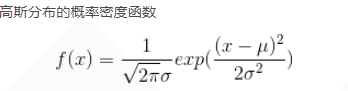Pendulum单摆系统MDP模型
- 该系统只包含一个摆杆,其中摆杆可以绕着一端的轴线摆动,在轴线施加力矩 τ \tau τ来控制摆杆摆动。
- Pendulum目标是:从任意状态出发,施加一系列的力矩,使得摆杆可以竖直向上。
- 状态输入为 s = [ θ , θ ˙ ] s=[\theta,\dot{\theta}] s=[θ,θ˙]
- 动作空间为 τ ∈ [ − 2 , 2 ] \tau\in[-2,2] τ∈[−2,2],连续空间
- 回报函数为 r = − θ 2 − 0.1 θ ˙ 2 − 0.001 τ 2 r=-{\theta}^2-0.1{\dot{\theta}}^2-0.001{\tau}^2 r=−θ2−0.1θ˙2−0.001τ2,其中 θ ∈ [ − π , π ] \theta\in[-\pi,\pi] θ∈[−π,π]
- 状态转移概率Pendulum的动力学方程由gym模拟器提供
代码
python">import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym
RENDER = False
# 利用当前策略进行采用,产生数据
class Sample():
def __init__(self,env,policy_net):
self.env = env
self.policy_net = policy_net
self.gamma = 0.90
def sample_episodes(self,num_episodes):
# 产生num_episodes条轨迹
batch_obs = []
batch_actions = []
batch_rs = []
for i in range(num_episodes):
observation = self.env.reset()
# 将一个episode存起来
reward_episode = []
while True:
# 根据策略网络产生一个动作
state = np.reshape(observation,[1,3])
action = self.policy_net.choose_action(state)
observation_,reward,done,info = self.env.step(action)
batch_obs.append(np.reshape(observation,[1,3])[0,:])
batch_actions.append(action)
reward_episode.append((reward+8)/8)
# 一个episode结束
if done:
# 处理回报函数
reward_sum = 0
discounted_sum_reward = np.zeros_like(reward_episode)
for t in reversed(range(0,len(reward_episode))):
reward_sum = reward_sum*self.gamma+reward_episode[t]
discounted_sum_reward[t] = reward_sum
# 归一化处理
discounted_sum_reward -= np.mean(discounted_sum_reward)
discounted_sum_reward /= np.std(discounted_sum_reward)
# 将归一化的数据存储在批回报中
for t in range(len(reward_episode)):
batch_rs.append(discounted_sum_reward[t])
break
# 智能体往前一步
observation = observation_
#reshape观测和回报
batch_obs = np.reshape(batch_obs,[len(batch_obs),self.policy_net.n_features])
batch_actions = np.reshape(batch_actions,[len(batch_actions),1])
batch_rs = np.reshape(batch_rs,[len(batch_rs),1])
return batch_obs,batch_actions,batch_rs
class Policy_net():
def __init__(self,env,action_bound,lr=0.0001,model_file=None):
self.learning_rate = lr
# 输入特征的维数
self.n_features = env.observation_space.shape[0]
# 输入动作空间的维数
self.n_actions = 1
# 1.1 输入层
self.obs = tf.placeholder(tf.float32,shape=[None,self.n_features])
# 1.2 第1层隐含层
self.f1 = tf.layers.dense(inputs=self.obs,units=200,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.3 第2层,均值,注意激活函数是tanh,使得输出在-1~+1
mu = tf.layers.dense(inputs=self.f1,units=self.n_actions,activation=tf.nn.tanh,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.3 第2层,标准差
sigma = tf.layers.dense(inputs=self.f1,units=self.n_actions,activation=tf.nn.softplus,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 均值乘以2,使得均值取值范围在(-2,2)
self.mu = 2 * mu
self.sigma = sigma
# 定义带参数的正态分布
self.normal_dist = tf.contrib.distributions.Normal(self.mu,self.sigma)
# 根据正态分布采样一个动作
self.action = tf.clip_by_value(self.normal_dist.sample(1),action_bound[0],action_bound[1])
# 1.4 当前动作
self.current_act = tf.placeholder(tf.float32,[None,1])
self.current_reward = tf.placeholder(tf.float32,[None,1])
# 2. 构建损失函数
log_prob = self.normal_dist.log_prob(self.current_act)
self.loss = tf.reduce_mean(log_prob*self.current_reward+0.01*self.normal_dist.entropy())
# 3. 定义一个优化器
self.train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(-self.loss)
# 4. tf工程
self.sess = tf.Session()
# 5. 初始化图中的变量
self.sess.run(tf.global_variables_initializer())
# 6. 定义保存和恢复模型
self.saver = tf.train.Saver()
if model_file is not None:
self.restore_model(model_file)
# 依照概率选择动作
def choose_action(self,state):
action = self.sess.run(self.action,{self.obs:state})
