视觉Transformer(ViTs)在各种计算机视觉任务中表现出卓越的性能。然而,高计算复杂性阻碍了ViTs在内存和计算资源有限的设备上的适用性。尽管某些研究已经深入探讨了卷积层与自注意力机制的融合,以增强ViTs的效率,但在纯自注意力机制的基础上构建小型但有效的ViTs仍存在知识空白。此外,采用直接策略来减少大型但性能卓越的ViT中的特征通道往往会导致性能显著下降,尽管效率得到改善。
为了解决这些挑战,作者提出了一种新的通道Shuffle模块,以改进小型ViTs,展示了在计算资源有限的环境中纯自注意力模型的潜力。受ShuffleNetV2中通道Shuffle设计的启发,作者的模块扩展了小型ViT的特征通道,并将通道分为两组:Attended Group和Idle Group。自注意力计算仅在指定的Attended Group上使用,然后进行通道Shuffle操作,促进两组之间的信息交换。
通过将作者的模块整合到小型ViT中,作者可以在保持与原始模型相当的计算复杂性的情况下实现更好的性能。具体而言,作者提出的通道Shuffle模块可持续提高各种小型ViT模型在ImageNet-1K数据集上的top-1准确度,提高幅度最高可达2.8%,而模型复杂性的变化不超过0.03 GMACs。
1、简介
自ViT成功以来,视觉Transformer已经主导了计算机视觉领域,表现出在图像分类、目标检测和分割等方面出色的性能。然而,自注意力机制的高计算负担使ViTs在具有有限内存和计算资源的设备上与传统的卷积神经网络相比效率较低。因此,研究界越来越关注开发轻量化和高效的ViT模型。
已经提出了各种方法来解决这一挑战。一些方法将高效的卷积操作与计算昂贵的自注意结合起来,创建了混合高效的ViTs。然而,这些方法未充分利用纯自注意模型实现高性能和高效率的潜力。或者,某些研究重新审视高效CNN的设计原则,并将它们转移到高效ViT的设计中,例如基于窗口的注意力、分层网络架构、瓶颈结构和空间可分的自注意力。
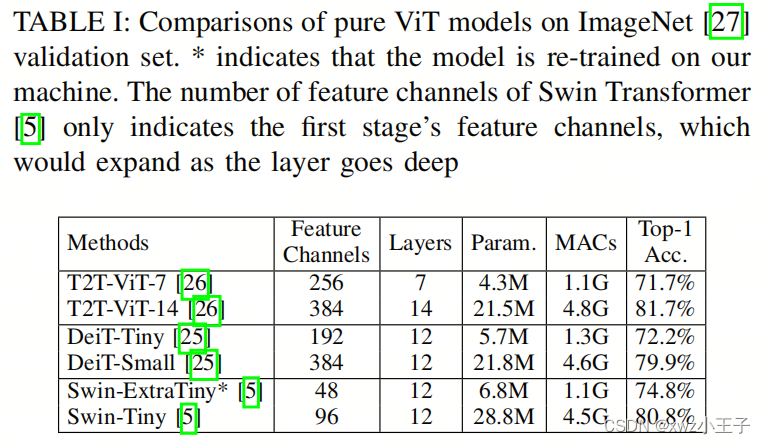
值得注意的是,由ShuffleNet引入的通道Shuffle设计在这个背景下研究较少。此外,一些强大的ViT模型通过简单地减少特征通道、层或自注意头的数量构建它们的轻量级版本。然而,正如表I所示,这种简单的模型大小减小往往导致性能显著下降。例如,当特征通道数量从384减少到192时,DeiT-Tiny与DeiT-Small相比,在ImageNet上的top-1准确度下降了7.7%。
作者发现,导致小型ViTs性能下降的主要原因之一是特征通道数量有限。特征通道数量不足使小型ViTs无法有效表示图像。为了缓解图像表示不足的类似问题,以往的高效CNN研究利用分组卷积的概念,降低计算复杂性和内存占用,而不损害特征通道的总数。
