【深入浅出强化学习-编程实战】 10 DDPG
- Pendulum单摆系统MDP模型
- 代码
- 训练效果
- 代码学习
Pendulum单摆系统MDP模型
- 该系统只包含一个摆杆,其中摆杆可以绕着一端的轴线摆动,在轴线施加力矩 τ \tau τ来控制摆杆摆动。
- Pendulum目标是:从任意状态出发,施加一系列的力矩,使得摆杆可以竖直向上。
- 状态输入为 s = [ θ , θ ˙ ] s=[\theta,\dot{\theta}] s=[θ,θ˙]
- 动作空间为 τ ∈ [ − 2 , 2 ] \tau\in[-2,2] τ∈[−2,2],连续空间
- 回报函数为 r = − θ 2 − 0.1 θ ˙ 2 − 0.001 τ 2 r=-{\theta}^2-0.1{\dot{\theta}}^2-0.001{\tau}^2 r=−θ2−0.1θ˙2−0.001τ2,其中 θ ∈ [ − π , π ] \theta\in[-\pi,\pi] θ∈[−π,π]
- 状态转移概率Pendulum的动力学方程由gym模拟器提供
代码
python">import tensorflow as tf
import numpy as np
import gym
import matplotlib.pyplot as plt
import time
import random
RENDER = False
C_UPDATE_STEPS = 1
A_UPDATE_STEPS = 1
########################################################################################################################
# 经验缓存器类
# DDPG是off-policy,采样策略和要评估的策略是两个策略。
# 采样策略用来产生数据,要评估的策略则是采样这些产生的数据进行策略改进
# 因此我们需要一个经验缓存器来存储行为策略产生的数据。
# 为了实现样本的存储和采集
class Experience_Buffer():
def __init__(self,buffer_size=5000):
self.buffer = []
self.buffer_size = buffer_size
# 用来将探索过程中的样本存储到buffer中
def add_experience(self,experience):
if len(self.buffer)+len(experience) >= self.buffer_size:
self.buffer[0:(len(experience)+len(self.buffer))-self.buffer_size] = []
self.buffer.extend(experience)
# 从buffer中采集数据用于策略改善
def sample(self,samples_num):
sample_data = np.reshape(np.array(random.sample(self.buffer,samples_num)),[samples_num,4])
train_s = np.array(sample_data[0,0])
train_s_ = np.array(sample_data[0,3])
train_a = sample_data[:,1]
train_r = sample_data[:,2]
for i in range(samples_num-1):
train_s = np.vstack((train_s,np.array(sample_data[i+1,0])))
train_s_ = np.vstack((train_s_,np.array(sample_data[i+1,3])))
train_s = np.reshape(train_s,[samples_num,3])
train_s_ = np.reshape(train_s_,[samples_num,3])
train_r = np.reshape(train_r,[samples_num,1])
train_a = np.reshape(train_a,[samples_num,1])
return train_s,train_a,train_r,train_s_
########################################################################################################################
# 策略网络类
# DDPG网络结果包括Actor网络和Critic网络,参数分别是thets和w
# DDPG在进行TD target计算时,使用了独立的目标网络参数theta-和w-
# 一共4套参数
# 用with tf.variable_scope()函数为4组参数命名
# 另外,Actor和Critic网络都有各自独立的损失函数,在进行训练时,要注意每个网络的输入
# 对于Actor网络
# 输入为状态S,可训练参数为theta
# 损失函数为loss=Q(s,{u_\theta}(s))
# 对于Critic网络
# 输入为状态S和动作A,可训练参数为w_s,w_a
# 损失函数为loss = (r+Q(s',a;w)-Q(s,a;w))^2
class Policy_Net():
# 初始化函数,创建ddpg网络模型,构造损失函数,优化器
def __init__(self,env,action_bound,lr=0.0001,model_file=None):
self.action_bound = action_bound
self.gamma = 0.90
self.tau = 0.01
# tf工程
self.sess = tf.Session()
self.learning_rate = lr
# 输入特征的维数
self.n_features = env.observation_space.shape[0]
# 输出动作空间的维数
self.n_actions = 1
# 1.输入层
self.obs = tf.placeholder(tf.float32,shape=[None,self.n_features])
self.obs_ = tf.placeholder(tf.float32,shape=[None,self.n_features])
# 2. 创建网络模型
# 2.1 创建策略网络,策略网络的命名空间为actor
with tf.variable_scope('actor'):
# 可训练的策略网络,可训练的网络参数命名空间为actor/eval:
self.action = self.build_a_net(self.obs,scope='eval',trainable=True)
