论文:《Combining Deep Reinforcement Learning and Search for Imperfect-Information Games》
地址:https://arxiv.org/abs/2007.13544v2
代码:https://github.com/facebookresearch/rebel
材料:
- BV1gt4y1k77C(1小时12分钟)
- BV1hM4y1D7SW(35分钟)
论文的贡献:
- 一种应用在不完美信息二人零和博弈中的 RL+Search 算法;(ReBel、定理2)
- 为安全搜索算法提供了一种新的选择;(定理3)
- 使用 CFR-AVG 分解子博弈;
- 揭示了 PBS 梯度与 infostates value 之间的联系;(定理1)
- 一种新的虚拟博弈算法:虚拟线性乐观博弈算法(Fictitious Linear Optimistic Play, FLOP)
一些概念
- w ∈ W w\in \mathcal{W} w∈W,世界状态(World State),游戏中的一个状态;
- A = A 1 × A 2 × ⋯ A N \mathcal{A}=\mathcal{A}_1\times\mathcal{A}_2\times\cdots\mathcal{A}_N A=A1×A2×⋯AN,N 个 agent 联合行为的空间;
- a = ( a 1 , a 2 , ⋯ , a N ) ∈ A a=(a_1,a_2,\cdots,a_N)\in\mathcal{A} a=(a1,a2,⋯,aN)∈A,N 个 agent 的一种联合行为;
- T ( w , a ) ∈ Δ W \mathcal{T}(w,a)\in\Delta\mathcal{W} T(w,a)∈ΔW,输运函数,它是一个概率分布,在当前的世界状态 w 下选定 a 之后,负责决定下一个世界状态 w’;
- R i ( w , a ) \mathcal{R}_i(w,a) Ri(w,a),agent i 的在 (w,a) 时获得的奖励;
- O p r i v ( i ) ( w , a , w ′ ) \mathcal{O}_{priv(i)}(w,a,w') Opriv(i)(w,a,w′),agent i 在 a 的作用下从 w 转至 w’ 后获得的私人观测(Private Observation);
- O p u b ( w , a , w ′ ) \mathcal{O}_{pub}(w,a,w') Opub(w,a,w′),所有 agent 获得的公共观测(Public Observation);
- h = ( w 0 , a 0 , w 1 , a 1 , ⋯ , w t ) h=(w^0,a^0,w^1,a^1,\cdots,w^t) h=(w0,a0,w1,a1,⋯,wt),历史(History),合理行为与世界状态的一个有限序列;
-
s
i
=
(
O
i
0
,
a
i
0
,
O
i
1
,
a
i
1
,
⋯
,
O
i
t
)
s_i=(O_i^0,a_i^0,O_i^1,a_i^1,\cdots,O_i^t)
si=(Oi0,ai0,Oi1,ai1,⋯,Oit),infostate,agent i 的观测与行为的序列,
其中, O i k = ( O p r i v ( w k − 1 , a k − 1 , w k ) , O p u b ( w k − 1 , a k − 1 , w k ) ) O_i^k=(O_{priv}(w^{k-1},a^{k-1},w^k), O_{pub}{(w^{k-1},a^{k-1},w^k)}) Oik=(Opriv(wk−1,ak−1,wk),Opub(wk−1,ak−1,wk))
- s i ( h ) s_i(h) si(h) 是在 h 下 agent i 唯一的 infostate, H ( s i ) \mathcal{H}(s_i) H(si),是 agent i 的 infostate 的所有 h 的集合;
- s p u b = ( O p u b 0 , O p u b 1 , ⋯ , O p u b t ) s_{pub}=(O_{pub}^0,O_{pub}^1,\cdots,O_{pub}^t) spub=(Opub0,Opub1,⋯,Opubt),公共状态(Public State),是公共观测的序列;
- s p u b ( h ) s_{pub}(h) spub(h) 是 h 的公共状态, s p u b ( s i ) s_{pub}(s_i) spub(si) 是 s i s_i si 的公共状态, H ( s p u b ) \mathcal{H}(s_{pub}) H(spub) 是与 s p u b s_{pub} spub 相匹配的历史的集合,
