定范围决策过程进行建模。
- 状态 每个智能体的完全可观察状态空间 S S S 由 E 2 × R × E E^2 × R × E E2×R×E 给出。直观地说,我们希望状态对代理 i ∈ { 1 , 2 } i ∈ \{1, 2\} i∈{1,2} 在时间 t t t 和查询三元组 q = ( s q , p q , o q ) q = (s_q, p_q, o_q) q=(sq,pq,oq) 的探索位置 e t ( i ) {e_t}^{(i)} et(i)(即当前位置)进行编码。 因此,时间 t ∈ N t ∈ N t∈N 的状态 S t ( i ) ∈ S {S_t}^{(i)} ∈ S St(i)∈S 表示为 S t ( i ) = ( e t ( i ) , q ) {S_t}^{(i)} = ({e_t}^{(i)} , q) St(i)=(et(i),q) 。
- 动作 代理 i i i 从状态 S t ( i ) = ( e t ( i ) , q ) {S_t}^{(i)}= ({e_t}^{(i)} , q) St(i)=(et(i),q) 的一组可能动作用 A S t ( i ) A_{{S_t}^{(i)}} ASt(i)表示。 它由节点 e t ( i ) {e_t}^{(i)} et(i)和相应目标节点的所有出边组成。 更正式地说, A S t ( i ) = { ( r , e ) ∈ R × E : S t ( i ) = ( e t ( i ) , q ) ∧ ( e t ( i ) , r , e ) ∈ K G } A_{{S_t}^{(i)}} = \{ (r, e) ∈ R × E : {S_t}^{(i)} = ({e_t}^{(i)} , q) ∧({e_t}^{(i)}, r, e )∈ KG\} ASt(i)={(r,e)∈R×E:St(i)=(et(i),q)∧(et(i),r,e)∈KG} 。 此外,我们用 A t ( i ) ∈ A S t ( i ) {A_t}^{(i)} ∈A_{{S_t}^{(i)}} At(i)∈ASt(i)表示代理 i i i 在时间 t t t 执行的操作。 我们为每个节点包括自循环,以便代理可以停留在当前节点。
- 环境 环境通过根据代理的动作更新状态(即通过更改代理的位置)来确定性地演变,从而查询事实保持不变。 形式上,代理 i i i 在时间 t t t 的转移函数由 δ t ( i ) ( S t ( i ) , A t ( i ) ) : = ( e t + 1 ( i ) , q ) {δ_t}^{(i)}({S_t}^{(i)}, {A_t}^{(i)}) := (e_{t+1}^{(i)}, q ) δt(i)(St(i),At(i)):=(et+1(i),q)其中 S t ( i ) = ( e t ( i ) , q ) {S_t}^{(i)}= ({e_t}^{(i)}, q) St(i)=(et(i),q) 和 A t ( i ) = ( r , e t + 1 ( i ) ) {A_t}^{(i)} =( r, e_{t+1}^{(i)}) At(i)=(r,et+1(i)) 。
- 策略 我们用元组
H
t
(
i
)
=
(
H
t
−
1
(
i
)
,
A
t
−
1
(
i
)
)
{H_t}^{(i)} = ({H_{t−1}}^{(i)} ,{A_{t-1}}^{(i)})
Ht(i)=(Ht−1(i),At−1(i)) 表示代理
i
i
i 到时间
t
t
t 的历史,对于
t
≥
1
t ≥ 1
t≥1 和
H
0
(
i
)
=
(
s
q
,
p
q
,
o
q
)
{H_0}^{(i)} = (s_q, p_q, o_q)
H0(i)=(sq,pq,oq) 以及
A
0
(
i
)
=
∅
{A_0}^{(i)} = ∅
A0(i)=∅ 对于
t
=
0
t = 0
t=0。代理通过 LSTM 编码他们的历史 (Hochreiter and Schmidhuber 1997)