# target策略网络,不可训练,网络参数命名空间为actor/target
self.action_ = self.build_a_net(self.obs_,scope='target',trainable=False)
# 2.2 创建行为值函数网络,行为值函数的命名空间为critic
with tf.variable_scope('critic'):
# 可训练的行为值函数,可训练的网络参数命名空间为:critic/eval
Q = self.build_c_net(self.obs,self.action,scope='eval',trainable=True)
# 不可训练的target
Q_= self.build_c_net(self.obs_,self.action_,scope='target',trainable=False)
# 2.3 整理4套网络参数
# 2.3.1 可训练的策略网络参数
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope='actor/eval')
# 2.3.2 不可训练的策略网络参数
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope='actor/target')
# 2.3.3 可训练的行为值网络参数
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope='critic/eval')
# 2.3.4 不可训练的行为值网络参数
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope='critic/target')
# 2.4 定义新旧参数的替换操作
self.update_olda_op = [olda.assign((1-self.tau)*olda+self.tau*p) for p,olda in zip(self.ae_params,self.at_params)]
self.update_oldc_op = [oldc.assign((1-self.tau)*oldc+self.tau*p) for p,oldc in zip(self.ce_params,self.ct_params)]
# 3 构建损失函数
# 3.1 构建行为值函数的损失函数
self.R = tf.placeholder(tf.float32,[None,1])
Q_target = self.R +self.gamma*Q_
self.c_loss = tf.losses.mean_squared_error(labels=Q_target,predictions=Q)
# 3.2 构建策略损失函数,该函数为行为值函数
self.a_loss = -tf.reduce_mean(Q)
# 4 定义优化器
# 4.1 定义动作优化器,注意优化的变量在ae_params中
self.a_train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(self.a_loss,var_list=self.ae_params)
# 4.2 定义值函数优化器,注意优化的变量在ce_params中
self.c_train_op = tf.train.AdamOptimizer(0.0002).minimize(self.c_loss,var_list=self.ce_params)
# 5 初始化图中的变量
self.sess.run(tf.global_variables_initializer())
# 6 定义保存和恢复模型
self.saver = tf.train.Saver()
if model_file is not None:
self.restore_model(model_file)
# Critic网络创建函数,该函数创建Critic网络,
# 有两个关键的参数:变量命名空间scope和参数是否可训练
def build_c_net(self,obs,action,scope,trainable):
with tf.variable_scope(scope):
c_l1 = 50
# 与状态相对应的权值
w1_obs = tf.get_variable('w1_obs',[self.n_features,c_l1],trainable=trainable)
# 与动作相对应的权值
w1_action = tf.get_variable('w1_action',[self.n_actions,c_l1],trainable=trainable)
b1 = tf.get_variable('b1',[1,c_l1],trainable=trainable)
# 第1层,隐含层
c_f1 = tf.nn.relu(tf.matmul(obs,w1_obs)+tf.matmul(action,w1_action)+b1)
# 第2层,行为值函数输出层
c_out = tf.layers.dense(c_f1,units=1,trainable=trainable)
return c_out
# Actor网络创建函数,创建Actor网络
# 有两个关键的参数:变量命名空间scope和参数是否可训练
def build_a_net(self,obs,scope,trainable):
with tf.variable_scope(scope):
# 行为值函数第1层隐含层
a_f1 = tf.layers.dense(inputs=obs,units=100,activation=tf.nn.relu,trainable=trainable)
# 第2层,确定性策略
a_out = 2 * tf.layers.dense(a_f1,units=self.n_actions,activation=tf.nn.tanh,trainable=trainable)
return tf.clip_by_value(a_out,action_bound[0],action_bound[1])
#根据策略网络选择动作
def choose_action(self, state):
action = self.sess.run(self.action, {self.obs:state})
# print("greedy action",action)
return action[0]
# 单步训练函数,该函数利用buffer里面的数据对Actor网络和Critic网络进行训练
def train_step(self,train_s,train_a,train_r,train_s_):
for _ in range(A_UPDATE_STEPS):
self.sess.run(self.a_train_op,feed_dict={self.obs:train_s})
for _ in range(C_UPDATE_STEPS):
