爬虫提前准备包
1)安装解析库lxml
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
命令行进行安装:pip install lxml
2)requests库,安装:pip install requests
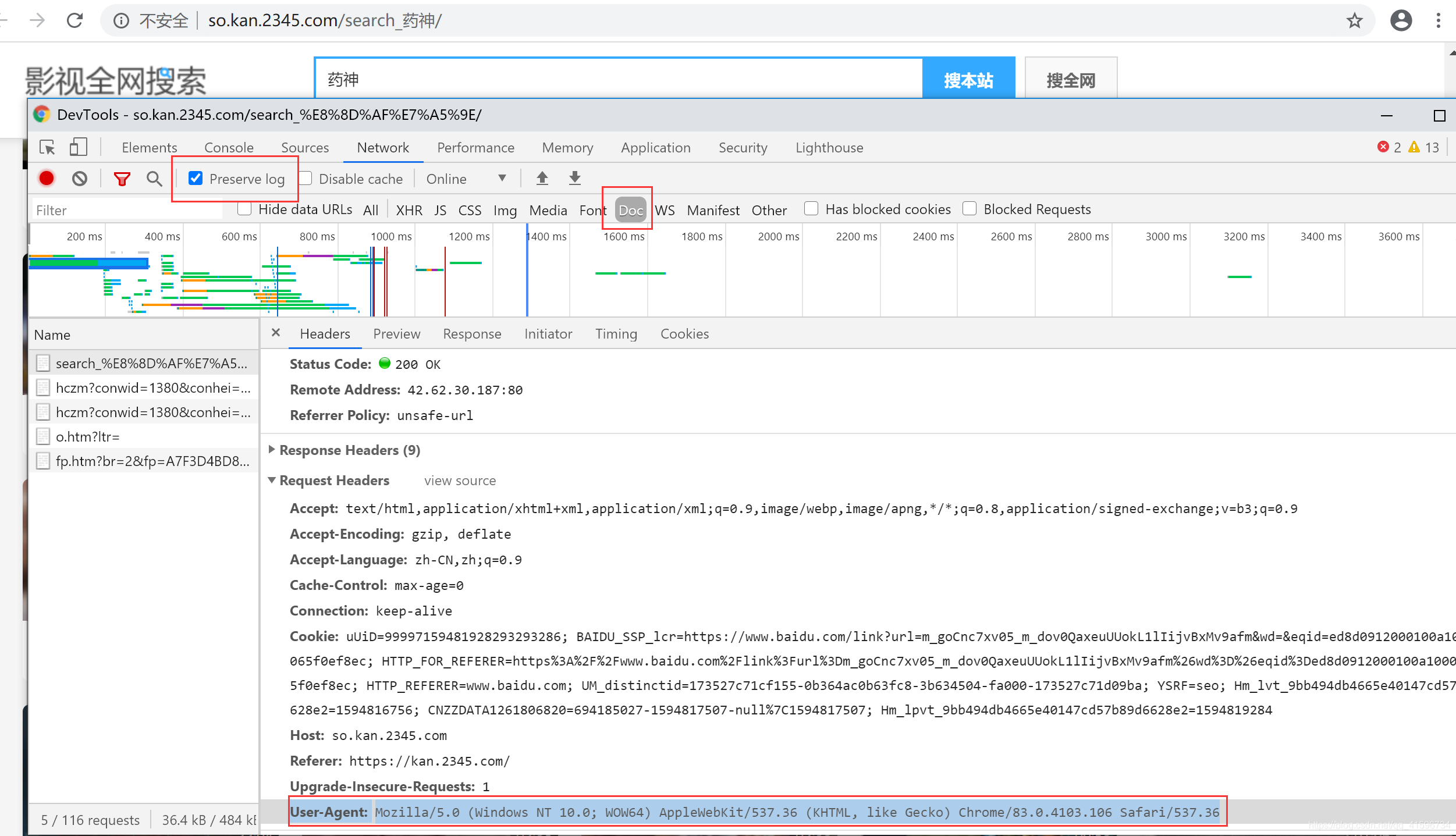
获取信息user-agent
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
使用User-Agent可以将爬虫模拟成用户操作计算机,防止爬虫被封。而短时间进行大量访问也有可能被封掉,而自动生成UA可以有效解决这个问题。
进入2345影视:控制台打开获取user-agent
爬取2345影视经典电影信息,代码块如下
python">#coding:utf-8
import requests
from lxml import etree
from urllib.parse import urljoin #url拼接
from getcsv import getcsv
def get_html(url):
'''
获取源代码
:param url:
:return:
'''
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"}
response=requests.get(url,headers=headers)
#response是2开头,即返回response,否则返回None
return response.text if str(response.status_code).startswith("2") else None
def get_detail_url_list(url):
'''
获取电影详情页url
:param url:
:return:
'''
#获取页面
html=get_html(url)
#如果没有获取页面,返回为空
if not html:
print("Response状态码不是200")
return
#解析获取的页面
parser=etree.HTML(get_html(url))
#获取详情页面的url
detail_urls=[urljoin(url,i) for i in parser.xpath("//ul[contains(@class,'v_picTxt')]/li/div[@class='pic']/a/@href")]
#翻页去最后一页
next_page_tag=parser.xpath("//div[@class='v_page']/a[last()]")
#到最后一页,获取最后一页
if next_page_tag:
next_page_tag=next_page_tag[0]
#如果next_page_tag文本有下一页(最后页是由下一页),就返回路径,否则返回为空
next_page_url=urljoin(url,next_page_tag.attrib.get("href")) if "下一页" in next_page_tag.text else None
return next_page_url,detail_urls
def parse_detail(url):
'''
解析详情页的url
xpath定位是从1开始的
:param url:
:return:
'''
html = get_html(url)
if not html:
print("Response状态码不是200")
return
#获取信息路径
Etree=etree.HTML(html)
title = "".join(Etree.xpath("//div[@class='tit']/h1/text()"))
# print(type(title))
score = Etree.xpath("//div[@class='tit']/p/em/text()")[0].replace("分", "")
