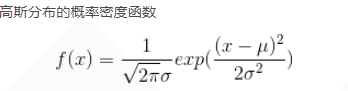【深入浅出强化学习-编程实战】 8 Actor-Critic-Pendulum
Pendulum单摆系统MDP模型
- 该系统只包含一个摆杆,其中摆杆可以绕着一端的轴线摆动,在轴线施加力矩 τ \tau τ来控制摆杆摆动。
- Pendulum目标是:从任意状态出发,施加一系列的力矩,使得摆杆可以竖直向上。
- 状态输入为 s = [ θ , θ ˙ ] s=[\theta,\dot{\theta}] s=[θ,θ˙]
- 动作空间为 τ ∈ [ − 2 , 2 ] \tau\in[-2,2] τ∈[−2,2],连续空间
- 回报函数为 r = − θ 2 − 0.1 θ ˙ 2 − 0.001 τ 2 r=-{\theta}^2-0.1{\dot{\theta}}^2-0.001{\tau}^2 r=−θ2−0.1θ˙2−0.001τ2,其中 θ ∈ [ − π , π ] \theta\in[-\pi,\pi] θ∈[−π,π]
- 状态转移概率Pendulum的动力学方程由gym模拟器提供
TD-AC算法
python">import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import gym
RENDER = False
class Sample():
def __init__(self,env,policy_net):
self.env = env
self.policy_net = policy_net
self.gamma = 0.90
# 该函数实现与环境交互一次,并将交互得到的数据处理成可用于神经网络训练的数据形式。
# 采样数据包括当前状态s,下一个状态s',当前回报r
def sample_step(self,observation):
obs_next = []
obs = []
actions = []
r = []
state = np.reshape(observation,[1,3])
action = self.policy_net.choose_action(state)
observation_,reward,done,info = self.env.step(action)
# 存储当前观测
obs.append(np.reshape(observation,[1,3])[0,:])
# 存储后继观测
obs_next.append(np.reshape(observation_,[1,3])[0,:])
actions.append(action)
# 存储立即回报
r.append((reward)/10)
# reshape观测和回报
obs = np.reshape(obs,[len(obs),self.policy_net.n_features])
obs_next = np.reshape(obs_next,[len(obs),self.policy_net.n_features])
actions = np.reshape(actions,[len(actions),1])
r = np.reshape(r,[len(r),1])
return obs,obs_next,actions,r,done,reward
# 策略网络类
# 我们需要定义两套系统:
# Actor网络:
# 输入层:3维观测空间;
# 隐含层:200个神经元,激活函数为ReLU
# 输出层:表示正态分布均值的1个神经元,激活函数为tanh
# 损失函数:log\pi*\delta + 0.01H(\pi)
# Critic网络
# 输入层:3维观测空间
# 隐含层:100个神经元,激活函数维Relu
# 输出层: 表示状态值函数的1个神经元,没有激活函数
# 损失函数:loss = (r+V(s';w)-V(s;w))^2
# 定义策略网络
class Policy_net():
# 初始化函数,构建Actor神经网络模型和critic神经网络模型
def __init__(self,env,action_bound,lr=0.0001,model_file=None):
self.learning_rate = lr
# 输入特征的维数
self.n_features = env.observation_space.shape[0]
# 输出动作空间的维数
self.n_actions = 1
# 1.1 输入层
self.obs = tf.placeholder(tf.float32,shape=[None,self.n_features])
# 1.2 策略网络第1层隐含层
self.a_f1 = tf.layers.dense(inputs=self.obs,units=200,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.3 第2层,均值
a_mu = tf.layers.dense(inputs=self.a_f1,units=self.n_actions,activation=tf.nn.tanh,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.4 第3层,标准差
a_sigma = tf.layers.dense(inputs=self.a_f1,units=self.n_actions,activation=tf.nn.softplus,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
self.a_mu = a_mu
self.a_sigma = a_sigma+0.01
# 定义带参数的正态分布
self.normal_dist = tf.contrib.distributions.Normal(self.a_mu,self.a_sigma)
# 根据正态分布采样一个动作
self.action = tf.clip_by_value(self.normal_dist.sample(1),action_bound[0],action_bound[1])
# 1.5 当前动作,输入为当前动作,delta
self.current_act = tf.placeholder(tf.float32,[None,1])
self.delta = tf.placeholder(tf.float32,[None,1])
# 2.构建损失函数
log_prob = self.normal_dist.log_prob(self.current_act)
self.a_loss = tf.reduce_mean(log_prob*self.delta+0.01*self.normal_dist.entropy())
# 3.定义一个动作优化器
self.a_train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(-self.a_loss)
# 4.定义Critic网络
self.c_f1 = tf.layers.dense(inputs=self.obs,units=100,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
self.v = tf.layers.dense(inputs=self.c_f1,units=1,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 定义Critic网络的损失函数,输入为td target
self.td_target = tf.placeholder(tf.float32,[None,1])
self.c_loss = tf.square(self.td_target-self.v)
self.c_train_op = tf.train.AdamOptimizer(0.0002).minimize(self.c_loss)
# 5.tf工程
self.sess = tf.Session()
# 6.初始化图中的变量
self.sess.run(tf.global_variables_initializer())