self.sess.run(self.c_train_op,feed_dict={self.obs:train_s,self.action:train_a,self.R:train_r,self.obs_:train_s_})
# 更新旧的策略网络
self.sess.run(self.update_oldc_op)
self.sess.run(self.update_olda_op)
# return a_loss,c_loss
# 保存模型函数
def save_model(self,model_path):
self.saver.save(self.sess,model_path)
# 恢复模型函数
def restore_model(self,model_path):
self.saver.restore(self.sess,model_path)
########################################################################################################################
# 训练和测试
# DDPG是off-policy的深度确定性策略,因此在训练的过程中需要借助具有探索能力的行为策略。
# 该行为策略可以采用简单的高斯策略,其中均值由深度确定性策略给出,方差可设置成随时间衰减的变量。
def policy_train(env,brain,exp_buffer,training_num):
reward_sum = 0
average_reward_line = []
training_time = []
average_reward = 0
batch = 32
#for i in range(training_num):
# sample_states,sample_actions,sample_rs = sample.sample_step(32)
# a_loss,c_loss = brain.train_step(sample_states,sample_actions,sample_rs)
for i in range(training_num):
total_reward = 0
# 初始化环境
observation = env.reset()
done = False
while True:
# 探索权重衰减
var = 3*np.exp(-i/100)
state = np.reshape(observation,[1,brain.n_features])
# 根据神经网络选取动作
action = brain.choose_action(state)
# 给动作添加随机项,以便进行探索
action = np.clip(np.random.normal(action,var),-2,2)
observation_next,reward,done,info = env.step(action)
# 存储1条经验
experience = np.reshape(np.array([observation,action[0],reward/10,observation_next]),[1,4])
exp_buffer.add_experience(experience)
if len(exp_buffer.buffer)>batch:
# 采样数据,并进行训练
train_s,train_a,train_r,train_s_ = exp_buffer.sample(batch)
# 学习1步
brain.train_step(train_s,train_a,train_r,train_s_)
# 推进一步
observation = observation_next
total_reward += reward
if done:
break
if i == 0:
average_reward = total_reward
else:
average_reward = 0.95*average_reward + 0.05*total_reward
print("第%d次学习后的平均回报为%f"%(i,average_reward))
average_reward_line.append(average_reward)
training_time.append(i)
if average_reward > -300:
break
brain.save_model('./current_bset_ddpg_pendulum')
plt.plot(training_time,average_reward_line)
plt.xlabel("training number")
plt.ylabel("score")
plt.show()
def policy_test(env,policy,test_num):
for i in range(test_num):
reward_sum = 0
observation = env.reset()
print("第%d次测试,初始状态%f,%f,%f"%(i,observation[0],observation[1],observation[2]))
# 将1个episode的回报存储起来
while True:
env.render()
# 根据策略网络产生1个动作
state = np.reshape(observation,[1,3])
action = policy.choose_action(state)
observation_,reward,done,info = env.step(action)
reward_sum += reward
#print(reward)
if done:
print("第%d次测试总回报%f"%(i,reward_sum))
break
time.sleep(0.01)
observation = observation_
########################################################################################################################
# 主函数
if __name__ == '__main__':
# 创建环境
env_name = 'Pendulum-v0'
env = gym.make(env_name)
env.unwrapped
env.seed(1)
# 力矩边界
action_bound = [-env.action_space.high,env.action_space.high]
# 实例化策略网络
brain = Policy_Net(env,action_bound)
# 下载当前最好的模型进行测试
# brain = Policy_Net(env,action_bound,model_file='./current_bset_ddpg_pendulum')
# 经验缓存
exp_buffer = Experience_Buffer()
training_num = 500