此外,ShuffleNet提出了一种通道Shuffle操作,以帮助信息在组之间流动。ShuffleNet v2广泛探讨了架构设计,并引入了一种策略,将通道分成两组,允许一组在整个层中保持Idle,并在两组之间进行通道Shuffle。值得注意的是,高效CNN中的这些设计很少用于高效的纯自注意力模型。
因此,在本文中,作者提出了一个专门为小型ViT模型设计的通道Shuffle模块,以解决上述挑战。受到ShuffleNet v2、ShuffleNet的启发,作者的模块扩展了压缩ViT模型的特征通道,并将其分为两组,即Attended Group和Idle Group。在每个层中,Attended Group执行类似于传统ViT的自注意力计算,而在计算过程中,Idle Group保持不活跃。在每个层的末尾,使用通道Shuffle操作来交错两个特征通道组,并促进信息交换。这个模块作为一个即插即用的增强功能,可以改善小型ViTs的性能,而仅需稍微增加计算量。与此同时,作者的模块是通用的,可以应用于普通ViTs和分层ViTs。在本文中,作者选择DeiT和T2T-ViT作为普通ViTs的代表,选择Swin Transformer作为分层ViTs的代表。
此外,作者观察到,在层归一化之后,Idle通道可能与Attended通道相比具有不同的尺度,导致许多无关紧要的通道。为了解决这个问题,作者提出了一种简单的通道重新缩放优化方法,以缓解这个问题。大量的实验证明了作者的模块的有效性和高效性。
作者总结作者工作的主要贡献如下:
作者开发了一种高效的通道Shuffle模块,以增强小型ViTs,而仅需非常少量的额外计算,满足具有有限计算资源的环境。
作者的模块可以作为独立的即插即用组件,用于普通ViTs和分层ViTs。
作者引入了一种简单的通道重新缩放方法,以缓解Attended Group和Idle Group之间尺度不同的问题。
大量实验证明了作者提出的模块的高效性和有效性。据作者所知,这是第一项通过丰富通道级信息而保持计算复杂性的工作,改善了小型高效ViTs。
- 方法
A. 预备知识
传统的ViT首先将输入图像分成图像块(patches),然后通过线性投影将图像块映射为图像Token。这些Token作为后续计算的输入,使模型能够捕捉全局上下文信息。作者将第层的输入特征映射表示为,其中N和C分别是Token和特征通道的数量。每个ViT层由多头自注意力(MHSA)模块和前馈网络(FFN)模块组成。
对于MHSA模块,它将输入特征映射线性变换为三个矩阵,分别称为Key()、Query()和Key():
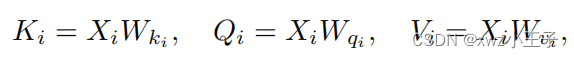
其中,和分别是相应的权重,省略了偏置项。接下来,它通过Key和Query之间的Softmax激活进行点积运算,计算注意力图:
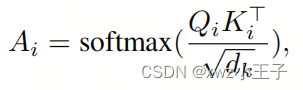
其中是K的维度,通常与通道维度C相同。注意力图反映了每对Token之间的相似性。最后,MHSA计算出带有残差连接的注意力输出:
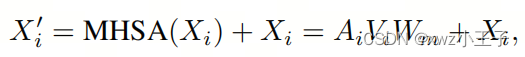
其中是可学习的权重。在MHSA模块之后,使用两层多层感知器(MLP)作为FFN模块来自激活每个Token:
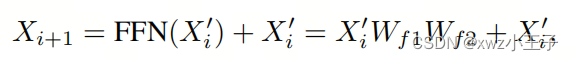
其中和是两个可学习的投影权重,是通道扩展比例,是第层ViT的输出,省略了偏置项。此外,ViT引入了预模块层归一化(LN)在特征映射上,以提高训练时间和泛化性能。
B. 通道Shuffle模块
图1提供了作者提出的通道Shuffle模块的概述,旨在增强小型ViT模型的能力。为了提高特征表示能力,作者首先在Token嵌入阶段将输入特征映射的特征通道数量加倍,得到。在第层中,特征映射被沿着特征通道维度分为两组,即Attended Group 和Idle Group 。Attended Group仅占据一半的通道并参与本层的计算,导致关注输出。相反,Idle Group保持其余一半的通道,直到本层结束,以便。在第层的末尾,这两组被连接在一起,如下所示:
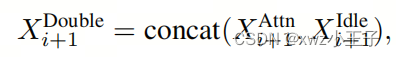
其中是第层的输出。最后,作者对应用通道Shuffle,以强制信息在这两组之间进行交换。
C. 通道重新缩放
作者已经发现了与MHSA和FFN模块中使用的残差连接[36]相关的一个潜在问题,它可能导致Xi Attn +1和Xi Idle +1之间的尺度差异显著。这种差异可能导致在特别是在深层中的层归一化之后出现许多无关紧要的值。为了解决这个问题,作者为Xi Attn +1设计了一种通道重新缩放方法。具体而言,作者修改了方程3和4中描述的Transformer层如下:
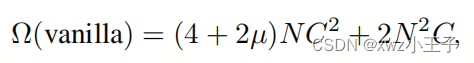
其中
、
是两个可学习的系数。作者可以使用这个简单的修改来使作者的模块自动控制Attended Group中特征表示的尺度。
D. 计算复杂性分析
首先,作者比较了普通ViT和配备了作者提出的模块的小型ViT的理论计算复杂性,假设两个模型具有相等数量的总特征通道。对于普通ViT,每层的计算复杂性可以表示为:
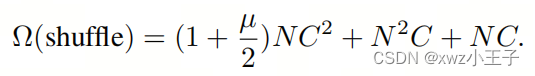
其中N、C和分别表示Token的数量、特征通道和MLP的扩展比例。另一方面,配备了作者的通道Shuffle模块的小型ViT的计算复杂性为:
值得注意的是,作者的Shuffle模块的计算复杂性明显小于普通ViT的计算复杂性。因此,考虑具有相等数量的总特征通道的模型,即具有相似的特征表示能力,作者提出的模块在计算上更高效,适用于资源有限的设备上部署。
此外,作者分析了配备通道Shuffle模块的小型ViT模型与不带该模块的整体计算复杂性。由于Idle Group不参与计算,作者模块每层的计算复杂性增加仅来自通道重新缩放,即NC。因此,层上的总计算复杂性增加为。