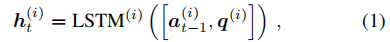
- 其中
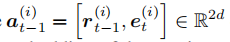
对应于前一个动作的向量空间嵌入(或 t = 0 t = 0 t=0 时的零向量),其中 r t − 1 ( i ) {r_{t-1}}^(i) rt−1(i) 和 e t ( i ) {e_t}^{(i)} et(i) 分别表示关系和目标实体在 R d R_d Rd 中的嵌入。 此外,
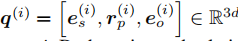
对代理 i i i 的查询三元组进行编码。 实体和关系嵌入对于每个代理都是特定的,并在训练期间的辩论过程中学习。 请注意,使用历史扩展状态空间定义会导致马尔可夫决策过程。 - 每个代理的历史相关动作分布由下式给出

- 其中
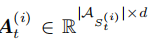
的行包含来自 S t ( i ) {S_t}^{(i)} St(i) 的所有可接受动作的潜在表示。 动作
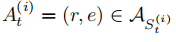
是根据
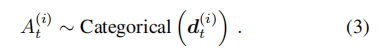
- 等式 (1) 和 (2) 定义了从他的历史空间到所有可接受动作的分布空间的映射,从而得出一个策略 π θ ( i ) π_{θ^{(i)}} πθ(i),其中 θ ( i ) θ^{(i)} θ(i) 表示等式 (1) 和 (2) 中所有可训练参数的集合。
- 辩论动态 第一步,向两个代理呈现真值
φ
(
q
)
∈
0
,
1
φ(q) ∈ {0, 1}
φ(q)∈0,1 的查询三元组
q
=
(
s
q
,
p
q
,
o
q
)
q = (s_q, p_q, o_q)
q=(sq,pq,oq)。 代理 1 认为该事实是真实的,而代理 2 则认为它是错误的。 与大多数正式辩论类似,我们考虑固定轮数
N
∈
N
N ∈ N
N∈N。在每一轮
n
=
1
,
2
,
.
.
.
,
N
n = 1, 2, . . . , N
n=1,2,...,N,代理从查询
s
q
s_q
sq 的主题query subject节点开始以固定长度
T
∈
N
T ∈ N
T∈N 进行图遍历。法官观察代理的路径并预测三元组的真值。 代理 1 开始游戏,根据方程式 (1 - 3) 生成由状态和动作组成的长度为
T
T
T 的序列。 然后代理 2 继续生成从
s
q
s_q
sq 开始的类似序列。算法 1 在推理时包含 R2D2 的伪代码。

- 为了简化符号,我们连续列举了所有动作并删除了指示哪个代理执行动作的上标。 那么对应于代理
i
i
i 的第
n
n
n 个参数的序列由下式给出
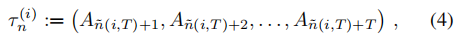
- 我们使用了重新索引
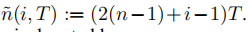
所有参数的序列表示为
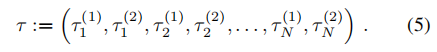
- 法官 法官在 R2D2 中的作用是双重的:首先,法官是一个二元分类器,试图区分真假事实。 其次,法官还评估代理人提取的论点的质量,并为他们分配奖励。 因此,法官也扮演批评者的角色,教导代理人提出有意义的论点。 法官通过前馈神经网络
f
:
R
2
(
T
+
1
)
d
→
R
d
f : R^{2(T +1)d} → R^d
f:R2(T+1)d→Rd 单独处理每个参数和查询,将每个参数的输出相加,并通过二元分类器处理结果和。 更具体地说,在单独处理每个论点之后,法官根据
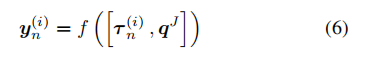
和

-其中
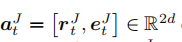