# 训练策略网络
policy_train(env,brain,exp_buffer,training_num)
# 测试训练的网络
reward_sum = policy_test(env,brain,100)
训练效果


第126次学习后的平均回报为-299.690291
经过120多次训练就平均得分超过了-300,效率变高了很多。
代码学习
line 31
python"> sample_data = np.reshape(np.array((random.sample(self.buffer,samples_num)),[samples_num,4]))
np.reshape()
- 语法
python">numpy.reshape(a,newshape,order='C')
- 参数
a : 数组——需要处理的数据。
newshape : 新的格式——整数或整数数组,如(2,3)表示2行3列。新的形状应该与原来的形状兼容,即行数和列数相乘后等于a中元素的数量。如果是整数,则结果将是长度的一维数组,所以这个整数必须等于a中元素数量。若这里是一个整数数组,那么其中一个数据可以为-1。在这种情况下,这个个值python会自动从根据第二个数值和剩余维度推断出来。 - 参考:https://blog.csdn.net/zhanggonglalala/article/details/79356653
Python random sample() 方法
- 定义和用法
sample()方法返回一个列表,其中从序列中随机选择指定数量的项目。
注意:此方法不会更改原始顺序。 - 返回
一个包含列表中任何两项的列表: - 语法
python">random.sample(sequence, k)
- 参数
sequence: 可以是任何序列:列表,集合,范围等。
k: 返回列表的大小
line 37
python"> train_s = np.vstack((train_s,np.array(sample_data[i+1,0])))
- np.vstack填充空数组
- 利用
np.vstack([array,data])将data填入array。 - 总的来说,在我们需要将for语句产生的数据逐次填充到一个数组当中时,就可以使用np.vstack。
line 83
python">with tf.variable_scope('actor'):
# 可训练的策略网络,可训练,网络参数命名空间为actor/eval:
self.action = self.build_a_net(self.obs,scope='eval',trainable=True)
# target策略网络,不可训练,网络参数命名空间为actor/target
self.action_ = self.build_a_net(self.obs_,scope='target',trainable=False)
- 参考:https://blog.csdn.net/qq_38973721/article/details/107056073
line 96
python"> self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope='actor/eval')
tf.get_collection()
- 主要作用:从一个集合中取出变量
python"> tf.get_collection(
key,
scope=None
)
- 该函数可以用来获取key集合中的所有元素,返回一个列表。列表的顺序依变量放入集合中的先后而定。scope为可选参数,表示的是名称空间(名称域),如果指定,就返回名称域中所有放入‘key’的变量的列表,不指定则返回所有变量。
- 该函数常常与tf.get_variable和tf.add_to_collection配合使用。
tf.GraphKeys
- GraphKeys
tf.GraphKeys包含所有graph collection中的标准集合名,有点像Python里的build-in fuction。
首先要了解graph collection是什么。 - graph collection
在官方教程——图和会话中,介绍什么是tf.Graph是这么说的:tf.Graph包含两类相关信息:- 图结构。
图的节点和边缘,指明了各个指令组合在一起的方式,但不规定它们的使用方式。图结构与汇编代码类似:检查图结构可以传达一些有用的信息,但它不包含源代码传达的的所有有用上下文。 - 图集合。
TensorFlow提供了一种通用机制,以便在tf.Graph中存储元数据集合。tf.add_to_collection函数允许您将对象列表与一个键key相关联(其中tf.GraphKeys定义了部分标准键),tf.get_collection则允许您查询与键key关联的所有对象。TensorFlow库的许多组成部分会使用它:例如,当您创建tf.Variable时,系统会默认将其添加到表示“全局变量(tf.global_variables)”和“可训练变量tf.trainable_variables)”的集合中。当您后续创建tf.train.Saver或tf.train.Optimizer时,这些集合中的变量将用作默认参数。 - 常见GraphKeys
GLOBAL_VARIABLES: 该collection默认加入所有的Variable对象,并且在分布式环境中共享。一般来说,TRAINABLE_VARIABLES包含在MODEL_VARIABLES中,MODEL_VARIABLES包含在GLOBAL_VARIABLES中
- 图结构。
参考:https://blog.csdn.net/hustqb/article/details/80398934
line 104
python">self.update_olda_op = [olda.assign((1-self.tau)*olda+self.tau*p) for p,olda in zip(self.ae_params,self.at_params)]
- assign往后添加一列
- for x,y in zip(keys, values) 并行遍历
line 115
python">self.a_train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(self.a_loss,var_list=self.ae_params)
minimize
- 功能:通过更新
var_list添加操作以最大限度地最小化loss。
python">minimize(
loss,
global_step=None,
var_list=None,
gate_gradients=GATE_OP,
aggregation_method=None,
colocate_gradients_with_ops=False,
name=None,
grad_loss=None
)
- 参考:tf.train.AdamOptimizer 简介
