Q-Learning项目实战
一. 概述
上一篇概念文章讲解了算法的概念和原理:Q-Learning 原理干货讲解
本文将进行项目实战讲解,分别为:
- 单路径吃宝箱问题
- 棋盘格吃宝箱问题
- 拓扑节点较优路径问题
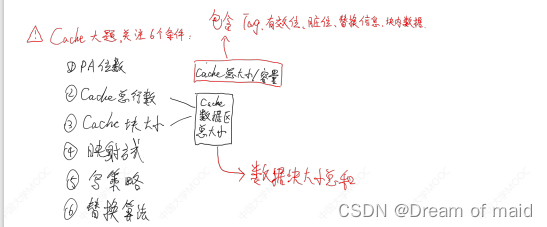
Q-Learning算法的本质还是下面这个公式,需要牢牢记住
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Pwj5DXE-1687940124443)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230625093857183.png)]](https://img-blog.csdnimg.cn/1c7a0b337a864bff889941d08b9ff1f7.png)
二. 实战
2.1 单路径吃宝箱问题
场景描述
小人吃宝箱,小人可以通过左右移动来吃到宝箱,初始状态下小人是无法往左侧移动的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cNXYEsQA-1687940192835)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230628154110816.png)]](https://img-blog.csdnimg.cn/05396c9e7ff24b869a3b5e0b1a69912f.png)
项目代码
项目代码:GitHub:单路径吃宝箱问题
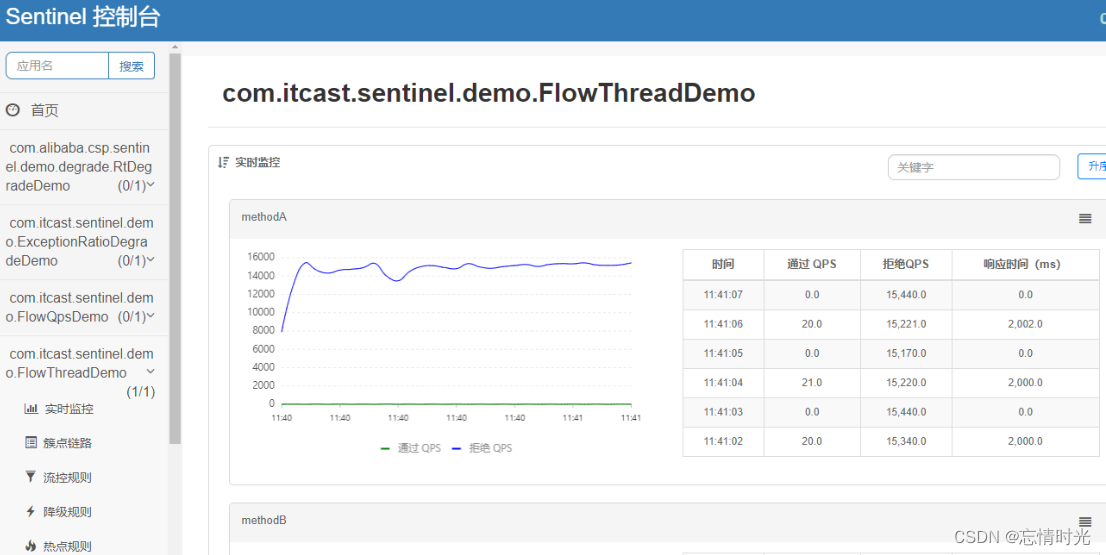
部分运行结果截图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-te3LeL40-1687940192836)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230628152433529.png)]](https://img-blog.csdnimg.cn/a0d6eb5e2dfe4de2a053e998d67558df.png)
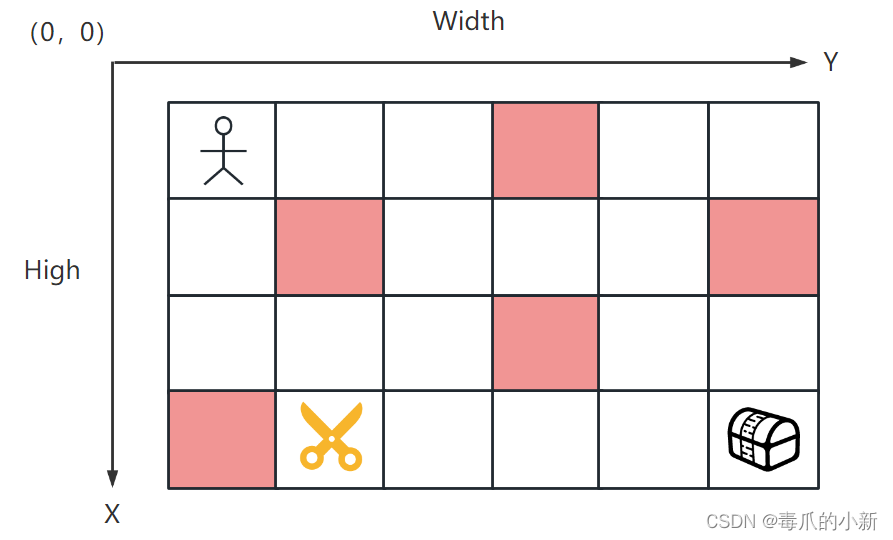
2.2 棋盘格吃宝箱问题
场景描述
这个案例是上个一条路吃宝箱案例的升级版。在本项目案例中,最终目的还是小人吃到宝箱,但是增加了几个场景:红色方块表示障碍,无法被穿越;黄色剪刀表示陷阱,走入陷阱直接失败。小人可以通过上下左右进行移动,但是不能创越周围的墙体。
项目代码
项目代码:GitHub:棋盘格吃宝箱问题
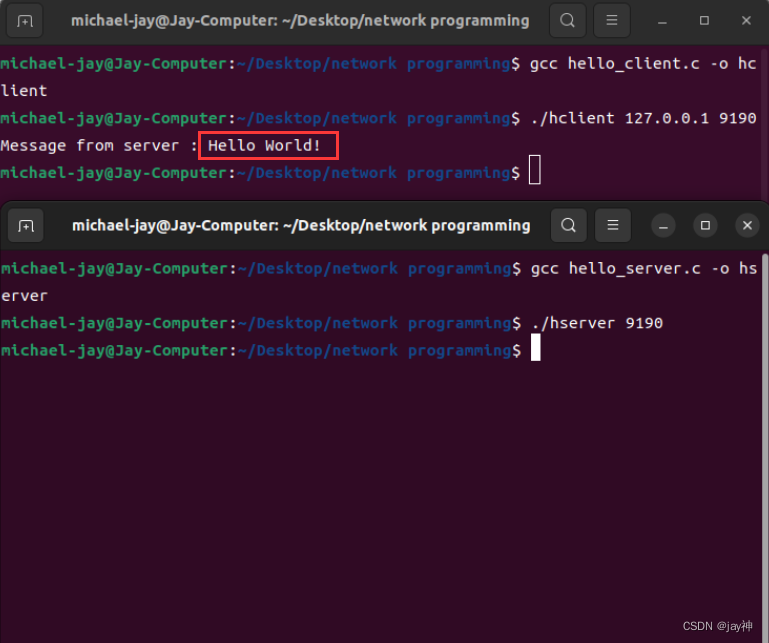