# 7.定义保存和恢复模型
self.saver = tf.train.Saver()
if model_file is not None:
self.restore_model(model_file)
# 动作采样函数,根据当前观测,返回当前策略的采样动作
def choose_action(self,state):
action = self.sess.run(self.action,{self.obs:state})
return action[0]
# 训练函数,利用采样数据训练Actor网络和Critic网络
def train_step(self,state,state_next,label,reward):
# 构建delta数据
gamma = 0.90
td_target = reward + gamma*self.sess.run(self.v,feed_dict={self.obs:state_next})[0]
delta = td_target - self.sess.run(self.v,feed_dict={self.obs:state})
c_loss,_ = self.sess.run([self.c_loss,self.c_train_op],feed_dict={self.obs:state,self.td_target:td_target})
a_loss,_ = self.sess.run([self.a_loss,self.a_train_op],feed_dict={self.obs:state,self.current_act:label,self.delta:delta})
return a_loss,c_loss
# 模型保存函数,保存模型
def save_model(self,model_path):
self.saver.save(self.sess,model_path)
# 模型恢复函数
def restore_model(self,model_path):
self.saver.restore(self.sess,model_path)
# 策略的训练函数
def policy_train(env,brain,training_num):
reward_sum = 0
reward_sum_line = []
training_time = []
average_reward = 0
for i in range(training_num):
observation = env.reset()
total_reward = 0
while True:
sample = Sample(env,brain)
# 采样数据
current_state,next_state,current_action,current_r,done,c_r = sample.sample_step(observation)
total_reward += c_r
# 训练AC网络
a_loss,c_loss = brain.train_step(current_state,next_state,current_action,current_r)
if done:
break
observation = next_state
if i == 0:
average_reward = total_reward
else:
average_reward = 0.95*average_reward + 0.05*total_reward
reward_sum_line.append(average_reward)
training_time.append(i)
print("number of episodes:%d,current average reward is %f"%(i,average_reward))
if average_reward > -400:
break
brain.save_model('./current_bset_pg_pendulum')
plt.plot(training_time,reward_sum_line)
plt.xlabel("training number")
plt.ylabel("score")
plt.show()
# 策略的测试函数
def policy_test(env,policy,RENDER):
observation = env.reset()
reward_sum = 0
# 将一个episode的回报存储起来
while True:
if RENDER:
env.render()
# 根据策略网络产生1个动作
state = np.reshape(observation,[1,3])
action = policy.choose_action(state)
observation_,reward,done,info = env.step(action)
if done:
break
observation = observation_
return reward_sum
if __name__ == '__main__':
# 创建环境
env_name = 'Pendulum-v0'
env = gym.make(env_name)
env.unwrapped
env.seed(1)
# 动作边界
action_bound = [-env.action_space.high,env.action_space.high]
# 实例化策略网络
brain = Policy_net(env,action_bound)
# 训练时间
training_num = 5000
# 策略训练
policy_train(env,brain,training_num)
# 测试训练好的策略
reward_sum = policy_test(env,brain,True)
结果

效果并不好,得分在很低的水平震荡,原因可能是:
- TD(0)评估存在很大偏差
- 单步更新不稳定
TD-AC算法代码解析
line 118
python">c_loss,_ = self.sess.run([self.c_loss,self.c_train_op],feed_dict={self.obs:state,self.td_target:td_target})
- sess.run() 中的feed_dict
- feed_dict的作用是给使用placeholder创建出来的tensor赋值。其实,他的作用更加广泛:feed 使用一个"值"临时替换一个"op"的输出结果。你可以提供 feed 数据作为 run() 调用的参数。feed 只在调用它的方法内有效,方法结束, feed 就会消失。
eg:
feed_dict={y:3})) #使用3 替换掉
Minibatch-MC-AC算法
python">import tensorflow as tf
import numpy as np
import gym
import matplotlib.pyplot as plt
RENDER = False
# 利用当前策略进行采样,产生数据
class Sample():
def __init__(self,env,policy_net):
self.env = env
self.brain = policy_net
self.gamma = 0.90
def sample_episode(self,num_episodes):
# 产生num_episodes条轨迹
batch_obs = []
batch_actions = []
batch_rs = []
# 一次episode的水平
batch = 200
mini_batch = 32
for i in range(num_episodes):
observation = self.env.reset()
# 将一个episode的回报存储起来
reward_episode = []
j = 0
k = 0
minibatch_obs = []
minibatch_actions = []
minibatch_rs = []
while j < batch:
# 采集数据
flag = 1
state = np.reshape(observation,[1,3])
action = self.brain.choose_action(state)