- π = ( π 1 , π 2 , ⋯ , π N ) \pi=(\pi_1,\pi_2,\cdots,\pi_N) π=(π1,π2,⋯,πN),策略配置(Policy Profile),概率分布的序列, π i \pi_i πi 是一个将 infostate 映射为行为上的概率分布的函数;
- 纳什均衡(Nash Equilibrium)
π
∗
\pi^*
π∗:
v
i
(
π
∗
)
=
max
π
i
v
i
(
π
i
,
π
−
i
∗
)
v_i(\pi^*)=\max_{\pi_i}v_i(\pi_i,\pi^*_{-i})
vi(π∗)=maxπivi(πi,π−i∗)(对所有 i 均成立);
- ϵ − Nash Equilibrium \epsilon-\text{Nash Equilibrium} ϵ−Nash Equilibrium π ∗ \pi^* π∗: ∃ ϵ > 0 , s . t . v i ( π ∗ ) + ϵ ≥ max π i v i ( π i , π − i ∗ ) \exist \epsilon>0,\ s.t.\ v_i(\pi^*)+\epsilon\geq\max_{\pi_i}v_i(\pi_i,\pi^*_{-i}) ∃ϵ>0, s.t. vi(π∗)+ϵ≥maxπivi(πi,π−i∗)(对所有 i 均成立);
- 2 p 0 s 2p0s 2p0s:二人零和博弈;
- PBS β = ( Δ S 1 ( s p u b ) , Δ S 2 ( s p u b ) , ⋯ , Δ S N ( s p u b ) ) \beta=(\Delta S_1(s_{pub}),\Delta S_2(s_{pub}),\cdots,\Delta S_N(s_{pub})) β=(ΔS1(spub),ΔS2(spub),⋯,ΔSN(spub)),其中 S i ( s p u b ) S_i(s_{pub}) Si(spub) 是给定 s p u b s_{pub} spub 时 agent i 的 infostate 的集合, Δ S 1 ( s p u b ) \Delta S_1(s_{pub}) ΔS1(spub) 是 S i ( s p u b ) S_i(s_{pub}) Si(spub) 上的联合概率分布;
- V i π ( β ) = Σ h ∈ H ( s p u b ( β ) ) p ( h ∣ β ) v i π ( h ) V_i^\pi(\beta)=\Sigma_{h\in\mathcal{H}(s_{pub}(\beta))}p(h|\beta)v_i^\pi(h) Viπ(β)=Σh∈H(spub(β))p(h∣β)viπ(h),当所有选手使用 π \pi π 时,agent i 在 β \beta β 上的 value;
- 在 2p0s 中,如果二人均使用纳什均衡策略,则每人在每个 PBS β \beta β 上的 value 是唯一的,且 V 1 ( β ) = − V 2 ( β ) V_1(\beta)=-V_2(\beta) V1(β)=−V2(β);
- v i π ∗ ( s i ∣ β ) = max π i Σ h ∈ H ( s i ) p ( h ∣ s i , β − i ) v i < π i , π − i ∗ > ( h ) v_i^{\pi^*}(s_i|\beta)=\max_{\pi_i}\Sigma_{h\in\mathcal{H}(s_i)}p(h|s_i,\beta_{-i})v_i^{<\pi_i,\pi^*_{-i}>}(h) viπ∗(si∣β)=maxπiΣh∈H(si)p(h∣si,β−i)vi<πi,π−i∗>(h),在 2p0s 中是指以 β \beta β 为子博弈的根,二人采用纳什均衡策略 π ∗ \pi^* π∗ 时,第 i 人的 infostate s i s_i si 的 value。
Discrete Representation 与 Belief Representation
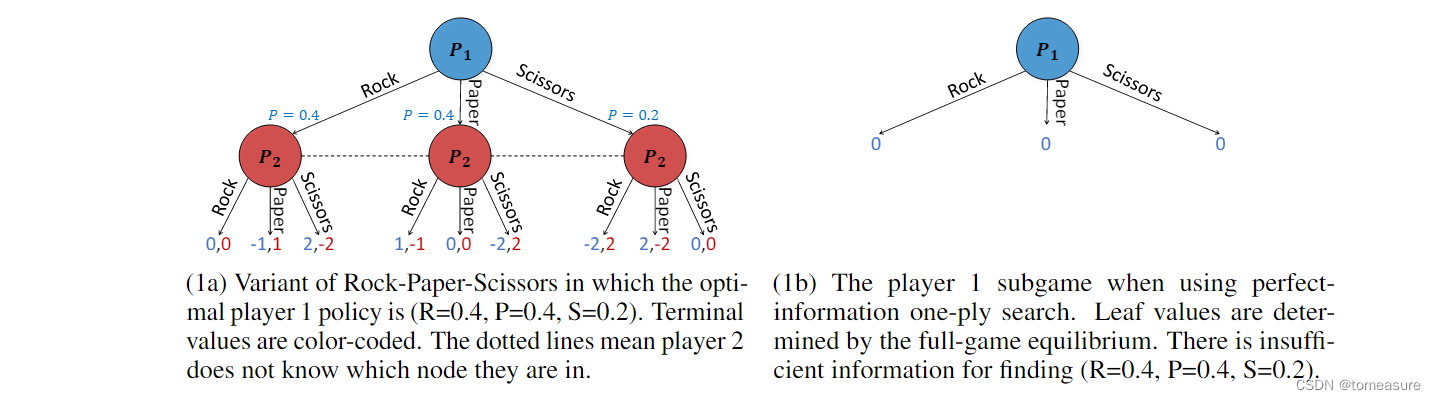
52 张牌,二人博弈。每人在每个回合中有三种选择:翻牌、叫牌与加牌。
| Discrete Representation | Belief Representation |
|---|---|
| 两人知道自己的牌不知道对方的牌,并据此采取下一步动作 | 两人不知道自己和对方的牌,裁判知道每个人的牌。裁判依据二人分别声明的牌的对应行为的概率分布在二人的牌中进行操作。二人根据裁判的行为推测自己与对方的牌,然后调整对应动作的概率分布 |
ReBel__47">ReBel 算法
