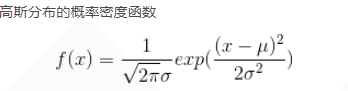小车倒立摆MDP模型
- 状态输入: s = [ x , x ˙ , θ , θ ˙ ] s = [x,\dot{x},\theta,\dot{\theta}] s=[x,x˙,θ,θ˙],维数为4
- 动作输出为 a = { [ 1 , 0 ] , [ 0 , 1 ] } a = \{[1,0],[0,1]\} a={[1,0],[0,1]}
- 回报函数: f ( x ) = { 1 i f s ∈ Ω 0 i f s ∉ Ω f(x)= \begin{cases} 1 & if s \in \Omega \\ 0 & if s \notin \Omega\\ \end{cases} f(x)={10ifs∈Ωifs∈/Ω
- 状态转移概率:小车倒立摆的动力学方程,由模拟器提供
代码
python">import numpy as np
import tensorflow as tf
import gym
import matplotlib.pyplot as plt
RENDER = False
# 创建一个采样类
class Sample():
# 对类初始化,初始化参数为仿真环境env,当前的策略网络policy_net
# 在初始化函数中定义折扣因子
def __init__(self,env,policy_net):
self.env = env
self.policy_net = policy_net
self.gamma = 0.98
# 创建一个采样函数,参数为所要采集的轨迹的数目
# 1.初始化环境,直接调用env.reset()
# 2.根据当前状态,调用当前策略产生动作
# 3.将策略产生的动作发送给模拟器,模拟器则根据状态和动作给出下一个状态,回报,及是否终止
# 4.如果终止则进入5,否则把下一个状态传到当前状态,进入2
# 5.一条轨迹结束,计算折扣累积回报,对折扣累积回报进行标准化处理,并将数据存入批数据集中,进入1采集下一条轨迹
def sample_episodes(self,num_episodes):
# 产生num_episode条轨迹
batch_obs = []
batch_action = []
batch_rs = []
for i in range(num_episodes):
observation = self.env.reset()
# 将一个episode的回报存储起来
reward_episode = []
while True:
if RENDER:self.env.render()
# 根据策略网络产生一个动作
state = np.reshape(observation,[1,4])
action = self.policy_net.choose_action(state)
observation_,reward,done,info = self.env.step(action)
batch_obs.append(observation)
batch_action.append(action)
reward_episode.append(reward)
# 一个episode结束
if done:
# 处理回报函数
reward_sum = 0
discounted_sum_reward = np.zeros_like(reward_episode)
for t in reversed(range(0,len(reward_episode))):
reward_sum = reward_sum*self.gamma+reward_episode[t]
discounted_sum_reward[t] = reward_sum
# 标准化处理
discounted_sum_reward -= np.mean(discounted_sum_reward)
discounted_sum_reward /= np.std(discounted_sum_reward)
# 将归一化的数据存储到批回报中
for t in range(len(reward_episode)):
batch_rs.append(discounted_sum_reward[t])
break
# 否则,智能体往前推进一步
observation = observation_
# 存储观测和回报
batch_obs = np.reshape(batch_obs,[len(batch_obs),self.policy_net.n_features])
batch_action = np.reshape(batch_action,[len(batch_rs),])
batch_rs = np.reshape(batch_rs, [len(batch_rs), ])
return batch_obs,batch_action,batch_rs
# Softmax策略
class Policy_Net():
# 初始化函数中完成网络模型的创建
# 1.根据神经网络的结构创建输入层,隐藏层,输出层
# 2.根据输出层构建损失函数
# 3.根据损失函数构建优化器
# 4.声明默认图
# 5.初始化图中的变量
# 6.创建保存和恢复模型
def __init__(self,env,model_file=None):
self.learning_rate = 0.01
# 输入特征的维数
self.n_features = env.observation_space.shape[0]
# 输出动作空间的维数
self.n_actions = env.action_space.n
# 1.1输入层
self.obs = tf.placeholder(tf.float32,shape=[None,self.n_features])
# 1.2第1层隐含层
self.f1 = tf.layers.dense(inputs=self.obs,units=20,activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.3第2层隐含层
self.all_act = tf.layers.dense(inputs=self.f1,units=self.n_actions,activation=None,kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
# 1.4最后一层softmax层
self.all_act_prob = tf.nn.softmax(self.all_act)
# 1.5监督标签
self.current_act = tf.placeholder(tf.int32,[None,])
self.current_reward = tf.placeholder(tf.float32,[None,])
# 2.构建损失函数
self.neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.all_act,labels = self.current_act)
self.loss = tf.reduce_mean(self.neg_log_prob*self.current_reward)
# 3.定义1个优化器
self.train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(self.loss)
# 4.tf工程
self.sess = tf.Session()
# 5.初始化图中变量
self.sess.run(tf.global_variables_initializer())
# 6.定义保存和恢复模型
self.saver = tf.train.Saver()
if model_file is not None:
self.restore_model(model_file)
# 贪婪动作函数
# 根据当前网络权值计算得到的概率最大的哪个动作,一般在测试网络的时候用
def greedy_action(self,state):
prob_weight = self.sess.run(self.all_act_prob,feed_dict={self.obs:state})
action = np.argmax(prob_weight,1)
print("greedy action",action)
return action[0]
# 训练函数
# 根据采样数据,利用梯度下降法对策略网络进行训练
def train_step(self, state_batch, label_batch, reward_batch):
loss, _, neg = self.sess.run([self.loss, self.train_op, self.neg_log_prob],
feed_dict={self.obs: state_batch, self.current_act: label_batch,
self.current_reward: reward_batch})
return loss, neg
# 定义存储模型函数
def save_model(self,model_path):
self.saver.save(self.sess,model_path)
# 定义恢复模型函数
def restore_model(self,model_path):
self.saver.restore(self.sess,model_path)
# 采样动作函数
# 因为当前策略为随机策略,采样动作策略是指根据当前动作概率分布采样一个动作。
# 智能体根据该函数采样动作从而与环境交互
def choose_action(self,state):
prob_weight = self.sess.run(self.all_act_prob,feed_dict={self.obs:state})
# 按照给定的概率采样
action = np.random.choice(range(prob_weight.shape[1]),p=prob_weight.ravel())
#print("action",action)
return action
# 策略的训练函数
# 迭代调用采样类中的采样函数sample_episodes()和策略网络类中的train_step()
def policy_train(env,brain,sample,training_num):
reward_sum = 0
reward_sum_line = []
training_time = []
for i in range(training_num):
temp = 0
training_time.append(i)
# 采样10个episodes
train_obs,train_actions,train_rs = sample.sample_episodes(10)
# 利用采样的数据进行梯度学习
loss, neg_log = brain.train_step(train_obs, train_actions, train_rs)
print("current loss is %f"%loss)
if i == 0:
reward_sum = policy_test(env,brain,False,1)
else:
reward_sum = 0.9*reward_sum + 0.1*policy_test(env,brain,False,1)
# print(policy_test(env,brain,False,1))
reward_sum_line.append(reward_sum)
print("training episodes is %d,trained reward_sum is %f"%(i,reward_sum))
if reward_sum >199:
break
brain.save_model('./current_bset_pg_cartpole')
plt.plot(training_time,reward_sum_line)
plt.xlabel("training number")
plt.ylabel("score")
plt.show()
# 策略的测试函数
# 直接用策略网络的贪婪动作与环境交互
def policy_test(env,policy,render,test_num):
for i in range(test_num):
observation = env.reset()
reward_sum = 0
# 将1个episode的回报存储起来
while True:
if render:
env.render()
# 根据策略网络产生1个动作
state = np.reshape(observation,[1,4])
action = policy.greedy_action(state)
observation_,reward,done,info = env.step(action)
reward_sum += reward
if done:
break
observation = observation_
return reward_sum
# 主函数
if __name__ == '__main__':
# 声明环境名称
env_name = 'CartPole-v0'
# 调用gym环境
env = gym.make(env_name)
env.unwrapped
env.seed(1)
# 下载当前最好的模型
#brain = Policy_Net(env,/.current_bset_pg_cartpole)
# 实例化策略函数
brain = Policy_Net(env)
# 实例化采样函数
sampler = Sample(env,brain)
# 训练次数
training_num = 150