表示法官对动作 A t A_t At 的嵌入,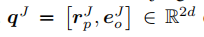
编码查询谓词query predicate和查询对象 query object。 请注意,查询主题query subject不会透露给法官,因为我们希望法官仅根据代理人的行为而不是查询主题query subject的嵌入来做出决定。 在处理完 τ τ τ 中的所有论点后,辩论结束,法官根据 t τ ∈ ( 0 , 1 ) t_τ ∈ (0, 1) tτ∈(0,1) 对查询三元组 q q q 进行评分
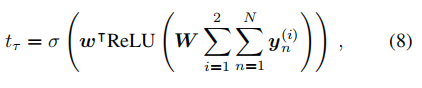
- 其中 W ∈ R d × d W ∈ R^{d×d} W∈Rd×d 和 w ∈ R d w ∈ R^d w∈Rd 表示分类器的可训练参数, σ ( ⋅ ) σ(·) σ(⋅) 表示 sigmoid 激活函数。 我们还尝试了更复杂的架构,其中法官通过循环神经网络处理 τ τ τ 中的每个参数。 然而,我们发现分类性能和论点质量都受到影响。
- 单个查询
q
q
q 的判断目标函数由交叉熵损失给出
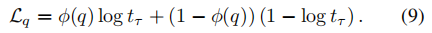
- 因此,在训练期间,我们的目标是最小化由下式给出的整体损失
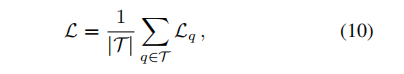
- 其中 T T T 表示训练三元组的集合。 为了防止过度拟合,在等式(10)中添加了一个额外的 L2 惩罚项,其强度 λ ∈ R ≥ 0 λ ∈ R_{≥0} λ∈R≥0 在法官的参数上。
- R2D2 的整体架构概述如图 2 所示。
- 奖励 为了为代理生成反馈,法官还单独处理每个参数
τ
n
(
i
)
{τ_n}^{(i)}
τn(i) 并根据
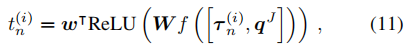
- 其中神经网络
f
f
f 和线性权重向量
w
w
w 都对应于上一段中给出的定义。 因此,
t
n
(
i
)
{t_n}^{(i)}
tn(i) 对应于仅基于代理
i
i
i 的第
n
n
n 个参数的
q
q
q 的分类分数。 由于代理 1 支持正题,代理 2 支持反题,因此奖励由下式给出
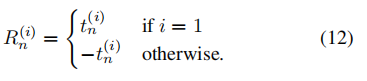
- 直观地说,这意味着代理人只要提取出被法官视为其立场的有力证据的论点,就会获得高额奖励。
- 奖励最大化和培训计划 我们使用 REINFORCE (Williams 1992) 来最大化由下式给出的代理人的预期累积奖励
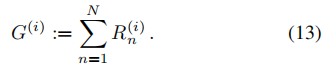
- 因此,代理的最大化问题由下式给出
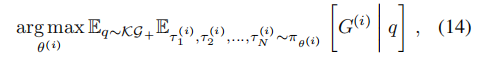
- 其中
K
G
+
{KG}_+
KG+ 是训练三元组的集合,除了
K
G
KG
KG 中观察到的三元组之外,还包含未观察到的三元组。基本原理如下:由于
K
G
KG
KG 仅包含真实事实,因此来自
K
G
KG
KG 的抽样查询将创建一个没有负标签的数据集。因此,通过用实体
o
~
\tilde{o}
o~ 替换对象来创建由正确三元组
(
s
,
p
,
o
)
(s, p, o)
(s,p,o) 构造的损坏三元组是很常见的,以创建假三元组
(
s
,
p
,
o
~
)
∉
K
G
(s, p, \tilde{o}) \notin KG
(s,p,o~)∈/KG(参见 (Bordes)等人,2013))。我们不是创建任何类型的损坏三元组,而是生成一组似是而非的三元组。更具体地说,对于每个
(
s
,
p
,
o
)
∈
K
G
(s, p, o) ∈ KG
(s,p,o)∈KG,我们生成一个三元组
(
s
,
p
,
o
~
)
∉
K
G
(s, p, \tilde{o}) \notin KG
(s,p,o~)∈/KG,约束条件是
o
~
\tilde{o}
o~ 作为关系
p
p
p 的对象出现在数据库中。更正式地说,我们用