此外,作者的模块在Token嵌入阶段将通道数量加倍,导致额外的次计算,其中代表图像块的大小。此外,在最后一层,作者的模块引入了额外的次计算,其中表示类别数量。
因此,总的计算复杂性增加为,与整体计算复杂性相比相对较小。以DeiTTiny为例,总的计算复杂性约为1.25GMACs,而作者的通道Shuffle模块带来的额外计算复杂性仅为0.03GMACs,约占总计算复杂性的2%。
E. 即插即用模块
这个模块的一个重要贡献是它可以解决小型ViT模型性能下降的问题。通道Shuffle模块可以轻松地集成到小型ViT中,而不需要对Backbone架构进行重大修改。如图1所示,Idle Group不参与计算,这使得将模块应用于不同变体的ViT架构变得简单。
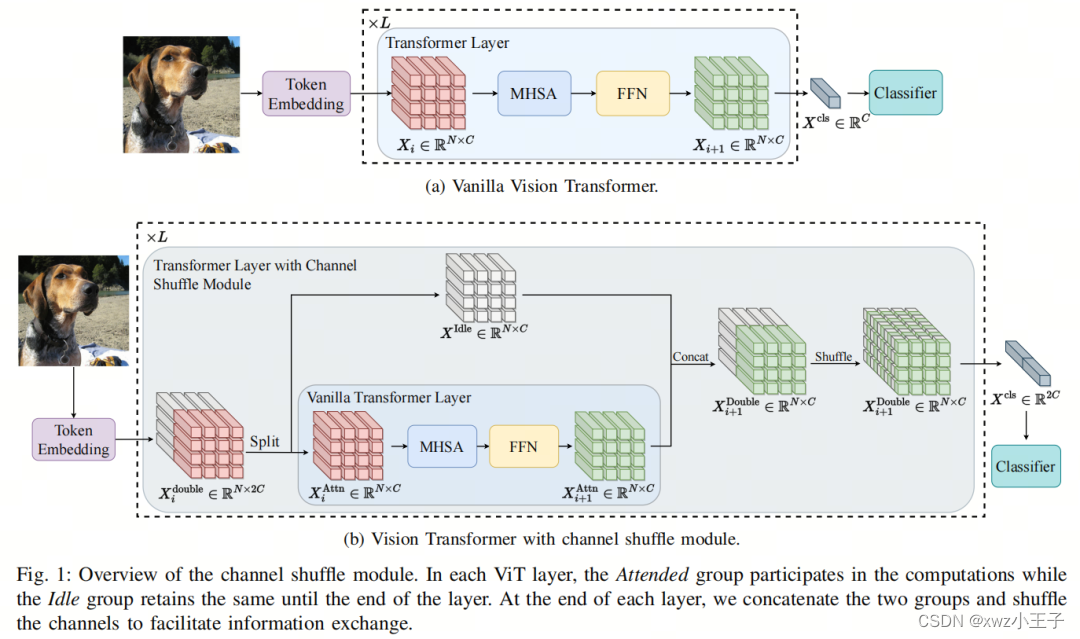
当将通道Shuffle模块集成到普通ViT中时,在图像Token嵌入阶段,特征通道的数量会加倍,然后在整个网络中保持不变。然而,在分层ViTs中,计算复杂性可以与下采样层中的特征通道数量的平方成正比。作者的通道Shuffle模块可能会导致计算量显著增加。
以Swin Transformer为例,完全连接的下采样层的计算复杂性为。但是,如果在通道Shuffle模块中将特征通道加倍,下采样的计算复杂性将增加到每个下采样层的。
为了解决这个问题,在将通道Shuffle模块应用于分层ViTs时,作者对Attended Group和Idle Group执行单独的下采样操作,以防止在分层ViTs中引入过多的计算负担。
- 实验
3.1. 主要结果
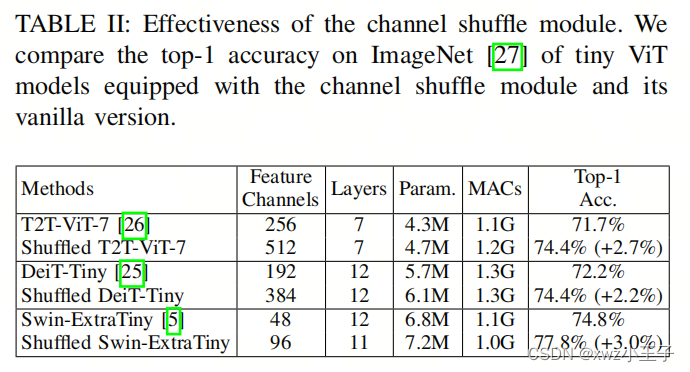
表II提供了在精度、参数数量和计算复杂性方面纯自注意模型与作者的通道Shuffle模块的比较。结果清楚地显示,通道Shuffle模块显著提升了小型ViT在分类任务中的性能,将准确性提高了2.2∼3.0%,而计算开销并未显著增加。
以DeiT-Tiny为例,Shuffle版本在保持与原始版本等效的计算成本的情况下,提高了2.2%的top-1准确性。至于Swin-ExtraTiny,由于作者去掉了一个层,Shuffle版本(1.0GMACs)比未Shuffle版本(1.1GMACs)运行更快,top-1准确性提高了3.0%。这些结果突显了作者简单而强大的设计模块的有效性和通用性。
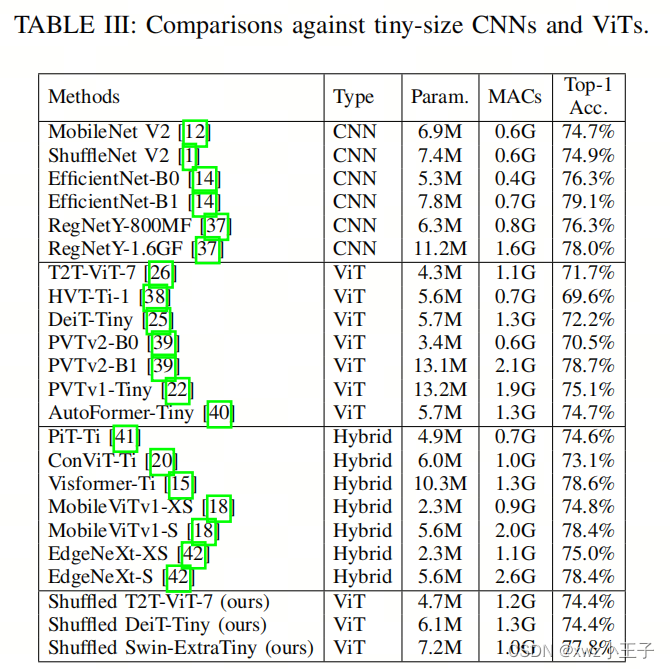
表III提供了作者的通道Shuffle模块、其他高效CNN、ViT和混合模型之间的全面比较。首先,作者的通道Shuffle模块在模型复杂性和准确性之间的权衡方面始终优于所有其他纯ViT模型,突显了作者模块的有效性。其次,与将卷积和自注意相结合的混合模型相比,作者的模块取得了可比较甚至更好的性能。
例如,在相同的模型复杂性为1.1GMACs的情况下,具备通道Shuffle模块的Swin-ExtraTiny优于EdgeNeXt-XS约2.8%。这个结果展示了高效的纯自注意力网络的潜力。然而,值得注意的是,与面向移动设备的CNN相比,基于自注意力的网络在实现相同性能时仍然显示出较低的效率。
