A3C算法( Asynchronous Methods for Deep Reinforcement Learning)于2016年被谷歌DeepMind团队提出。A3C是一种非常有效的深度强化学习算法,在围棋、星际争霸等复杂任务上已经取得了很好的效果。接下来,我们先从A3C的名称入手,去解析这个算法。

A3C代表了异步优势动作评价(Asynchronous Advantage Actor Critic)
-
异步(Asynchronous):因为算法涉及并行执行一组环境。与DQN不同,DQN中单个神经网络代表的单个智能体与单个环境交互,而A3C利用上述多个化身来更有效地学习。在A3C中,有一个全局网络(global network)和多个工作智能体(worker),每个智能体都有自己的网络参数集。这些智能体中的每一个都与它自己的环境副本交互,同时其他智能体与它们的环境交互(并行训练)。这比单个智能体(除了加速完成更多工作)更好的原因在于,每个智能体的经验独立于其他智能体的经验。这样,可用于训练的整体经验多样化。
-
优势(Advantage):因为策略梯度的更新使用优势函数
-
动作评价(Actor Critic):因为这是一种动作评价(actor-critic)方法,它涉及一个在学得的状态值函数帮助下进行更新的策略 ∇ θ ′ log π ( a t ∣ s t ; θ ′ ) A ( s t , a t ; θ v ) A ( s t , a t ; θ v ) = ∑ i = 0 k − 1 γ i r t + i + γ k V ( s t + k ; θ v ) − V ( s t ; θ v ) \begin{gathered}\nabla_{\theta'}\log\pi(a_t|s_t;\theta')A(s_t,a_t;\theta_v)\\\\A(s_t,a_t;\theta_v)=\sum_{i=0}^{k-1}\gamma^ir_{t+i}+\gamma^kV(s_{t+k};\theta_v)-V(s_t;\theta_v)\end{gathered} ∇θ′logπ(at∣st;θ′)A(st,at;θv)A(st,at;θv)=i=0∑k−1γirt+i+γkV(st+k;θv)−V(st;θv)
- 可以用 k k k步的bootstrap进行更新。
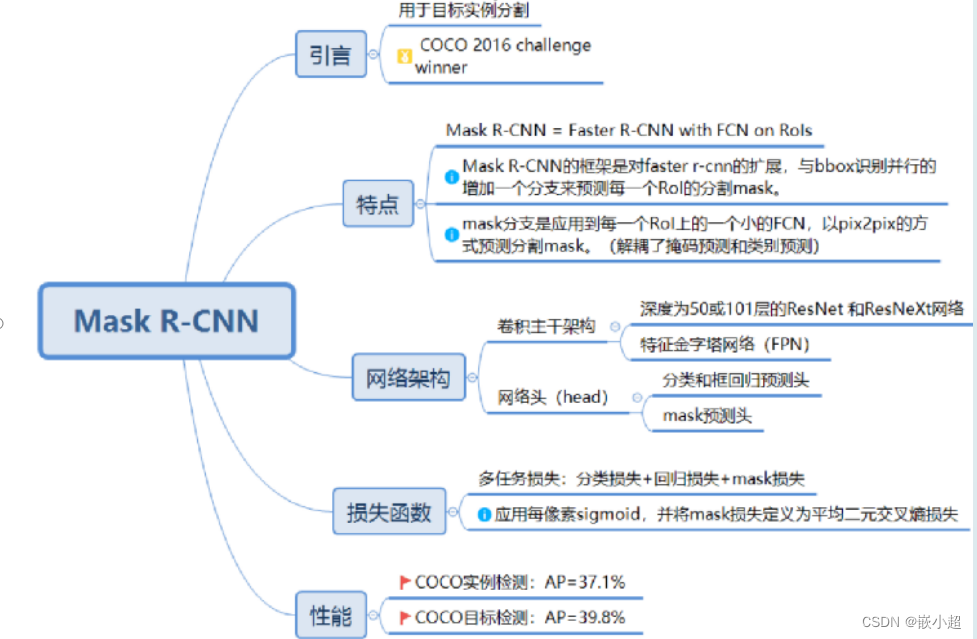
下图是一个基于16个环境平行训练的图示说明。
A3C图示说明
- 16个并行环境
- θ \theta θ指的是策略的参数(actor), θ v \theta_v θv指的是值函数的参数(critic),两者梯度分别更新, α \alpha α和 α v \alpha_v αv则是相应的学习率。
- 该算法为了鼓励探索,在策略更新中加入了一个熵奖励正则化项(嵌入在 d θ d\theta dθ中)。
- 使用Hogwild!作为更新方法。Hogwild!是一种并行更新的方法,其中多个线程可能会同时更新共享参数。这种并行更新可能会导致线程间的冲突,但在这里作者认为这不会造成太大问题。
- 在计算策略的优势时,算法采用了前向视角(forward view)的n步回报,而不是后向视角(backward view)。前向视角与后向视角的区别在于如何计算多步的奖励。后向视角的计算需要用到资格迹(eligibility traces),详情参考Sutton的圣经。


- 每个worker从global network复制参数
- 不同的worker与环境去做互动
- 不同的worker计算出各自的gradient
- 不同的worker把各自的gradient传回给global network
- global network接收到gradient后进行参数更新
Tensorflow版本代码
代码结构:
AC_Network这个类包含了创建网络本身的所有Tensorflow操作。Worker这个类包含了AC_Network的一个副本,一个环境类,以及与环境交互和更新全局网络的所有逻辑。- 用于建立
Worker实例并并行运行它们的高级代码。
Pytorch版本代码
参考了莫烦python——https://github.com/MorvanZhou/pytorch-A3C/tree/master
以及https://github.com/cyoon1729/Policy-Gradient-Methods/blob/master/a3c/a3c.py
(代码基于gymnasium去做的,但还有些问题,之后修改完再放出来),下面是运行上述代码中产生的问题:
- 莫烦python理想的结果如下所示

但在实际运行中出现下面两幅图的情况,reward达到峰值后迅速下降,猜测可能是worker学习到不好的策略,同步给global,使得原本好的策略持续变坏?


另一个版本的代码收敛较快,运行良好。也是利用交叉熵去作为正则化项的。
w0 | episode: 978 391.0
w5 | episode: 979 396.0
w3 | episode: 980 399.0
w7 | episode: 981 500.0
w4 | episode: 982 383.0
w1 | episode: 983 500.0
w6 | episode: 984 500.0
w2 | episode: 985 500.0
w0 | episode: 986 500.0
w5 | episode: 987 500.0
w3 | episode: 988 500.0
w4 | episode: 989 500.0
w7 | episode: 990 500.0
w1 | episode: 991 500.0
w6 | episode: 992 500.0
w2 | episode: 993 500.0
w0 | episode: 994 500.0
w5 | episode: 995 500.0
w3 | episode: 996 500.0
w7 | episode: 997 500.0
w4 | episode: 998 500.0
w1 | episode: 999 500.0
w6 | episode: 1000 500.0
参考
[1] 伯禹AI
[2] https://www.davidsilver.uk/teaching/
[3] 动手学强化学习
[4] Reinforcement Learning
[5] Asynchronous Methods for Deep Reinforcement Learning
[6] 第9章演员-评论员算法
[7] Simple Reinforcement Learning with Tensorflow Part 8: Asynchronous Actor-Critic Agents (A3C)
[8] Actor-Critic Methods: A3C and A2C
[9] https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/intro-A3C