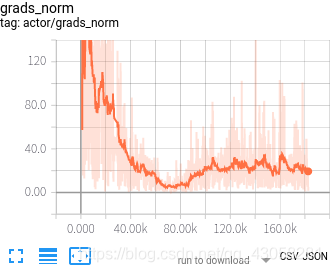
DDPG自动驾驶横向控制项目调参过程
- actor和critic网络的学习率
- OU噪声参数设置
- 整体参数设置
- 结果
我做的一个DDPG的自动驾驶横向控制的项目,用的模拟器是Torcs。
在调参过程中遇到了很多问题,在这里记录一下。
actor和critic网络的学习率
一开始我按照大部分资料中说的,学习率设计的越小越好。将学习率设为actor和critic分别为1e-6和1e-5。
结果出现了loss震荡的情况以及reward最终收敛到最低值,学到了坏的结果的情况。


根据多次实验的结果,我选取的学习率为演员网络和评论家网络分别为 1e-4 和 1e-3,并引入在训练神经网络时,学习率随轮数衰减。
分析:
虽然很多资料说学习率越小越好,但是也很可能导致实际上没有学到东西。另外在设置参数的时候最好critic比actor的参数设置大一些。
OU噪声参数设置
由于我的智能体始终无法学会转弯,我认为是OU噪声设置过小的缘故。
一开始OU噪声我设置成DDPG论文中的一样:
σ
\sigma
σ为0.15,
θ
\theta
θ为0.2。最终陷入了局部最优。

因此我调整参数为:

整体参数设置
• Actor network learning rate: 1e-4;
• Critic network learning rate: 1e-3
• Soft target update rate
τ
\tau
τ : 1e-3
• Batch size: 128;
• Experience playback pool size: 38700;
• Episode steps limit: 183337
• Warmup steps: 1000
• Simulation frequency: 20 Hz.
备注:
- Batch size越大越好;
- 经验池大小最好是batch size的300倍;
结果