# 训练策略网络
policy_train(env, brain, sampler, training_num)
# 测试策略网络,随机生成10个初始化状态进行测试
reward_sum =policy_test(env,brain,True,10)
环境
python">import pygame
import numpy as np
from load import *
from pygame.locals import *
import math
import time
class CartPoleEnv:
def __init__(self):
self.actions = [0,1]
self.state = np.random.uniform(-0.05,0.05,size=(4,))
self.steps_beyond_done = 0
self.viewer = None
# 设置帧率
self.FPSCLOCK = pygame.time.Clock()
self.screen_size = [400,300]
self.cart_x = 200
self.cart_y = 200
self.theta = -1.5
self.gravity = 9.8
self.mass_cart = 1.0
self.mass_pole = 0.1
self.total_mass = (self.mass_cart+self.mass_pole)
self.length = 0.5
self.pole_mass_length = (self.mass_pole*self.length)
self.force_mag = 10.0
self.tau = 0.02
# 角度阈值
self.theta_threshold_radians = 12*2*math.pi/360
# x方向阈值
self.x_threhold = 2.4
# 环境的随机初始化,以便开始进行新的实验
def reset(self):
n = np.random.randint(1,1000,1)
np.random.seed(n)
self.state = np.random.uniform(-0.05,0.05,size=(4,))
self.steps_beyond_done = 0
print(self.state)
return np.array(self.state)
# 智能体与环境交互
def step(self,action):
state = self.state
x,x_dot,theta,theta_dot = state
force = self.force_mag if action == 1 else -self.force_mag
costheta = math.cos(theta)
sintheta = math.sin(theta)
# 动力学方程
temp = (force+self.pole_mass_length*theta_dot*theta_dot*sintheta)/self.total_mass
thetaacc = (self.gravity*sintheta-costheta*temp)/(self.length*(4.0/3.0-self.mass_pole*costheta*costheta/self.total_mass))# 角加速度
xacc = temp - self.pole_mass_length*thetaacc*costheta/self.total_mass
# 积分得到状态量
x = x + self.tau* x_dot
x_dot = x_dot + self.tau*xacc
theta = theta + self.tau*theta_dot
theta_dot = theta_dot + self.tau*thetaacc
self.state = (x,x_dot,theta,theta_dot)
# 根据更新的状态判断是否结束
done = x < -self.x_threhold or x>self.x_threhold or theta < -self.theta_threshold_radians or theta > self.theta_threshold_radians
done = bool(done)
# 设置回报
if not done:
reward = 1.0
self.steps_beyond_done = self.steps_beyond_done + 1
else:
reward = 0.0
return np.array(self.state),reward,done
def gameover(self):
for event in pygame.event.get():
if event.type == QUIT:
exit()
# 渲染和显示环境
def render(self):
screen_width = self.screen_size[0]
screen_height = self.screen_size[1]
world_width = self.x_threhold * 2
scale = screen_width/world_width
state = self.state
self.cart_x = 200 + scale*state[0]
self.cart_y = 200
self.theta = state[2]
if self.viewer is None:
pygame.init()
self.viewer = pygame.display.set_mode(self.screen_size,0,32)# 第一个参数为窗口的分辨率,第二个参数为窗口的性质,第三个参数为色深,返回值为viewer
self.background = load_background()
self.pole = load_pole()
# 画背景
self.viewer.blit(self.background,(0,0))# 第一个参数为要画的参数名,第二个参数为图片左上角坐标
self.viewer.blit(self.pole,(195,80))
pygame.display.update()# 该函数在图片画到幕布后调用,否则要画的图不会显示
# 循环绘图
self.viewer.blit(self.background,(0,0))
# 画线
pygame.draw.line(self.viewer,(0,0,0),(0,200),(400,200))#第一个参数为幕布,第二个参数为直线的颜色,第三个参数为直线的起始坐标,第四个参数为直线结束坐标
# 画圆
#pygame.draw.circle(self.viewer,(255,0,0),(200,200),1)##第一个参数为幕布,第二个参数为颜色,第三个参数为圆心坐标,第四个参数为圆的半径