f u n c t i o n REBEL-LINEAR-CFR-D ( β r , θ v , θ π , D v , D π ) # β r 是当前的 PBS while !IsTerminal ( β r ) do G ← ConstructSubgame ( β r ) π ˉ , π t w a r m ← InitializePolicy ( G , θ π ) # 如果没有 warm start ,则 : t w a r m = 0 , π 0 是均匀分布 G ← SetLeafValues ( β r , π t w a r m , θ v ) v ( β r ) ← ComputeEV ( G , π t w a r m ) t s a m p l e ∼ linear { t w a r m + 1 , T } # 迭代 t 的采样概率与 t 成正比 for t = ( t w a r m + 1 ) . . T do if t = t s a m p l e then β r ′ ← SampleLeaf ( G , π t − 1 ) # 采样一个或多个叶 PBS π t ← UpdatePolicy ( G , π t − 1 ) π ˉ ← t t + 1 π ˉ + 1 t + 1 π t G ← SetLeafValues ( β r , π t , θ v ) v ( β r ) ← t t + 1 v ( β r ) + 1 t + 1 ComputeEV ( G , π t ) Add { β r , v ( β r ) } to D v # 添加到训练值网络的数据中 for β ∈ G do # 遍历 G 中每个公共状态的 PBS Add { β , π ˉ ( β ) } to D π # 添加到训练策略网络的数据中(可选) β r ← β r ′ − − − − − − − − − − − − − − − − − − f u n c t i o n SetLeafValues ( β , π , θ v ) if IsLeaf ( β ) then for s i ∈ β do # 对与 β 相关的每个内部状态 s i v ( s i ) = v ^ ( s i ∣ β , θ v ) else for a ∈ A ( β ) do SetLeafValues ( T ( β , π , a ) , π , θ v ) − − − − − − − − − − − − − − − − − − f u n c t i o n SampleLeaf ( G , π ) i ∗ ∼ unif { 1 , N } , h ∼ β r # 从根 PBS 中随机选取一个历史及一位玩家 while !IsLeaf ( h ) do c ∼ unif [ 0 , 1 ] for i = 1.. N do if i = = i ∗ and c < ϵ then # 训练时设置 ϵ = 0.25 ,测试时设置 ϵ = 0 sample an action a i uniform random else sample an action a i according to π i ( s i ( h ) ) h ∼ τ ( h , a ) return β h # 返回与叶节点 h 相关的 PBS \begin{aligned} &\pmb{function}\text{ REBEL-LINEAR-CFR-D }(\beta_r,\theta^v,\theta^\pi,D^v,D^\pi) \ \ \ \ \text{\# }\beta_r\text{ 是当前的 PBS}\\ &\ \ \ \ \text{while !IsTerminal}(\beta_r)\text{ do} \\ & \ \ \ \ \ \ \ \ G\leftarrow \text{ConstructSubgame}(\beta_r) \\ & \ \ \ \ \ \ \ \ \bar{\pi},\pi^{t_{warm}}\leftarrow \text{InitializePolicy}(G,\theta^\pi) \ \ \ \ \text{\# 如果没有 warm start ,则 :}t_{warm}=0, \pi^0\text{ 是均匀分布}\\ & \ \ \ \ \ \ \ \ G\leftarrow \text{SetLeafValues}(\beta_r,\pi^{t_{warm}},\theta^v) \\ & \ \ \ \ \ \ \ \ v(\beta_r)\leftarrow \text{ComputeEV}(G,\pi^{t_{warm}}) \\ & \ \ \ \ \ \ \ \ t_{sample}\sim \text{linear}\{t_{warm}+1,T\} \ \ \ \ \text{\# 迭代 t 的采样概率与 t 成正比}\\ & \ \ \ \ \ \ \ \ \text{for }t=(t_{warm}+1)..T\text{ do} \\ & \ \ \ \ \ \ \ \ \ \ \ \ \text{if }t=t_{sample}\text{ then} \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \beta'_r\leftarrow \text{SampleLeaf}(G,\pi^{t-1}) \ \ \ \ \text{\# 采样一个或多个叶 PBS}\\ & \ \ \ \ \ \ \ \ \ \ \ \ \pi^t\leftarrow\text{UpdatePolicy}(G,\pi^{t-1}) \\ & \ \ \ \ \ \ \ \ \ \ \ \ \bar{\pi}\leftarrow\frac{t}{t+1}\bar{\pi}+\frac{1}{t+1}\pi^t \\ & \ \ \ \ \ \ \ \ \ \ \ \ G\leftarrow\text{SetLeafValues}(\beta_r,\pi^t,\theta^v) \\ & \ \ \ \ \ \ \ \ \ \ \ \ v(\beta_r)\leftarrow\frac{t}{t+1}v(\beta_r)+\frac{1}{t+1}\text{ComputeEV}(G,\pi^t) \\ & \ \ \ \ \ \ \ \ \text{Add }\{\beta_r,v(\beta_r)\}\text{ to }D^v \ \ \ \ \text{\# 添加到训练值网络的数据中}\\ & \ \ \ \ \ \ \ \ \text{for }\beta\in G\text{ do} \ \ \ \ \text{\# 遍历 G 中每个公共状态的 PBS}\\ & \ \ \ \ \ \ \ \ \ \ \ \ \text{Add }\{\beta,\bar{\pi}(\beta)\}\text{ to }D^\pi \ \ \ \ \text{\# 添加到训练策略网络的数据中(可选)}\\ & \ \ \ \ \ \ \ \ \beta_r\leftarrow\beta'_r \\ &------------------\\ &\pmb{function}\text{ SetLeafValues}(\beta,\pi,\theta^v) \\ &\ \ \ \ \text{if IsLeaf}(\beta)\text{ then} \\ &\ \ \ \ \ \ \ \ \text{for }s_i\in\beta\text{ do} \ \ \ \ \text{\# 对与 }\beta\text{ 相关的每个内部状态} s_i\\ &\ \ \ \ \ \ \ \ \ \ \ \ v(s_i)=\hat{v}(s_i|\beta,\theta^v) \\ &\ \ \ \ \text{else} \\ &\ \ \ \ \ \ \ \ \text{for }a\in\mathcal{A}(\beta)\text{ do} \\ &\ \ \ \ \ \ \ \ \ \ \ \ \text{SetLeafValues}(\mathcal{T}(\beta,\pi,a),\pi,\theta^v) \\ &------------------ \\ &\pmb{function}\text{ SampleLeaf}(G,\pi) \\ &\ \ \ \ i^*\sim\text{unif}\{1,N\},h\sim\beta_r \ \ \ \ \text{\# 从根 PBS 中随机选取一个历史及一位玩家}\\ &\ \ \ \ \text{while !IsLeaf}(h)\text{ do} \\ &\ \ \ \ \ \ \ \ c\sim\text{unif}[0,1] \\ &\ \ \ \ \ \ \ \ \text{for }i=1..N\text{ do} \\ &\ \ \ \ \ \ \ \ \ \ \ \ \text{ if }i==i^*\text{ and }c<\epsilon\text{ then} \ \ \ \ \text{\# 训练时设置 }\epsilon=0.25\text{,测试时设置 }\epsilon=0\\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \text{sample an action }a_i\text{ uniform random} \\ &\ \ \ \ \ \ \ \ \ \ \ \ \text{else} \\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \text{sample an action }a_i\text{ according to }\pi_i(s_i(h)) \\ &\ \ \ \ \ \ \ \ h\sim \tau(h,a) \\ &\ \ \ \ \text{return }\beta_h \ \ \ \ \text{\# 返回与叶节点 h 相关的 PBS}\\ \end{aligned} function REBEL-LINEAR-CFR-D (βr,θv,θπ,Dv,Dπ) # βr 是当前的 PBS while !IsTerminal(βr) do G←ConstructSubgame(βr) πˉ,πtwarm←InitializePolicy(G,θπ) # 如果没有 warm start ,则 :twarm=0,π0 是均匀分布 G←SetLeafValues(βr,πtwarm,θv) v(βr)←ComputeEV(G,πtwarm) tsample∼linear{twarm+1,T} # 迭代 t 的采样概率与 t 成正比 for t=(twarm+1)..T do if t=tsample then βr′←SampleLeaf(G,πt−1) # 采样一个或多个叶 PBS πt←UpdatePolicy(G,πt−1) πˉ←t+1tπˉ+t+11πt G←SetLeafValues(βr,πt,θv) v(βr)←t+1tv(βr)+t+11ComputeEV(G,πt) Add {βr,v(βr)} to Dv # 添加到训练值网络的数据中 for β∈G do # 遍历 G 中每个公共状态的 PBS Add {β,πˉ(β)} to Dπ # 添加到训练策略网络的数据中(可选) βr←βr′−−−−−−−−−−−−−−−−−−function SetLeafValues(β,π,θv) if IsLeaf(β) then for si∈β do # 对与 β 相关的每个内部状态si v(si)=v^(si∣β,θv) else for a∈A(β) do SetLeafValues(T(β,π,a),π,θv)−−−−−−−−−−−−−−−−−−function SampleLeaf(G,π) i∗∼unif{1,N},h∼βr # 从根 PBS 中随机选取一个历史及一位玩家 while !IsLeaf(h) do c∼unif[0,1] for i=1..N do if i==i∗ and c<ϵ then # 训练时设置 ϵ=0.25,测试时设置 ϵ=0 sample an action ai uniform random else sample an action ai according to πi(si(h)) h∼τ(h,a) return βh # 返回与叶节点 h 相关的 PBS
其中, θ v \theta^v θv 与 θ π \theta^\pi θπ 分别是策略网络与值函数网络的参数,这两个网络都用 MLP+GELU+LayerNorm 实现。
- 前者的输入是 agent 的索引+公共状态的表征+infostate 的概率分布,输出是每个infostate对应的value构成的向量。
- 后者(仅用于德州扑克)的输入额外增加 agent 的 pot size 分数与当前是否存在赌注的 flag,输出是每个infostate的所有合法行为的概率分布。
算法求解以 β r \beta_r βr 为根的子博弈。求解过程中会随机采样新的叶子 PBS(确保值函数网络的准确性),生成新的子博弈后再次求解。
子博弈是一个不完美信息博弈,采用 CFR-D 进行求解。CFR-D 会迭代 T 次,每次都会选择一个新的策略,然后更新子博弈叶子上的 value(用值函数网络更新)。CRF-D 会返回当前子博弈的期待策略与期待值。
CFR-D 得到的 { β r , v ( β r ) } \{\beta_r,v(\beta_r)\} {βr,v(βr)} 与 { β r , π ˉ ( β r ) } \{\beta_r,\bar{\pi}(\beta_r)\} {βr,πˉ(βr)} 会被用于训练值函数网络与策略网络。
策略的均值被定义为一个新策略: π ( s i ) = ( x i π 1 ( s i ) α ) π 1 ( s i ) + ( x i π 2 ( s i ) ( 1 − α ) ) π 2 ( s i ) x i π 1 ( s i ) α + x i π 2 ( s i ) ( 1 − α ) \pi(s_i)=\frac{(x_i^{\pi_1}(s_i)\alpha)\pi_1(s_i)+(x_i^{\pi_2}(s_i)(1-\alpha))\pi_2(s_i)}{x_i^{\pi_1}(s_i)\alpha+x_i^{\pi_2}(s_i)(1-\alpha)} π(si)=xiπ1(si)α+xiπ2(si)(1−α)(xiπ1(si)α)π1(si)+(xiπ2(si)(1−α))π2(si),这里 x i π 1 ( s i ) = Π t p ( a i t ) x_i^{\pi_1}(s_i)=\Pi_t p(a^t_i) xiπ1(si)=Πtp(ait)。
