强化学习
通过策略的方式来学习,q-learing(马尔科夫链模型)
马尔科夫链:奖励*折扣因子,R(t)=reward(1)+yR(t+1),马尔可夫链多次迭代后分布趋于稳定所以可以得到最优解
q-learning
- 构建qtable,二维数组包含两个维度,state、action,qtable迭代过程中值不大于1
| - | action1 | action2 | action3 |
|---|---|---|---|
| state1 | |||
| state2 | |||
| state3 |
action更新公式:Q(s,a)←Q(s,a)+α[reward+γmax′Q(s′,a′)−Q(s,a)]
给每个action打分,最后使用numpy的argmax得到最大值索引
γ折扣因子,值越大,当前action权重越大,否者历史action权重大
训练过程引入贪心算法

gym_20">gym使用
import gym
quit = False
env = gym.make("CartPole-v1", render_mode="human")
print(env.observation_space,env.action_space)
state = env.reset() #reset返回env内在的状态4参数,qtable的state=4个参数组成一个state值,再根据state的参数范围,划分出n个状态,action=0,1左右2个值
while not quit:
env.render()
env.step(1)
官方demo
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset() #初始化环境每次迭代
for t in range(100):
env.render() #显示
print(observation)
action = env.action_space.sample() #随机选择action
observation, reward, done, info = env.step(action)
if done:#判断游戏是否结束
print("Episode finished after {} timesteps".format(t+1))
break
env.close()

q-learning
官方demo,gym的reward奖励不需要自己构建,gym会根据用户操作给出相应的reward值,step函数返回
alpha = 0.8
nstate = 50 #划分状态区间,平衡游戏只在初始位置有效,平均划分状态值不好训练
gamma = 1 #衰减因子
env = gym.make("CartPole-v0", render_mode="human")
table = np.zeros((nstate,nstate,nstate,nstate,env.action_space.n))#左右两个action
print(env.observation_space,env.action_space)
for i in range(10000):
t=0
observation = env.reset()
high = env.observation_space.high
low = env.observation_space.low
high[1]=high[3]=10 #重新定义取值范围,否则state索引位置不变化
low[1]=low[3]=-10 #重新定义取值范围,否则state索引位置不变化
while True:
env.render()
div = (high-low)/nstate
state = tuple(((observation[0]-env.observation_space.low)/div).astype(int))
if np.random.random() < 0.3:#随机选择
action = env.action_space.sample()
else:
action = np.argmax(table[state])
t+=1
observation = env.step(action)
table[state][action] += (alpha*(observation[1]+ gamma * np.max(table[state])-table[state][action]))
if observation[2]:
print("{} Episode finished after {} timesteps".format(state,t+1))
break;
小车爬山的例子
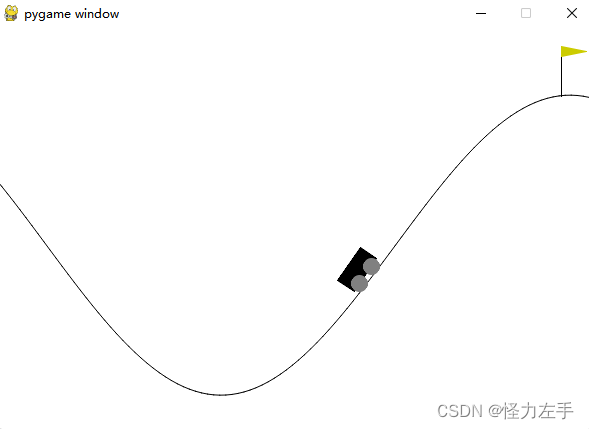
env = gym.make("MountainCar-v0", render_mode="human")
n_states = 40
iter_max = 10000
gamma = 1.0
epsilon = 0.3
alpha = 0.5
def obs_to_state(obs): #把参数范围划分40个状态,求当前值在哪个状态区间
env_low = env.observation_space.low
env_high = env.observation_space.high
env_dx = (env_high - env_low) / n_states
state_index = tuple(((obs - env_low) / env_dx).astype(int))
return state_index
Q = np.zeros((n_states, n_states, env.action_space.n))
obs = env.reset()
s = obs_to_state(obs[0])
while True:
env.render()
if np.random.uniform(0, 1) < epsilon:
a = env.action_space.sample()
else:
a = np.argmax(Q[s])
obs = env.step(a)
if obs[2]: break
next_s = obs_to_state(obs[0])
td_target = obs[1] + gamma * np.max(Q[next_s])
td_error = td_target - Q[s][a]
Q[s][a] += alpha * td_error
s = next_s
print(Q)
保存参数值
numpy.save(“1”,qtable)
numpy.load(“1”)
qtable保存,每次使用qtable的结果执行,训练过程中保存state的多维数组的索引都有遍历到,去掉随机因子就可以使用qtable决策了,qtable需要遍历所有的qtable得到一个稳定的结果,训练太慢可以是DQN网络
在gym以外的其他游戏,需要自定义reward奖励,每个状态的奖励值差别越大学习越快。
q-learning适用于离散的运动,连续的状态变换效果不是很好