3.2. 特征通道分析
通道Shuffle模块在增强小型ViT模型表示图像特征的能力方面起到了关键作用。即使一半的通道不活跃地参与Transformer层的计算,它们仍然具有两个重要的功能:在层之间传播梯度和丰富可用的图像特征。
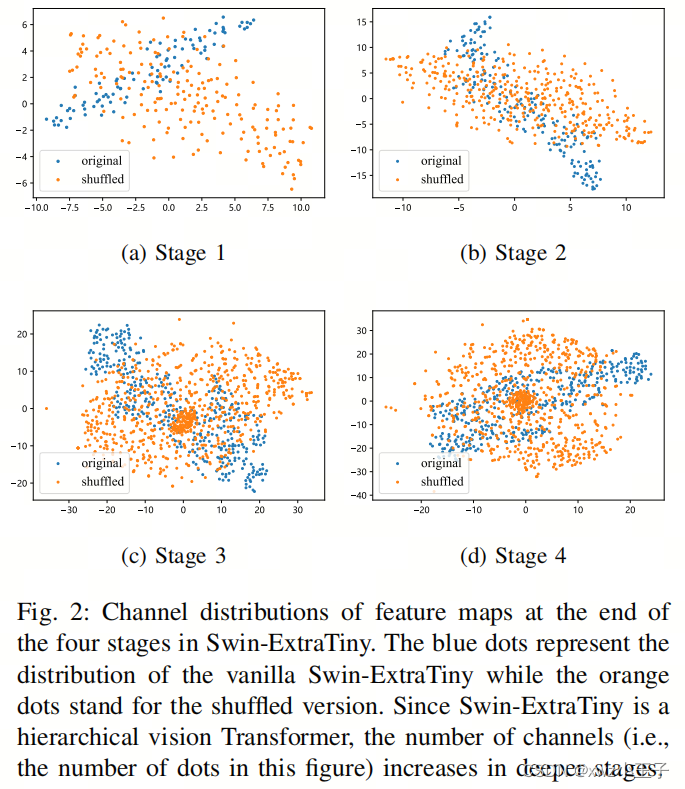
为了验证这一观点,作者在图2中可视化并比较了关于Shuffle和Vanilla Swin-ExtraTiny的四个阶段的特征通道分布。作者使用t-分布随机邻居嵌入(t-SNE)进行降维。在图2(a)中,很明显,早期阶段的通道数量较少(例如Swin-ExtraTiny的48个通道和Shuffle Swin-ExtraTiny的96个通道),Shuffle模型(橙色)显示出比未Shuffle的模型(蓝色)更多样化的分布。这表明Shuffle模型在早期阶段从作者的模块中获益,通过在早期阶段融入更丰富的信息。
然而,随着模型进入更深层次并且特征通道数量增加,Shuffle和未Shuffle模型之间的分布方差变得不那么明显,如图2©和2(d)所示。作者认为这是为什么作者的通道Shuffle模块可以改善小型ViT模型性能的主要原因。然而,作者还指出,随着模型规模的增加,该模块的改进会减小。较大的ViT模型已经拥有足够的特征通道来有效地表示图像,而过大的通道甚至可能产生负面影响。
例如,Shuffle Swin-Ti(28.8M,4.3G MACs)的准确性仅略高于其Vanilla版本(28.8M,4.5G MACs)的80.8%。作者认为该模块对于缺乏特征表示的小型模型最有益。随着模型规模的增加,当模型的特征表示变得更加复杂时,该模块的影响消失。
3.3. 消融研究
作者在通道Shuffle模块中提出了两个关键组件:独立的通道Shuffle过程和通道重新缩放。在本节中,作者进行割离研究以评估这两个设计选择的影响。
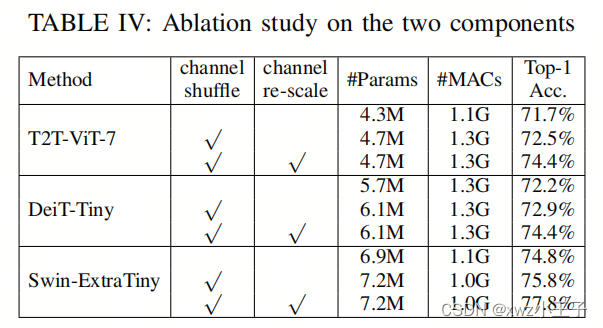
通道Shuffle
表IV表明,如果不进行重新缩放,仅仅将通道Shuffle模块集成到视觉Transformer中,性能会略有改善。这是因为当特征通道数量较小时,通道Shuffle过程可能会引入更不平衡的特征。尽管性能略有提升,但仅采用通道Shuffle模块仍有助于提高准确性。
通道重新缩放
表IV强调了通道重新缩放在该模块中的重要性,因为它改进了通道Shuffle的结果。例如,具有通道重新缩放的Shuffle SwinExtra Tiny模型超越了原始版本和不缩放版本,分别提高了3.0%和2.0%的top-1准确性。
参考
ShuffleNet v2. Plug’n Play Channel Shuffle Module for Enhancing Tiny Vision Transformers.