observation_,reward,done,info = self.env.step(action)
# 存储当前观测
minibatch_obs.append(np.reshape(observation,[1,3])[0,:])
# 存储当前动作
minibatch_actions.append(action)
# 存储立即回报
minibatch_rs.append((reward+8)/8)
k = k+1
j = j+1
if k==mini_batch or j == batch:
# 处理回报
reward_sum = self.brain.get_v(np.reshape(observation_,[1,3]))[0,0]
discounted_sum_reward = np.zeros_like(minibatch_rs)
for t in reversed(range(0,len(minibatch_rs))):
reward_sum = reward_sum * self.gamma + minibatch_rs[t]
discounted_sum_reward[t] = reward_sum
# 将mini-batch的数据存储在批回报中
for t in range(len(minibatch_rs)):
batch_rs.append(discounted_sum_reward[t])
batch_obs.append(minibatch_obs[t])
batch_actions.append(minibatch_actions[t])
k = 0
minibatch_obs = []
minibatch_actions = []
minibatch_rs = []
# 智能体往前推进一步
observation = observation_
# reshape观测和回报
batch_obs = np.reshape(batch_obs,[len(batch_obs),self.brain.n_features])
batch_actions = np.reshape(batch_actions,[len(batch_actions),1])
batch_rs = np.reshape(batch_rs,[len(batch_rs),1])
return batch_obs,batch_actions,batch_rs
class Policy_Net():
# 构建Actor神经网络模型和Critic神经网络模型
def __init__(self,env,action_bound,lr = 0.0001,model_file = None):
self.learning_rate = lr
# 输入特征的维数
self.n_features = env.observation_space.shape[0]
# 输出动作空间的维数
self.n_actions = 1
# 1.1 输入层
self.obs = tf.placeholder(tf.float32,shape=[None,self.n_features])
# 1.2 策略网络第1层,隐含层
self.a_f1 = tf.layers.dense(inputs=self.obs,units=200,activation=tf.nn.relu,\
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.3 第2层,均值
a_mu = tf.layers.dense(inputs=self.a_f1,units=self.n_actions,activation=tf.nn.tanh,\
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.4 第3层,标准差
a_sigma = tf.layers.dense(inputs=self.a_f1,units=self.n_actions,activation=tf.nn.softplus,\
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
self.a_mu = 2*a_mu
self.a_sigma = a_sigma
# 定义带参数的正态分布
self.normal_dist = tf.contrib.distributions.Normal(self.a_mu,self.a_sigma)
# 根据正态分布采样1个动作
self.action = tf.clip_by_value(self.normal_dist.sample(1),\
action_bound[0],action_bound[1])
# 1.5 当前动作,输入为当前动作delta
self.current_act = tf.placeholder(tf.float32,[None,1])
self.delta = tf.placeholder(tf.float32,[None,1])
# 2.构建损失函数
log_prob = self.normal_dist.log_prob(self.current_act)
self.a_loss = tf.reduce_mean(log_prob*self.delta)+0.01*self.normal_dist.entropy()
# 3.定义1个动作优化器
self.a_train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(-self.a_loss)
# 4.定义Critic网络
self.c_f1 = tf.layers.dense(inputs=self.obs,units=100,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
self.v = tf.layers.dense(inputs=self.c_f1,units=1,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 定义Critic网络的损失函数,输入为td目标
self.td_target = tf.placeholder(tf.float32,[None,1])
self.c_loss = tf.losses.mean_squared_error(self.td_target,self.v)
self.c_train_op = tf.train.AdamOptimizer(0.0002).minimize(self.c_loss)
# tf工程
self.sess = tf.Session()
# 6. 初始化图中的变量
self.sess.run(tf.global_variables_initializer())
# 7.定义保存恢复模型
self.saver = tf.train.Saver()
if model_file is not None:
self.restore_model(model_file)
# 动作采样函数
def choose_action(self,state):
action = self.sess.run(self.action,{self.obs:state})
#print("greedy action",action)
return action[0]
# 训练函数,与TD-AC不同的是数据连续使用10次进行更新
def train_step(self,state,label,reward):
td_target = reward
delta = td_target - self.sess.run(self.v,feed_dict={self.obs:state})
delta = np.reshape(delta,[len(reward),1])
for i in range(10):
c_loss,_ = self.sess.run([self.c_loss,self.c_train_op],feed_dict={self.obs:state,self.td_target:td_target})
for j in range(10):
