对于具身智能来说,视觉肯定是一个不可缺少的信息来源。那么是否有针适用于具身智能的预训练视觉表征(Pre-trained Visual Representations, PVRs)大模型是一个值得研究的点。这篇文章就从多种具身智能任务,构建了CortexBench,来探索各种PVR,以及到底哪种路线能够最好的实现专用于具身智能的PVR。

CortexBench包含的任务包含运动控制、导航、灵巧操作、移动操作等多个任务。这篇文章为了验证预训练数据规模和多样性的效果,通过来自7种不同来源的4000个小时的Egocentric视频(5.6M张图像)以及ImageNet,使用MAE(Mask Auto-Encoding)来训练不同尺寸的ViT,然后这篇文章发现的一点是:扩大数据集和多样性并不能Universally提高表现,但是平均意义上可以。
怎么样衡量PVR的效果呢?CortexBench通过PVR获取的特征表示,然后采用强化学习或者模仿学习,在一系列任务上验证PVR的表现,如下:
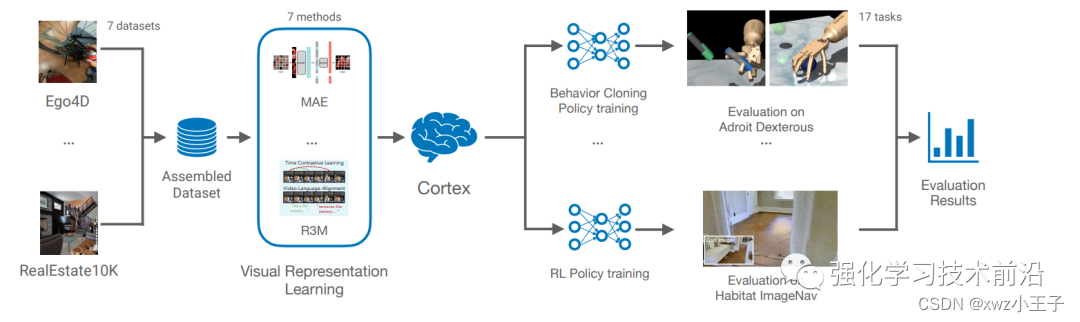
首先要看看我们是否已经有了一个效果还行的大模型,具体验证了CLIP、R3M、MVP、VIP这几种模型。然后发现没有一个模型能够在所有的任务上都表现得最好。然后这篇文章就构建了ViT-B(86M参数),ViT-L(307M参数),然后采用MAE来训练。训练的数据包含Ego4D、100 Days of Hand(100DOH)、Something-Something(SS-V2)、Epic Kitchens等。在实验中有几个发现:
模型大小。ViT-L相对ViT-B平均意义上有提升。但是不是Universally,在有的情况下ViT-L不如ViT-B。
数据规模。增加数据规模可以提升表现。但是也是平均意义。These findings suggest that task-specific pre-training datasets could enhance the performance of models on individual tasks. 特定任务的数据可以提升特定任务的表现。
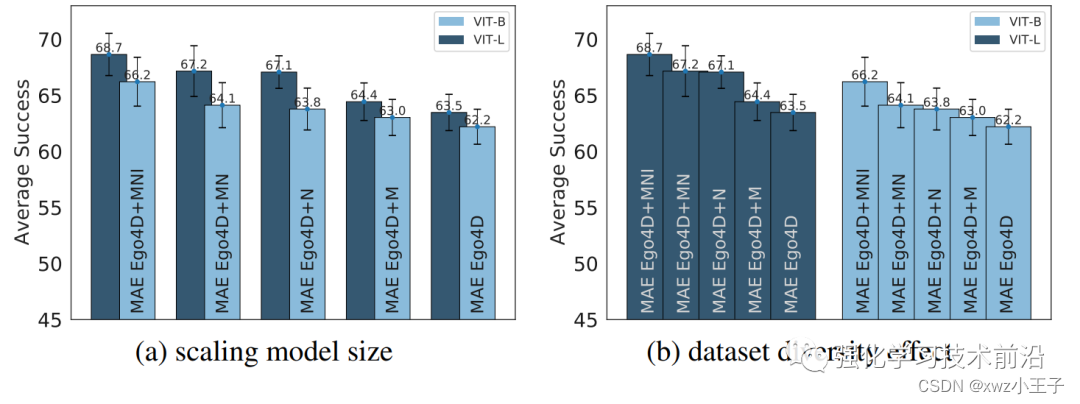
最后的结论是目前我们还没有一个足够强的通用具身智能视觉表征模型,但是发现通过MAE训练的模型可能是最有希望的。然后提升模型大小、数据规模可以在平均意义上提升效果,但是不能Universally。