return action[0]
# 定义训练
def train_step(self,state_batch,label_batch,reward_batch):
loss,_ = self.sess.run([self.loss,self.train_op],feed_dict={self.obs:state_batch,self.current_act:label_batch,self.current_reward:reward_batch})
return loss
# 定义存储模型函数
def save_model(self,model_file):
self.saver.save(self.sess,model_file)
# 定义恢复模型函数
def restore_model(self,model_path):
self.saver.restore(self.sess,model_path)
# 策略网络的训练和测试
# 策略的训练函数policy_train()
def policy_train(env,brain,training_num):
reward_sum = 0
reward_sum_line = []
training_time = []
brain = brain
env = env
for i in range(training_num):
temp = 0
sampler = Sample(env,brain)
# 采样1个episode
train_obs,train_actions,train_rs = sampler.sample_episodes(1)
brain.train_step(train_obs,train_actions,train_rs)
if i == 0:
reward_sum = policy_test(env,brain,RENDER,1)
else:
reward_sum = 0.95 * reward_sum + 0.05 * policy_test(env,brain,RENDER,1)
reward_sum_line.append(reward_sum)
training_time.append(i)
print("training episodes is %d,trained reward_sum is %f"%(i,reward_sum))
if reward_sum > -900:
break
brain.save_model('./current_bset_pg_pendulum')
plt.plot(training_time,reward_sum_line)
plt.xlabel("training number")
plt.ylabel("score")
plt.show()
def policy_test(env, policy, RENDER, test_number):
for i in range(test_number):
observation = env.reset()
reward_sum = 0
# 将一个episode的回报存储起来
while True:
if RENDER:
env.render()
# 根据策略网络产生一个动作
state = np.reshape(observation,[1,3])
action = policy.choose_action(state)
observation_,reward,done,info = env.step(action)
reward_sum+=reward
if done:
break
observation = observation_
return reward_sum
if __name__ == '__main__':
# 构建Pendulum类
env_name = 'Pendulum-v0'
env = gym.make(env_name)
env.unwrapped
env.seed(1)
# 定义力矩取值区间
action_bound = [-env.action_space.high,env.action_space.high]
# 实例化一个策略网络
brain = Policy_net(env,action_bound)
training_num = 2000
# 训练策略网络
policy_train(env,brain,training_num)
# 测试训练好的策略网络
reward_sum = policy_test(env,brain,True,10)
- 结果:

- 策略梯度对Pendulum的控制不太好,需要探索更强的算法来实现这个任务。之后用AC来实现。
代码学习
line 66
python"> sigma = tf.layers.dense(inputs=self.f1,units=self.n_actions,activation=tf.nn.softplus,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
- 功能nn.softplus()[别名math.softplus]为Tensorflow中的softplus提供支持。
- 用法:
python">tf.nn.softplus(features, name=None) or tf.math.softplus(features, name=None)
- 参数:
features:以下任何类型的张量:float32,float64,int32,uint8,int16,int8,int64,bfloat16,uint16,half,uint32,uint64。
name(可选):操作的名称。 - 返回类型:与特征类型相同的张量
- nn激活函数(Activation Functions)
| 操作 | 描述 |
|---|---|
| tf.nn.relu(features, name=None ) | 整流函数:max(features, 0) |
| tf.nn.relu6(features, name=None) | 以6为阈值的整流函数:min(max(features, 0), 6) |
| tf.nn.elu(features, name=None) | elu函数,exp(features) - 1 if < 0,否则featuresExponential Linear Units (ELUs) |
| tf.nn.softplus(features, name=None) | 计算softplus:log(exp(features) + 1) |
| tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None) | 计算dropout,keep_prob为keep概率, noise_shape为噪声的shape |
| tf.nn.bias_add(value, bias, data_format=None, name=None) | 对value加一偏置量 此函数为tf.add的特殊情况,bias仅为一维, 函数通过广播机制进行与value和, 数据格式可以与value不同,返回为与value相同格式 |
| tf.sigmoid(x, name=None) | y = 1 / (1 + exp(-x)) |
| tf.tanh(x, name=None) | tf.tanh(x, name=None) |
- 参考:https://blog.csdn.net/qq_36653505/article/details/81105894
line 74
python"> self.action = tf.clip_by_value(self.normal_dist.sample(1),action_bound[0],action_bound[1])
- 语法:
python">tf.clip_by_value(v,a,b)
- 功能:可以将一个张量中的数值限制在一个范围之内。(可以避免一些运算错误)
- 参数:
v:input数据
a、b是对数据的限制。 - 当v小于a时,输出a;
当v大于a小于b时,输出原值;
当v大于b时,输出b;