部分运行结果截图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R97t0p4Q-1687940192838)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230628152249873.png)]](https://img-blog.csdnimg.cn/a90ea3d4615f45d2a6618cc9156611f7.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MDfogI9x-1687940192839)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230628152218439.png)]](https://img-blog.csdnimg.cn/5b233d8c526c4032a8b91034de3ad032.png)
2.3 拓扑节点较优路径问题
场景描述
经典的拓扑路径问题,在有向图中从源节点到目的节点找到一条较优路径,其中有向连线上的值可以依据实际情况理解为奖励或者代价

说明
注意:这里为什么是较优路径而不是最优路径,因为Q-Learning算法本身就是一个探索性的强化学习算法,以探索及状态为主,所以找出的路径和最终的Q表与学习率、迭代次数以及算法本事的随机性有关
项目代码
项目代码:GitHub:拓扑节点较优路径问题
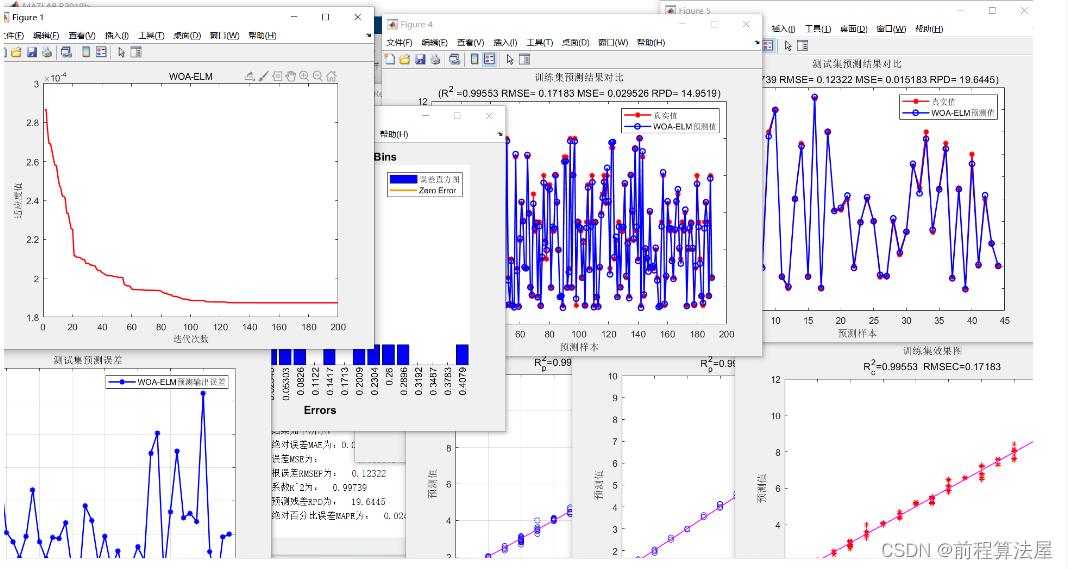
部分运行结果截图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t6OdSXhk-1687940192840)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230628153929993.png)]](https://img-blog.csdnimg.cn/66c3c4d7fd344162bfc6d4b6f7279c06.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jbmaNuIP-1687940192841)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230628153940994.png)]](https://img-blog.csdnimg.cn/aa50365b532a4449b789f8868aa41ea5.png)
三. 参考文献
本次学习参考了部分文章,较原始代码进行了部分改良或全部改良,添加了大量注释方便初学者学习,原参考文章链接:
Q-Learning解决最短路径问题