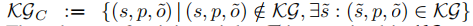
表示损坏的三元组。然后训练三元组 T T T 包含在 K G + : = K G ∪ K G C {KG}_+ := KG ∪ {KG}_C KG+:=KG∪KGC 中。使用似是而非的事实的基本原理是,我们不会将资源浪费在打破隐式类型约束的三元组上。由于这种启发式只需要计算一次并过滤掉可以被类型检查器轻松丢弃的三元组,因此我们可以专注于预测更具挑战性的事实。 - 在训练期间,等式(14)中的第一个期望被训练集上的经验平均值代替。 第二个期望近似于多次推出的经验平均值。 我们还采用移动平均基线来减少方差。 此外,我们使用参数 β ∈ R ≥ 0 β ∈ R_{≥0} β∈R≥0 的熵正则化来强制探索。
- 为了解决智能体需要训练有素的法官才能获得有意义的奖励信号的问题,我们在训练的第一集冻结了智能体的权重。 理由是培训法官并不一定依赖于代理人与他们的实际目标完全一致。 例如,即使代理没有提取与其位置相对应的论点,它们仍然可以提供法官学习利用的有用特征。 在初始训练阶段之后,我们只适合法官的参数,我们采用交替训练方案,我们要么训练法官,要么训练代理。
实验
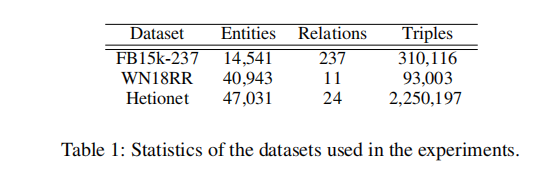
- 数据集 我们在基准数据集 FB15k-237 (Toutanova et al. 2015) 和 WN18RR (Dettmers et al. 2018) 上测量 R2D2 关于三元组分类和 KG 完成任务的性能。 为了在现实世界的任务中测试 R2D2,我们还考虑了 Hetionet(Himmelstein 和 Baranzini 2015),这是一种大规模的异构图形,编码有关化合物、疾病、基因和分子功能的信息。 我们使用 R2D2 检测基因疾病关联并为药物寻找新的目标疾病,这是生物医学领域中具有高度实际相关性的两项任务(参见(Himmelstein 和 Baranzini 2015))。 所有数据集的统计数据如表1所示。
- 度量和评估方案 如第 2 节所述,三元组分类旨在确定查询三元组 ( s q , p q , o q ) (s_q,p_q,o_q) (sq,pq,oq)是真还是假。 因此,它是一个二元分类任务。 对于每种方法,我们设置了一个阈值 δ δ δ,该阈值是通过最大化验证集的准确度获得的。 这意味着,对于给定的查询三元组 ( s q , p q , o q ) (s_q,p_q,o_q) (sq,pq,oq),如果其分数(例如,由公式 (8) 对 R2D2 给出)大于 δ δ δ,则三元组将被分类为真,否则为假。 由于大多数 K G KG KG 不包含标记为错误的事实,因此需要对负三元组进行采样。 我们生成了一组否定三元组:对于验证和测试集中观察到的每个三元组,我们创建一个错误但似是而非的事实(见第 3 节)。我们报告所有方法的准确性、PR AUC 和 ROC AUC。 由于 R2D2 是一个随机分类器,我们可以在推理时产生多个相同查询的 rollout,并平均得到的分类分数以降低方差。
- 尽管 R2D2 的目的是三重分类,但可以将其转换为 K G KG KG 完成方法,如下所示:我们考虑一系列对象实体,每个实体产生不同的分类分数 t τ t_τ tτ,由等式 (8) 给出。由于 t τ t_τ tτ以解释为三元组合理性的度量,因此我们使用分类分数来产生排名。更具体地说,我们将测试集中每个正确的三元组与所有合理但错误的三元组进行排名(参见第 3 节)。由于此过程在训练期间计算量很大(需要对每个训练三元组进行多次辩论以产生排名),我们选择以下关系用于训练和测试目的:对于 FB15k-237,我们遵循 (Socher et al. 2013)并考虑“职业”、“国籍”、“种族”和“宗教”之间的关系。继 (Himmelstein and Baranzini 2015) 和 (Himmelstein et al. 2017) 之后,Hetionet 考虑了关系“gene_associated_with_disease”和“compound_treats_disease”。我们报告正确实体的平均排名、平均倒数排名 (MRR) 以及 k = 1 , 3 , 10 k = 1,3,10 k=1,3,10 的 Hits@k - 正确实体排在前 k k k 位的测试三元组的百分比。