actor = " ".join(Etree.xpath("//ul[contains(@class,'txtList')]/li[contains(@class,'liActor')]/a/text()"))
director = "".join(Etree.xpath("//ul[contains(@class,'txtList')]/li[@class='li_3']/a/text()"))
introduction = "".join(Etree.xpath("//ul[contains(@class,'newIntro')]/li/p/span/text()"))
# 多个list合并成一个list
list = [title,actor,director,introduction]
#一个大的list每4个分割成1个list
lists=list_split(list,4)
# print(title)
return lists
#切割列表
def list_split(items, n):
return [items[i:i+n] for i in range(0, len(items), n)]
def spider():
next_url = "https://dianying.2345.com/list/jingdian------.html"
datas=[]
# 详情页,下一页结果
while next_url:
next_url, urls = get_detail_url_list(next_url)
# print(urls)
# print(type(urls))
for url in urls:
# print(url)
#添加数据在数组datas
datas.extend(parse_detail(url))
# return parse_detail(url)
return datas
if __name__ == '__main__':
import time
datas1=spider()
path = 'data.csv'
title = ['电影名', '演员', '导演', '简介']
w_data = getcsv().write_csv(path, title, datas1)
getcsv.py 代码块如下:
python">#coding:utf-8
import csv
import os
#利用pandas包来按照列写入csv文件
import pandas as pd
class getcsv:
def write_csv(self,file_path,title,datas):
with open(file_path, 'a', encoding='utf-8', newline='') as f:
# rows=f.readlines()
# for row in rows:
try:
csv_write = csv.writer(f, dialect='excel')
# 写入列名
csv_write.writerow(title)
# 写入多行
csv_write.writerows(datas)
except FileNotFoundError as e:
print('指定的文件无法打开')
except IOError as e:
print(e)
print("文件写入错误")
学习资料:https://ke.qq.com/webcourse/index.html#cid=396790&term_id=100473305&taid=3423527021972982&vid=5285890799988610488
![[java设计模式简记] 策略模式(Strategy-Pattern)](/images/no-images.jpg)