line 132
python"> w1_obs = tf.get_variable('w1_obs',[self.n_features,c_l1],trainable=trainable)
tf.get_variable()函数
如果你定义的变量名称在之前已被定义过,则TensorFlow 会引发异常。可使用tf.get_variable() 函数代替tf.Variable()。如果变量存在,函数tf.get_variable( ) 会返回现有的变量。如果变量不存在,会根据给定形状和初始值创建变量。
python">tf.get_variable(
name,
shape=None,
dtype=None,
initializer=None,
regularizer=None,
trainable=None,
collections=None,
caching_device=None,
partitioner=None,
validate_shape=True,
use_resource=None,
custom_getter=None,
constraint=None,
synchronization=tf.VariableSynchronization.AUTO,
aggregation=tf.VariableAggregation.NONE
)
- 参数:
- name:新变量或现有变量的名称。
- shape:新变量或现有变量的形状。
- dtype:新变量或现有变量的类型(默认为DT_FLOAT)。
- initializer:如果创建了变量的初始化器。可以是初始化器对象,也可以是张量。如果它是一个张量,它的形状必须是已知的,除非validate_shape是假的。
- regularizer:A(张量->张量或无)函数;将其应用于新创建的变量的结果将添加到集合tf.GraphKeys中。正则化-损耗,可用于正则化。
- trainable:如果为真,也将变量添加到图形集合GraphKeys中。TRAINABLE_VARIABLES(见tf.Variable)。
- collections:要向其中添加变量的图形集合键的列表。默认为[GraphKeys.GLOBAL_VARIABLES]。
- caching_device:可选的设备字符串或函数,描述变量应该缓存到什么地方以便读取。变量的设备的默认值。如果没有,则缓存到另一个设备上。典型的用途是在使用该变量的操作系统所在的设备上缓存,通过Switch和其他条件语句来重复复制。
- partitioner:可选的callable,它接受要创建的变量的完全定义的TensorShape和dtype,并返回每个轴的分区列表(目前只能分区一个轴)。
- validate_shape:如果为False,则允许用一个未知形状的值初始化变量。如果为真,默认情况下,initial_value的形状必须是已知的。要使用它,初始化器必须是一个张量,而不是初始化器对象。
- use_resource:如果为False,则创建一个常规变量。如果为真,则创建一个具有定义良好语义的实验性资源变量。默认值为False(稍后将更改为True)。当启用紧急执行时,该参数总是强制为真。
- custom_getter: Callable,它将true getter作为第一个参数,并允许覆盖内部get_variable方法。custom_getter的签名应该与这个方法的签名相匹配,但是未来最可靠的版本将允许更改:def custom_getter(getter、*args、**kwargs)。还允许直接访问所有get_variable参数:def custom_getter(getter、name、*args、**kwargs)。一个简单的身份自定义getter,简单地创建变量与修改的名称是:
- constraint:优化器更新后应用于变量的可选投影函数(例如,用于为层权重实现规范约束或值约束)。函数必须将表示变量值的未投影张量作为输入,并返回投影值的张量(其形状必须相同)。在进行异步分布式培训时使用约束并不安全。
- synchronization:指示何时聚合分布式变量。可接受的值是在tf.VariableSynchronization类中定义的常量。默认情况下,同步设置为AUTO,当前分发策略选择何时同步。如果同步设置为ON_READ,则不能将trainable设置为True。
- aggregation:指示如何聚合分布式变量。可接受的值是在tf.VariableAggregation类中定义的常量。
- 返回值:
创建的或现有的变量(或PartitionedVariable,如果使用了分区器)。 - 参考:https://blog.csdn.net/weixin_36670529/article/details/976464620
line 159
python">for _ in range(A_UPDATE_STEPS):
- python中
for _ in range ()中_的意思 - 其中
_是一个循环标志,也可以用i,j等其他字母代替,下面的循环中不会用到,起到的是循环此数的作用
line 205
python">action = np.clip(np.random.normal(action,var),-2,2)
- 首先回忆一下正态分布:
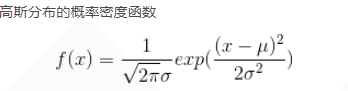
- 在numpy中对应于:
python">numpy.random.normal(loc=0.0, scale=1.0, size=None)
- 参数的意义:
- loc:float
代表概率分布的均值,在正态分布图中表示中心的位置坐标 - scale:float
代表概率分布的标准差,在正态分布图中表示图形的宽度。值越大,图像越矮胖,值越小,图像越高瘦。 - size:int or tuple of ints
代表输出的shape,默认为None,只输出一个值
- loc:float
- 在我们熟悉的正态分布中,其等价于标准正太分布(μ=0, σ=1)。
- 接下来是关于
np.clip()截取函数的理解:
python">np.numpy(a,a_min,a_max,out=None)
- 将数组a中的所有数限定在范围[a_min,a_max],其中小于a_min的数,将变为a_min,大于a_max的值,将变为a_max。
- 参数含义:
a:代表要截取的数组
a_min:代表截取的下限,可以为数组,代表对应位置元素的截取下限
a_max:代表截取的上限,可以为数组,代表对应位置元素的截取上限
out:可选项,表示将强制截取后的结果放到这个数组中,但out中数组的shape必须和a的shape相同。 - 这里请注意,进行强制截取后,a中数据并未发生变化,只是获得了一个临时的数组。若想讲a变为,截取后的结果,
- 可以将out设置为a,或者将结果赋值给a。
- 参考:https://blog.csdn.net/up_XCY/article/details/102918930