- 为了为所有考虑的方法找到最合适的超参数集,我们执行交叉验证。因此,使用了将数据集规范拆分为训练、验证和测试集的方法。特别是,我们确保在训练期间分配给验证集或测试集(以及它们各自的反向关系)的三元组不包含在 K G KG KG 中。所有方法的测试集的结果都是基于在验证集上表现出最佳性能的超参数(基于三元组分类的最高准确度和链接预测的最高 MRR)。我们考虑了 R2D2 的以下超参数范围:嵌入的潜在维度 d d d 的数量从范围 {32、64、128} 中选择。代理的 LSTM 层数从 {1, 2, 3} 中选择。法官的 MLP 中的层数在 {1, 2, 3, 4, 5} 范围内调整。 β β β 选自 {0.02, 0.05, 0.1}。每个参数 T T T 的长度在 {1,2,3} 范围内调整,辩论轮数 N N N 设置为 3。此外,L2 正则化强度 λ λ λ 设置为 0.02。此外,训练期间的 rollout 数量在测试时由 20 和 50(三重分类)或 100(KG 完成)给出。使用 Adam 优化法官的损失和代理人的奖励,学习率为 10-4。补充材料中报告了最佳超参数。
- 所有实验均在具有 48 个 CPU 内核和 96 GB RAM 的机器上进行。 在任一数据集上训练 R2D2 最多需要 4 小时。 测试大约需要 1-2 小时,具体取决于数据集。
结果
- 三元组分类 我们将 R2D2 在三重分类任务上的性能与 DistMult、ComplEx、TransE、TransR 和 SimplE 进行比较。 结果显示在表 2 中。在 FB15k-237 上,R2D2 在准确性、PR AUC 和 ROC AUC 方面优于所有基线。 然而,在 WN18RR 上,R2D2 的性能在很大程度上由因式分解方法 ComplEx 和 DistMult 主导。 我们推测这是由于数据集中的稀疏性。 作为一种补救措施,我们采用了在训练期间固定的 TransE 预训练嵌入 我们用 R2D2+ 表示生成的方法,并发现它在 WN18RR 上的 PR AUC 和 ROC AUC 执行所有其他方法。 我们还在 FB15k-237 上测试了 R2D2+,发现它仅将 R2D2 的结果提高了一小部分。 这是意料之中的,因为 FB15k-237 不像 WN18RR 那样稀疏。
- 由于实体之间的简单功能关系,我们选择 TransE 嵌入。 这些可以很容易地被 R2D2 利用。

- KG 完成 除了用于三元组分类的基线之外,我们还采用了基于路径的链接预测方法 MINERVA。 请注意,不可能计算 MINERVA 的公平平均排名,因为它不会产生所有候选对象的完整排名。 表 3 显示了在 FB15k-237 和 Hetionet 上考虑的所有方法的完成任务的结果(子集;见上文)。 R2D2 在 FB15k-237 上针对除 Hits@10 之外的所有指标执行所有其他方法。 但是,MIN ERVA 的性能几乎不相上下。 此外,R2D2 在 MRR、平均排名、Hits@3 和 Hits@10 方面优于 Hetionet 上的所有基线。 虽然 MINERVA 在 Hits@1 方面表现出最佳性能,但 R2D2 在所有其他指标方面产生明显更好的结果。

- 调查 为了在客观的环境中评估这些论点是否对用户有用,我们进行了一项调查,其中受访者扮演法官的角色,根据代理人的论点做出分类决定。 更具体地说,我们设置了一个由十轮组成的在线测验。 每一轮都以从 FB15k-237(KG 完成)的测试集中采样的查询(带有蒙面主题)为中心。 除了查询语句,我们还向用户展示了代理以随机顺序提取的六个参数。 基于这些论点,受访者应该判断该陈述是真还是假。 此外,我们要求受访者评估他们对每一轮的信心。