算法整体是一个 自我博弈 的过程,定理2表明算法经过迭代之后会得到一个误差不超过 C T \frac{C}{\sqrt{T}} TC 的值函数网络。
π ˉ \bar{\pi} πˉ 会收敛到纳什均衡。
定理
定理一,PBS 与 infostate value 之间的联系:
在二人零和博弈中,对任意 PBS
β
=
(
β
1
,
β
2
)
\beta=(\beta_1,\beta_2)
β=(β1,β2) 和以
β
\beta
β 为根的子博弈的任意纳什均衡
π
∗
\pi^*
π∗,有:
v
1
π
∗
(
s
1
∣
β
)
=
V
1
(
β
)
+
g
ˉ
⋅
s
^
1
v_1^{\pi^*}(s_1|\beta)=V_1(\beta)+\bar{g}\cdot\hat{s}_1
v1π∗(s1∣β)=V1(β)+gˉ⋅s^1
其中
g
ˉ
\bar{g}
gˉ 是
V
1
(
β
)
V_1(\beta)
V1(β) 扩展到非归一化信念分布的超梯度,
s
^
1
\hat{s}_1
s^1 是
s
1
s_1
s1 方向上的单位向量。
二人零和博弈中,使用一个值函数网络生成 V 1 ( β ) V_1(\beta) V1(β) 即可。
证明:
在引理1 与引理2 的基础上,计算 ∇ β 1 V 1 π ∗ ( s p u b , β 1 , β 2 ) \nabla_{\beta_1}V_1^{\pi^*}(s_{pub},\beta_1,\beta_2) ∇β1V1π∗(spub,β1,β2) ( V 1 V_1 V1 的超梯度)并应用 V 1 V_1 V1 的定义即可。利用 V ~ 1 π ∗ ( s p u b , β 1 , β 2 ) = V 1 π ∗ ( s p u b , β 1 / ∣ β 1 ∣ 1 , β 2 ) \tilde{V}_1^{\pi^*}(s_{pub},\beta_1,\beta_2)=V_1^{\pi^*}(s_{pub},\beta_1/|\beta_1|_1,\beta_2) V~1π∗(spub,β1,β2)=V1π∗(spub,β1/∣β1∣1,β2),其中 ∣ β 1 ∣ 1 = 1 |\beta_1|_1=1 ∣β1∣1=1
Lemma 1. Let V 1 π 2 ( β ) be player 1’s value at β assuming that player 2 plays π 2 in a 2p0s game. V 1 π 2 ( β ) is linear in β 1 . Lemma 2. V 1 ( β ) = min π 2 V 1 π 2 ( β ) , and the set of π 2 that attain V 1 ( β ) at β 0 are precisely the Nash equilibrium policies at β 0 . This also implies that V 1 ( β ) is concave. \begin{aligned} \pmb{\text{Lemma 1. }}&\text{Let }V_1^{\pi_2}(\beta)\text{ be player 1's value at }\beta\text{ assuming that player 2 plays }\pi_2\text{ in a 2p0s game. } \\ &V_1^{\pi_2}(\beta) \text{ is linear in }\beta_1. \\ \pmb{\text{Lemma 2. }}&V_1(\beta)=\min_{\pi_2} V_1^{\pi_2}(\beta)\text{, and the set of }\pi_2\text{ that attain }V_1(\beta)\text{ at }\beta_0\text{ are precisely the Nash equilibrium policies at }\beta_0\text{.} \\ &\text{ This also implies that }V_1(\beta)\text{ is concave.}\\ \end{aligned} Lemma 1. Lemma 2. Let V1π2(β) be player 1’s value at β assuming that player 2 plays π2 in a 2p0s game. V1π2(β) is linear in β1.V1(β)=π2minV1π2(β), and the set of π2 that attain V1(β) at β0 are precisely the Nash equilibrium policies at β0. This also implies that V1(β) is concave.