a_loss,_ = self.sess.run([self.a_loss,self.a_train_op],feed_dict={self.obs:state,self.current_act:label,self.delta:delta})
return a_loss,c_loss,
# 模型保存
def save_model(self,model_path):
self.saver.save(self.sess,model_path)
# 状态值函数,估计行为值函数
def get_v(self,state):
v = self.sess.run(self.v,{self.obs:state})
return v
# 模型恢复函数
def restore_model(self,model_path):
self.saver.restore(self.sess,model_path)
# 策略的训练函数,迭代调用sample_step()和train_step()
# 假设平均回报大于-300时,Pendulum问题能得到解决
def policy_train(env,brain,sample,training_num):
reward_sum = 0
average_reward_line = []
training_time = []
average_reward = 0
current_total_reward = 0
for i in range(training_num):
current_state,current_action,current_r = sample.sample_episode(1)
brain.train_step(current_state,current_action,current_r)
current_total_reward = policy_test(env,brain,False,1)
if i == 0:
average_reward = current_total_reward
else:
average_reward = 0.95*average_reward + 0.05 *current_total_reward
average_reward_line.append(average_reward)
training_time.append(i)
if average_reward > -300:
break
print("current experiments%d,current average reward is %f"%(i,average_reward))
brain.save_model('./current_bset_pg_pendulum')
plt.plot(training_time,average_reward_line)
plt.xlabel("training number")
plt.ylabel("score")
plt.show()
# 策略的测试函数,直接用训练好的策略网络采样动作与环境进行交互并将交互画面渲染出来
def policy_test(env,policy,RENDER,test_number):
for i in range(test_number):
observation = env.reset()
if RENDER:
print("第%d次测试,初始状态:%f,%f,%f"%(i,observation[0],observation[1],observation[2]))
reward_sum = 0
# 将一个episode的回报存储起来
while True:
if RENDER:
env.render()
# 根据策略网络产生一个动作
state = np.reshape(observation,[1,3])
action = policy.choose_action(state)
observation_,reward,done,info = env.step(action)
reward_sum += reward
if done:
if RENDER:
print("第%d次测试总回报%f"%(i,reward_sum))
break
observation = observation_
return reward_sum
# 主函数
if __name__ == '__main__':
# 创建仿真环境
env_name = 'Pendulum-v0'
env = gym.make(env_name)
env.unwrapped
env.seed(1)
# 动作边界
action_bound = [-env.action_space.high,env.action_space.high]
# 实例化策略网络
brain = Policy_Net(env,action_bound)
# 实例化采样
sampler = Sample(env,brain)
# 训练时间最大为5000
training_num = 5000
# 测试随机初始化的个数
test_number = 10
# 利用Minibatcg-MC-AC算法训练神经网络
policy_train(env,brain,sampler,training_num)
# 测试训练好的神经网络
reward_sum = policy_test(env,brain,True,test_number)
结果:

current experiments2062,current average reward is -307.801025
经过训练后的神经网络可以控制倒立摆达到竖直位置,使Pendulum问题得到解决。然而,该AC算法需要大量的训练,且波动较大。如果让训练变得高效和稳定呢?PPO算法横空出世。
Minibatch-MC-AC算法代码解析
line 115
python">self.c_loss = tf.losses.mean_squared_error(self.td_target,self.v)
- tf.losses.mean_squared_error函数
python">tf.losses.mean_squared_error(
labels,
predictions,
weights=1.0,
scope=None,
loss_collection=tf.GraphKeys.LOSSES,
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
)
- tf.losses.mean_squared_error函数用于求MSE
- 定义在:tensorflow/python/ops/losses/losses_impl.py.
- 在训练过程中增加了平方和loss.
- 在这个函数中,weights作为loss的系数.如果提供了标量,那么loss只是按给定值缩放.如果weights是一个大小为[batch_size]的张量,那么批次的每个样本的总损失由weights向量中的相应元素重新调整.如果weights的形状与predictions的形状相匹配,则predictions中每个可测量元素的loss由相应的weights值缩放.
- 参数:
labels:真实的输出张量,与“predictions”相同.
predictions:预测的输出.
weights:可选的Tensor,其秩为0或与labels具有相同的秩,并且必须可广播到labels(即,所有维度必须为1与相应的losses具有相同的维度).
scope:计算loss时执行的操作范围.
loss_collection:将添加loss的集合.
reduction:适用于loss的减少类型. - 返回:
加权损失浮动Tensor.如果reduction是NONE,则它的形状与labels相同;否则,它是标量. - 可能引发的异常:
ValueError:如果predictions与labels的形状不匹配,或者形状weights是无效,亦或,如果labels或是predictions为None,则会引发此类异常. - tf.losses.mean_squared_error函数的功能就是先对于给定的两组数据做差,然后再进行elementwise的平方,最后进行elementwise相加并除以总element的个数。