# 画矩形
pygame.draw.rect(self.viewer,(255,0,0),(self.cart_x-20,self.cart_y-15,40,30))#第一个参数为幕布,第二个参数为颜色,第三个参数为最左侧x坐标,和最右侧y坐标,矩形的长度,矩形的宽度
# 图像旋转
pole1 = pygame.transform.rotate(self.pole,-self.theta*180/math.pi)# 第一个参数为要旋转的图像,第二个参数为要旋转的角度
if self.theta >0:
pole1_x = self.cart_x-5*math.cos(self.theta)
pole1_y = self.cart_y-80*math.cos(self.theta)-5*math.sin(self.theta)
else:
pole1_x = self.cart_x+80*math.sin(self.theta)-5*math.cos(self.theta)
pole1_y = self.cart_y-80*math.cos(self.theta)+5*math.sin(self.theta)
self.viewer.blit(pole1,(pole1_x,pole1_y))
pygame.display.update()
self.gameover()
self.FPSCLOCK.tick(30)


代码解析
line 40
python">discounted_sum_reward = np.zeros_like(reward_episode)
np.zeros_like(x):输入为矩阵x,输出为形状和x一致的矩阵,其元素全部为0
line 41
python"> for t in reversed(range(0,len(reward_episode))):
- reversed()函数的作用是返回一个反转的迭代器(元组、列表、字符串、range)。
- 语法:
python">reversed(seq)
- 参数
seq — 需要转换的序列,如元组、列表、字符串、range - 返回值:
返回反转的迭代器
line 93
python">neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.all_act,labels = self.current_act)
- 语法:
python">tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None)
- 计算logits 和 labels 之间的稀疏softmax 交叉熵
- logits 必须具有shape [batch_size, num_classes] 并且 dtype (float32 or float64)
labels 必须具有shape [batch_size],并且 dtype int64 - 参数:
logits: 无尺度化的log概率
labels: 每个条目 labels[i] 必须是[0, num_classes) 的索引或者-1. 如果是-1,则相应的损失为0,不用考虑 logits[i] 的值。 - 返回值:
batch_size 长度的1-D Tensor,type 类型和 logits 一样,值为softmax 交叉熵损失。
line 94
python"> self.loss = tf.reduce_mean(neg_log_prob*self.current_reward)
- tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
- 语法
python">reduce_mean(input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None)
- 参数
input_tensor: 输入的待降维的tensor;
axis: 指定的轴,如果不指定,则计算所有元素的均值;
keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度;
name: 操作的名称;
reduction_indices:在以前版本中用来指定轴,已弃用; - 如果不指定第二个参数,那么就在所有的元素中取平均值
- 如果指定第二个参数为0,则第一维的元素取平均值,即每一列求平均值
line 136
python"> action = np.random.choice(range(prob_weight.shape[1]),p=prob_weight.ravel())
- 语法
python">numpy.random.choice(a, size=None, replace=True, p=None)
- 从a(只要是ndarray都可以,但必须是一维的)中随机抽取数字,并组成指定大小(size)的数组
- replace:True表示可以取相同数字,False表示不可以取相同数字
- 数组p:与数组a相对应,表示取数组a中每个元素的概率,默认为选取每个元素的概率相同。
- 参考:https://blog.csdn.net/ImwaterP/article/details/96282230
line 198
python"> env.unwrapped()
- Open AI gym提供了许多不同的环境。每一个环境都有一套自己的参数和方法。然而,他们通常由一个类Env包装(就像这是面向对象编程语言(OOPLs)的一个接口)。这个类暴露了任一环境的最常用的,最本质的方法,比如step,reset,seed。拥有这个“接口”类非常好,因为它允许您的代码不受环境限制。如果您希望在不同的环境中测试单个代理,那么它还使事情变得更简单。
然而,如果你想访问一个特定环境的场景动态后面的东西,需要使用unwrapped属性。 - 参考:https://blog.csdn.net/qq_32893343/article/details/103694468
line 36
python"> n = np.random.randint(1,1000,1)
- 语法:
python">numpy.random.randint(low, high=None, size=None, dtype=’l’)
- 输入:
low—–为最小值
high—-为最大值
size—–为数组维度大小
dtype—为数据类型,默认的数据类型是np.int。 - 返回值:
返回随机整数或整型数组,范围区间为[low,high),包含low,不包含high;
high没有填写时,默认生成随机数的范围是[0,low) - 参考:https://blog.csdn.net/QFJIZHI/article/details/103435445
line 37
python"> np.random.seed(n)
- seed( ) 是用于指定随机数生成时所用算法开始的整数值,如果采用相同的随机数种子,生成的随机数是相同的。这里随机数种子为n,则每次都不同。