定理二, ReBel算法能够收敛到纳什均衡:
理想的值函数逼近器:为被采样的 PBS 返回 value 的最新样本,其他情况返回0。
在运行算法 1 时用到了 CFR 算法,该算法会迭代 T 次,子博弈借此为遇到的所有任意 PBS 构建出一个值函数逼近器,逼近器的误差不超过
C
T
\frac{C}{\sqrt{T}}
TC,对应的策略为
C
T
\frac{C}{\sqrt{T}}
TC-纳什均衡,其中 C 是一个与博弈相关的常数。
证明:
只需要证明引理3 即可:
Lemma 3 . Running Algorithm 1 for N → ∞ times in a depth-limited subgame rooted at PBS β r will compute an infostate value vector v i π ∗ ( β r ) corresponding to the values of the infostates when π ∗ is played in the (not depth-limited) subgame rooted at β r , where π ∗ is a C T -Nash equilibrium for some constant C . \begin{aligned} &\pmb{\text{Lemma 3}}\text{. Running Algorithm 1 for }N\to\infin\text{ times in a depth-limited subgame rooted at PBS }\beta_r\text{ will compute an infostate value} \\ &\text{ vector }v_i^{\pi^*}(\beta_r)\text{ corresponding to the values of the infostates when }\pi^*\text{ is played in the (not depth-limited) subgame rooted at }\beta_r\text{, } \\ &\text{where }\pi^*\text{ is a }\frac{C}{\sqrt{T}}\text{-Nash equilibrium for some constant }C. \end{aligned} Lemma 3. Running Algorithm 1 for N→∞ times in a depth-limited subgame rooted at PBS βr will compute an infostate value vector viπ∗(βr) corresponding to the values of the infostates when π∗ is played in the (not depth-limited) subgame rooted at βr, where π∗ is a TC-Nash equilibrium for some constant C.
当算法一不使用随机采样并且用递归的CFR-D算法取代神经网络时,与 CFR-D 算法是相似的。
设以 β r \beta_r βr 为根的子博弈一直延伸到总博弈的结尾,且不再使用神经网络,则 CFR 算法已经被证明可以达到 C T \frac{C}{\sqrt{T}} TC-纳什均衡 π ∗ \pi^* π∗,而算法一也确实可计算得到值向量 v i π ∗ ( β r ) v_i^{\pi^*}(\beta_r) viπ∗(βr),也就是说引理3 的基本情况是成立的。
假设:1、子博弈以 β r \beta_r βr 为根且其深度是有限的;2、在迭代 t ≤ T t\leq T t≤T 的每一个叶子 PBS β z π t \beta_z^{\pi^t} βzπt 上,我们已经计算出一个 infostate value 向量 v i π ∗ ( β z π t ) v_i^{\pi^*}(\beta_z^{\pi^t}) viπ∗(βzπt);3、引理 3 在所有叶子 PBS β z π T + 1 \beta_z^{\pi^{T+1}} βzπT+1 上成立。v i π ∗ ( β z π t ) v_i^{\pi^*}(\beta_z^{\pi^t}) viπ∗(βzπt):在以 β z π t \beta_z^{\pi^t} βzπt 为根的子博弈上采用纳什均衡策略获得的 Infostate Value。
