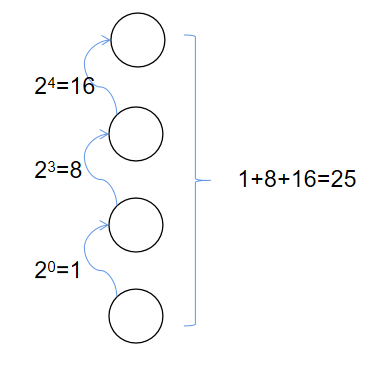
前几章我们所讨论的强化学习方法都是将价值函数建模为一个table形式,通过状态
来查询具体状态的价值。但是当状态-动作空间极大,且多数状态-动作并没有太大意义时,这种table查询效率是极低的。
因此本节是将价值函数建模为一个参数模型,其中
是该价值预估模型的参数,而状态
是价值预估模型的输出,通过模型来输出该状态的价值预估。
1. supervised learning
那么如何来学习这个模型,该模型主要在于拟合状态的价值,该价值可以表示为最优动作决策下的最优收益。为了拟合这个函数,采用来监督学习的方式,定义如下学习损失The Prediction Objective (VE):
上式中的表示状态s的出现概率,满足
,假设
表示单个episode中状态s的平均出现次数,
表示状态s出现在单个episode的初始状态的概率。
2. Stochastic-gradient and Semi-gradient Methods
求解模型参数采用SGD的进行优化:
上式中的表示在决策函数
下的状态价值,我们可以通过MC方法通过采样获得累积奖励来计算。

另一种方法是通过TD或者DP算法类似的bootstrapping方法,通过一个预估值来取代真实采样的累积收益
。这种方式称为Semi-gradient Methods。
- 动态规划:
- TD(0):
- TD(n):

3. Episodic Semi-gradient Control
前面讨论了如何通过模型来估计价值函数,接下来我们很容易结合GPI策略,构造value estimate、policy improve的两步强化学习过程TD(0) on-policy sarsa:

同时TD(n) on-policy sarsa可以表示为如下,可以看出其主要是将原来的table方法中的值更新替换为价值预估模型中参数更新。

4. Average Reward: Continuing Tasks
之前在求解累积收益时,引入了一个折扣因子
,其主要有两部分原因:一是为了避免累积收益值不收敛,另一个是考虑到近期收益影响更大。然而当面临一个连续动作场景(没有开始状态以及最终状态)时,后者假设就是有问题的,特别是处于某种均衡的摇摆状态时,添加折扣将会丢失未来的状态信息。因此存在另一式Average Reward的方式,其也可以避免累积收益值不收敛。
首先定义决策下的平均收益:
此外定义了差分累积收益:
TD(n)形式下可以定义为:
平均收益可以如下方式进行迭代:
此时基于TD(n)的on-policy Sarsa的算法描述如下: