1.基本概念
Markov Chain/Markov process:具有马尔可夫性质的随机过程。
Markov Property用公式表示为: P(st+1 | st, st-1, …) = P(st+1 | st)。简单说就是当前时刻的状态仅仅和上一个时刻的状态有关。这个性质感觉更多的是从工程上考虑问题得出的,因为这样可以极大的简化计算,并且有一定的合理性。
State Transition Matrix:状态转移概率矩阵定义了所有状态的转移概率。
![]()

很明显,转移矩阵中每一行的概率和为1。
Markov Reward Process:Markov Chain + Reward。 在两个状态之间发生转移的时候,会得到一个奖励。

Markov Decision Process: Markov Chain + + Action + Reward.两个相邻状态之间的转移受Action的影响,而且转移完成之后会得到一个reward

一个完整的MDP过程描述如下:

MDP可以由一个四元组来表示<S,A,P,R>。其中S表示的是状态集合,A表示的是动作集合,P是概率转移矩阵,表示两个状态之间转移的概率,R为两个状态发生转移后的奖励。
MDP动态特征:这里引入一个MDP动态特征的概念,通过这一概念将S,A,P,R四个变量联系起来来表示MDP的过程。
![]()
我们之前提到过,马儿可夫特性更多的是从工程的角度出发。从上面的式子也可以看出,我们仅仅使用当前的一个状态就可以预估下一个状态的收益,这样在实际应用中会极大的简化计算过程。而且根据经验,只使用当前状态进行预测评估并不会比使用过去历史所有的状态去评估差很多。
2.MDP中的策略
强化学习的核心就是策略,而MDP的目标就是想要找到最优策略。那么什么是Policy?Policy可以简单的理解为对action如何选择。Policy用来表示,它分为两类
1.确定性策略,表示输出的动作是确定的a = (s)
![]()
表示当处在state s的时候我就选action a。比如红灯停,绿灯行,你的action在这个状态下是唯一的。
2.随机性策略,![]()
表示当处在state s的时候 选择不同action的概率。比如开车到了一个3岔路,直行的概率是0.5,左转的概率是0.3,右转的概率是0.2。此时输出的是动作a的概率分布。
确定性策略是随机性策略的一个特例。知道什么是策略以后,什么样的策略才是 好的?
比较简单的一个衡量方法就是看Reward,比如上图执行A1之后得到R2,R2越大可以认为这个A1也就是这个策略越好,但是这种只考虑R2的方法是有些问题的,因为有些时候Reward是有延时性的,你在S1选择了A1,产生了R2,但之后产生的收益R3,R4,甚至一直到Rt都是有可能受你在S1上这个A1影响的,所以我们引入了一个新的变量来衡量策略的好坏,这个变量就是回报。

我们现在展开来看下S3到S4这一个状态转移过程,我们假设每个State都有3个状态,每个action也有3个选择的可能,那么上面这一过程的展开图就如下所示:

上面每一条路径就是一种状态转移的可能,因为我们每个state有3个状态,每个action有3种选择,所以实际一共可能有9种转移可能,我们可以将其记为,我们会发现我们无法用单独的一个Gt来衡量一个策略的好坏,所以我们又引入了一个新的概念,价值函数,定义为:从 s 状态开始的在 π 策略下获得的所有路径回报的期望。

3. 贝尔曼期望方程
表示的是当到达某个状态s 之后,如果接下来一直按着策略π 来行动,能够获得的期望收益。
实际上还有另外一个价值函数,它引入了状态action,叫做动作状态价值函数。它表示的是到达某个状态S之后,如果采取行动a,接下来再按照策略π来行动,能够获得的期望收益。
![]()
这两种价值函数之间有什么关系呢?
3.1 state->action的关系

上图中,空心较大圆圈表示状态,黑色实心小圆表示的是动作本身,连接状态和动作的线条仅仅把该状态以及该状态下可以采取的行为关联起来。
从当前state s按照策略π选取一个action a会产生一个动作价值函数,
(a|s)表示选择每个action的概率,从上图的关系也可以看出来
就是
,
(a|s)的加权求和。

两者之间还有一层显而易见的关系。
3.2 action->state的关系

从上图可以看出从到
的回报有两部分,一部分是在State s采取action a 离开s 之后的reward r,我们可以把他看做是采用action a 离开state s之后的及时回报,另一部分就是折扣因子
乘以
的长期回报。这也符合我们上面对于回报的定义。在加上从state s采取action a到达 state
的状态转移概率为
,我们可以得出二者的关系如下:

现在我们已经得出了如下关系公式:

我们可以用替换
中的
,也可以用
替换
中的
,由此有得出下面的公式:

我们可以用下面两个关系图来加深理解:


这两个公式就是贝尔曼期望方程。
4.贝尔曼最优方程
上一小节中,主要介绍了价值函数和状态价值函数之间的关系,并推导出了两个Bellman 期望方程。注意,强化学习的目的就是找到最优的π,算法中可以优化的也只有π。我们把值最大的价值函数称为最优价值函数。

这个值函数得到的策略就是最佳策略:

最优策略可能存在多个。因为两个不同的action可能对应的收益是一样的。
由上面2个式子我们可以得到:

同时需要注意的是,V ∗(s) 和V π∗(s) 看上去是一模一样的,实际上它们分别属于不同的意义。最优价值函数V ∗(s) 隐去了策略和π 没有关系,它仅仅是一个函数。而V π∗(s) 是一个普通的价值函数,它表示的是由最优的策略π 得出的价值函数。
我们前面讲到过讲到了V 函数是Q 函数的一个加权平均,他们之间的关系如下:

由于π∗ 是一个最优的策略,所以直觉上我们认为下面等式应该成立:

这个式子是成立,具体的推导过程就不在这展开了,我们可以用一个简单的反证法来证明,如果V π∗(s) < maxa Qπ∗(s, a) 那意味着平均值小于最大值,则说明π∗肯定还有提高的空间,则不是最优策略。必然存在一个πnew ̸= π∗ 使得πnew = max,这显然与π∗ 是最优策略的前提是矛盾的。
结合上面3个式子我们可以得出:

在加上q*的定义:

二者结合,得出了最终的贝尔曼最优方程:



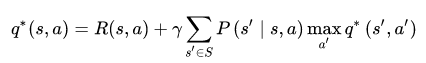
因为只有action是我们可以控制选择的,而且max也是选取价值函数最大的action。所以两个式子max的作用域稍有区别,结合上面两个回溯图可以更好的理解这两个公式。
Bellman最优方程是非线性的,没有固定的解决方案,通过一些迭代方法来解决:价值迭代、策略迭代,后面的章节我们会一一展开讲解。