- 对于那些拥有正的抵达概率却没有玩家抵达的叶子 PBS,它们的 value 并不会对 CFR 或者为根 infostate 计算的 value 产生影响,这是因为 CFR 是用玩家抵达的概率对 PBS 上的 value 进行加权的。
- 现在我们考虑一个叶子 PBS β z π T + 1 \beta_z^{\pi^{T+1}} βzπT+1,其上被一些玩家以正的概率到达。
后面只需要证明,如果 v i π ∗ ( β z π t ) v_i^{\pi^*}(\beta_z^{\pi^t}) viπ∗(βzπt) 能被计算出来,那么 v i π ∗ ( β z π ( T + 1 ) ) v_i^{\pi^*}(\beta_z^{\pi^(T+1)}) viπ∗(βzπ(T+1)) 也能被计算出来,并且前者对应的纳什均衡策略不会被破坏。
因为 v i π ∗ ( β z π t ) v_i^{\pi^*}(\beta_z^{\pi^t}) viπ∗(βzπt) 已经被计算出来,并且我们正在运行的算法是已经被确定的。所以 v i π ∗ ( β z π t ) v_i^{\pi^*}(\beta_z^{\pi^t}) viπ∗(βzπt) 不会在算法一的后续调用中发生改变。(这里的后续调用指的是在每个 β z π t \beta_z^{\pi^t} βzπt 上的调用,其中 t ≤ T t\leq T t≤T)。
也就是说, π t \pi^t πt 对所有 t ≤ T t\leq T t≤T 是相同的。
因为算法一对随机 CFR 的迭代进行了采样,并且当采样到迭代 T+1 的时候,为某些玩家采样叶子 PBS β z π T + 1 \beta_z^{\pi^{T+1}} βzπT+1 的概率是正的。所以 算法会在 β z π T + 1 \beta_z^{\pi^{T+1}} βzπT+1 上采样 N’ 次,当 N → ∞ N\to\infin N→∞ 时 N ′ → ∞ N'\to\infin N′→∞。
又因为引理3 在 β z π T + 1 \beta_z^{\pi^{T+1}} βzπT+1 上是成立的, v i π ∗ ( β z π T + 1 ) v_i^{\pi^*}(\beta_z^{\pi^{T+1}}) viπ∗(βzπT+1) 会在算法中被计算出来,
根据 CFR-D 论文中的结论,引理3 在所有 β r \beta_r βr 上成立。
定理三,ReBel算法被直接用于测试时具有可靠性:
如果算法 1 在测试阶段没有其他外部策略,价值网络在任意叶 PBS 上的误差不超过
δ
\delta
δ,子博弈用 CFR 的 T 次迭代求解,那么该算法可以获得
(
δ
C
1
+
δ
C
2
T
)
(\delta C_1+\frac{\delta C_2}{\sqrt{T}})
(δC1+TδC2)-纳什均衡,其中 C1、C2 是与博弈相关的常数。
首先,考虑一个接近博弈结尾的没有叶节点的子博弈,显然 π ∗ \pi^* π∗ 是 k 1 T \frac{k_1}{\sqrt{T}} Tk1-纳什均衡。( π ∗ \pi^* π∗ 是在算法一中CFR期望使用的策略)
除所有T次迭代后得到的均值策略 π ˉ T \bar{\pi}^T πˉT 外,在 t ∼ u n i f o r m { 1 , T } t\sim uniform\{1,T\} t∼uniform{1,T} 中采样一个 t 的策略 π t \pi^t πt 也是一个 k 1 T \frac{k_1}{\sqrt{T}} Tk1-纳什均衡。
接下来考虑深度有限的子博弈 G,如果根据 tabular CFR-D 计算 G 的策略,那么根据 CFR-D 论文中的定理2,所有迭代上的平均策略是 k 2 δ + k 3 T k_2\delta+\frac{k_3}{\sqrt{T}} k2δ+Tk3-纳什均衡。
像前面一样,不仅均值策略,对于随机采样得到的 t 的策略 π t \pi^t πt 也是 k 2 δ + k 3 T k_2\delta+\frac{k_3}{\sqrt{T}} k2δ+Tk3-纳什均衡。
因为博弈的回合数是有限的,所以算法一在测试中是按照 C 1 δ + C 2 T C_1\delta+\frac{C_2}{\sqrt{T}} C1δ+TC2-纳什均衡进行博弈的。