java
汽车
阿克曼
正则表达式
高校就业管理
CVE-2013-4547
自定义watermark
光源
批量下载图片的插件
医院运营
三星刷机
EDM营销
cisp题库
Pascal
知识产权
keras
IO-Link
舌苔
知识计算
软件工程师
一文打通RLHF的来龙去脉
相关文章

【mysql】锁的类型有哪些呢?
0 回答
根据数据的访问级别来区分:
mysql锁分为共享锁和排他锁,也叫做读锁和写锁。读锁是共享的,可以通过lock in share mode实现,这时候只能读不能写。写锁是排他的,它会阻塞其他的写锁和读锁。
从颗粒度来区分&am…

人工智能-A*算法-最优路径搜索实验
上次学会了《A*算法-八数码问题》,初步了解了A*算法的原理,本次再用A*算法完成一个最优路径搜索实验。 一、实验内容 1. 设计自己的启发式函数。 2. 在网格地图中,设计部分障碍物。 3. 实现A*算法,搜索一条最优路径。 二、A*算法实…
60道C++STL高频题整理(附答案背诵版)
1.请解释vector容器和它的特点。
在C中,vector是标准模板库(STL)的一部分,它是一个动态数组。与普通数组相比,它的大小可以在运行时动态改变。下面是vector的一些主要特点和应用场景: 动态大小:…
批量文件重命名:自定义重命名,让文件名称与文件夹名称一致
你是否曾经遇到过文件名与文件夹名称不一致的情况,导致文件管理混乱?现在,我们为你提供了一种简单而高效的方法,让你能够批量自定义重命名文件,使其与文件夹名称保持一致。
首先第一步,我们要进入文件批量…
03 使用Vite开发Vue3项目
概述
要使用vite创建Vue3项目,有很多种方式,如果使用命令,则推荐如下命令:
# 使用nvm将nodejs的版本切换到20
nvm use 20# 全局安装yarn
npm install -g yarn# 使用yarnvite创建项目
yarn create vite不过,笔者更推荐…
![读书笔记-《数据结构与算法》-摘要5[归并排序]](https://img-blog.csdnimg.cn/direct/64be7b3c55f649b58c86cd6ddbebe3e1.gif)
读书笔记-《数据结构与算法》-摘要5[归并排序]
归并排序
核心:将两个有序对数组归并成一个更大的有序数组。通常做法为递归排序,并将两个不同的有序数组归并到第三个数组中。
先来看看动图,归并排序是一种典型的分治应用。 public class MergeSort {public static void main(String[] ar…
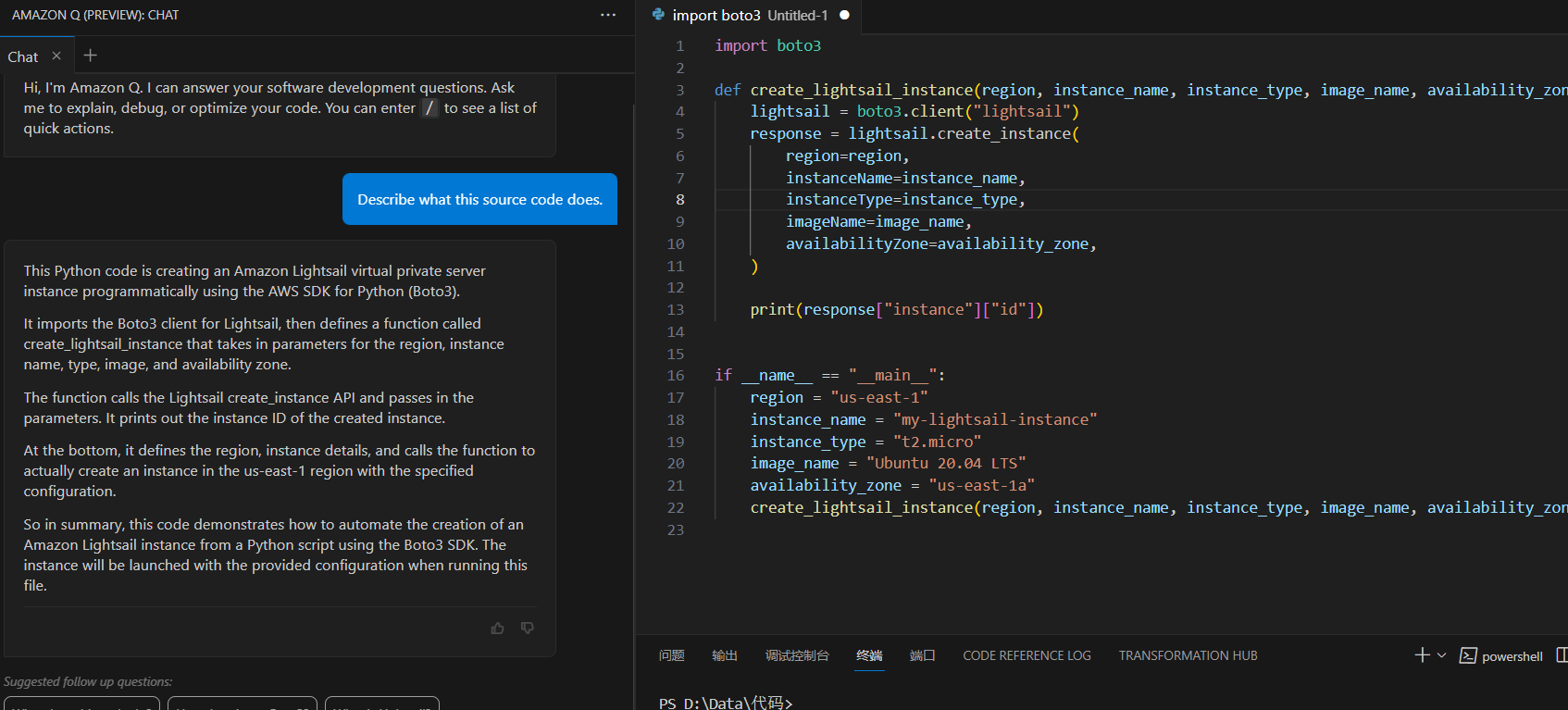
亚马逊云科技re_Invent 2023产品体验:亚马逊云科技产品应用实践 王炸产品Amazon Q,你的AI助手
本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道
意料之中
2023年9月25日,亚马逊宣布与 Anthropic 正式展开战略合作&#x…