- 基于 44 名参与者(发送了 109 份邀请),我们发现受访者分类的总体准确率为 81.8%。此外,基于多数投票(即基于大多数受访者的分类),十个问题中有九个被正确分类,表明人类与自动法官的表现大致相当。此外,大多数受访者错误的陈述对应于法官也错误分类的唯一查询。在这一轮中,参与者应该决定一个人是否信奉卫理公会。很难正确回答这个问题,因为手头的人是玛格丽特·撒切尔,她一生信奉两种不同的宗教:卫理公会和英国国教。大多数受访者和法官在所有回合中都同意这一事实表明法官与人类直觉一致,并且论点具有信息性。此外,我们发现,当用户为他们的决定(“相当肯定”或“绝对肯定”)分配高置信度分数时,他们分类的总体准确率为 89%。当用户分配低置信度分数(“相当不确定”或“绝对不确定”)时,准确率下降到 68.4%。补充材料中报告了完整的调查以及详细的评估。
讨论和未来的工作
- 我们手动检查了提取路径的质量,通常会找到合理的参数,但也经常会发现没有直观意义的参数。我们推测其中一个原因是,如果代理人为虚假立场辩护,他们通常很难找到有意义的证据。此外,对于许多论点,大多数相关信息已经包含在代理的第一步中,而后来的转换通常包含看似不相关的信息。这种现象可能是由于法官忽略了后来的转换并且代理人没有获得有意义的奖励。此外,关于实体邻域的相关信息可以编码在实体的嵌入中。虽然法官可以通过培训过程访问这些信息,但它对用户仍然是隐藏的。例如,当争论 Nelson Mandela 是演员时(见表 4),agent 1 的论点要求用户知道 Naomi Campbell 和 Leonardo Di Caprio 是演员(编码在 FB15k-237 中)。那么这个论点可以证明Nelson Mandela也是一名演员,因为人们往往有朋友分享他们的职业(社会同质性)。然而,如果没有这个上下文信息,直觉上不清楚为什么这是一个合理的论点。

- 表 4:R2D2 生成的两个示例辩论:代理 1 认为查询是真的,代理 2 认为它是错误的。
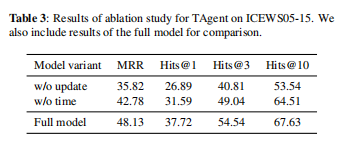
- 为了检查智能体和法官之间的相互作用,我们考虑使用两个智能体训练 R2D2,但在测试期间忽略一个智能体的论点的设置。 这将导致有利于法官考虑其论点的代理人的偏颇结果。 我们在 FB15k-237 上测试了这个设置,发现当我们只考虑代理 1 的参数时,正面预测的数量增加了 18.8%。 相比之下,当我们只考虑代理 2 时,正面预测的数量下降了 70.2%。 该结果表明辩论动态正在按预期运行,并且代理人学会提取法官认为作为其各自立场证据的论点。
- 虽然调查结果令人鼓舞,但我们计划开发 R2D2 的变体,以提高论点的质量,并进行大规模的实验研究,其中还包括受控环境中的其他基线。 此外,我们计划讨论公平和责任方面的考虑。 在这方面,(Nickel 等人,2015 年)强调,当将统计方法应用于不完整的 KG 时,结果可能会受到数据生成过程中的偏差的影响,因此应进行相应的解释。 否则,盲目地遵循这些预测会加强偏见。 虽然我们方法中的法官也利用了数据中的偏差,但这些论点可以帮助识别这些偏见,并可能将有问题的论点排除在决定之外。
结论
- 我们提出了 R2D2,这是一种基于两个对立强化学习代理之间的辩论游戏的 KG 推理新方法。 代理在 KG 中搜索能够让二元分类器相信他们的位置的论点。 因此,它们充当稀疏的对抗性特征生成器。 由于分类器(法官)仅根据挖掘的论点做出决定,因此 R2D2 比其他基线方法更具可解释性。 我们的实验表明,在基准数据集 WN18RR 和 FB15k-237 上的所有指标方面,R2D2 优于三重分类设置中的所有基线。 此外,我们证明了 R2D2 原则上可以在 KG 完成设置中运行。 我们发现,与 FB15k-237 和 Hetionet 子集上的所有基线相比,R2D2 具有竞争性能。 此外,我们的调查结果表明,这些论点提供了丰富的信息,并且法官符合人类的直觉。