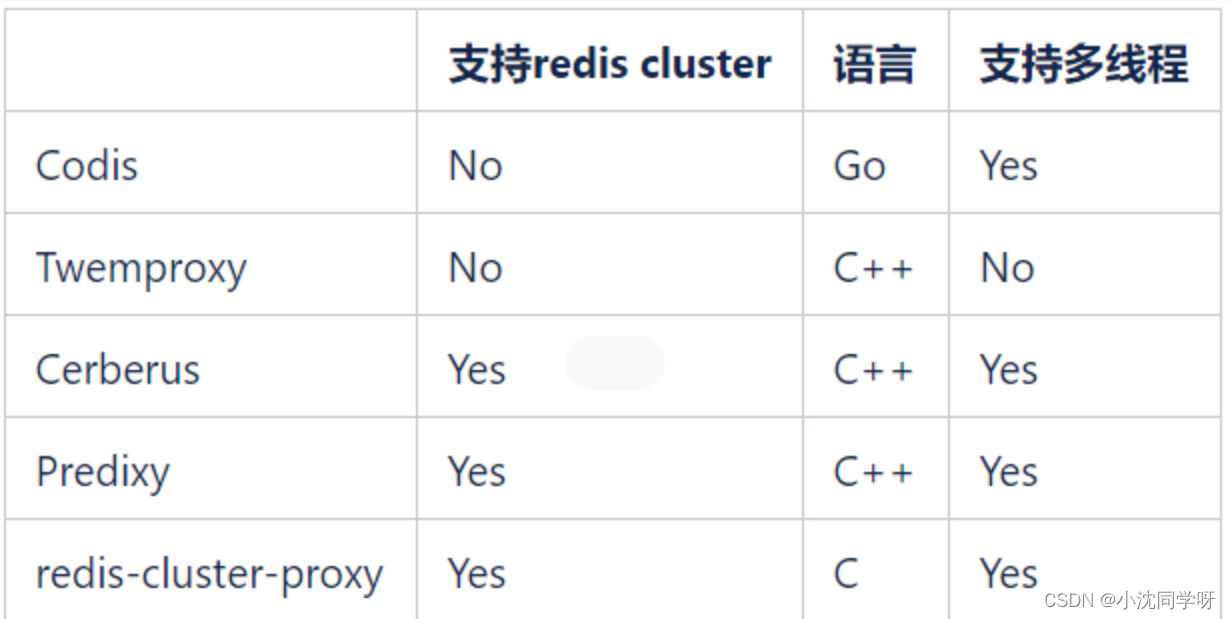
处于完全合作关系的多智能体的利益一致,获得的奖励相同,有共同的目标。比如多个工业机器人协同装配汽车,他们的目标是相同的,都希望把汽车装好。
在多智能体系统中,一个智能体未必能观测到全局状态 S。设第 i 号智能体有一个局部观测,记作 Oi,它是 S 的一部分。不妨假设所有的局部观测的总和构成全局状态:

完全合作关系下的MARL:

目录
- 策略学习
- 多智能体A2C
- 策略网络和价值网络
- 训练和决策
- 实现中的难点
- 三种架构
- 完全中心化
- 完全去中心化
- 中心化训练 + 去中心化决策
策略学习
下面由policy-based的MARL方法入手。(value-based MARL也有很多工作)
MARL 中的完全合作关系 (Fully-Cooperative) 意思是所有智能体的利益是一致的,它们有相同的奖励R,回报U,动作价值函数Q,状态价值函数V。Q和V依赖于所有agent的策略π。

通常来说,团队成员有分工合作,所以每个成员的策略是不同的,即 θi ≠ θj。
如果做策略学习(即学习策略网络参数 θ1, · · · , θm),那么所有智能体都有一个共同目标函数:

所有智能体的目的是一致的,即改进自己的策略网络参数 θi,使得目标函数 J 增大。那么策略学习可以写作这样的优化问题:

(注意,只有“完全合作关系”这种设定下,所有智能体才会有共同的目标函数,其原因在于 R1 = · · · = Rm。对于其它设定,“竞争关系”、“混合关系”、“利己主义”,智能体的目标函数是各不相同的。)

可能有人好奇R,U,Q,V都一样了,为什么训练出来π不一样?主要是每个agent的动作空间有区别,各司其职,所以agent的策略会有区别。
由于无法计算策略梯度∇θiJ,我们需要对其做近似。下面用 价值网络 近似 策略梯度 ,从而推导出一种实际可行的策略梯度方法。
多智能体A2C
下面介绍“完全合作关系”设定下的多智能体 A2C 方法 (Multi-Agent Cooperative A2C),缩写 MAC-A2C。简单点入手,本文只考虑离散控制问题。
策略网络和价值网络
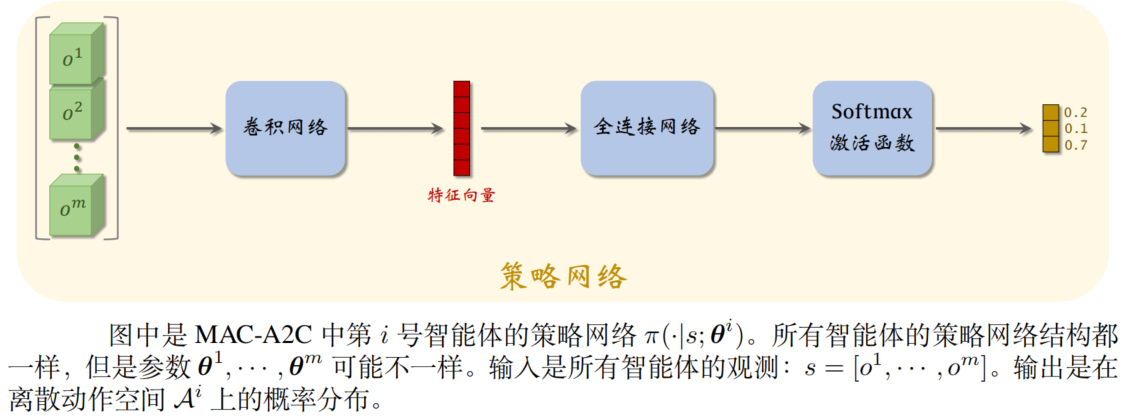
MAC-A2C 使用两类神经网络:价值网络 v 与策略网络 π。
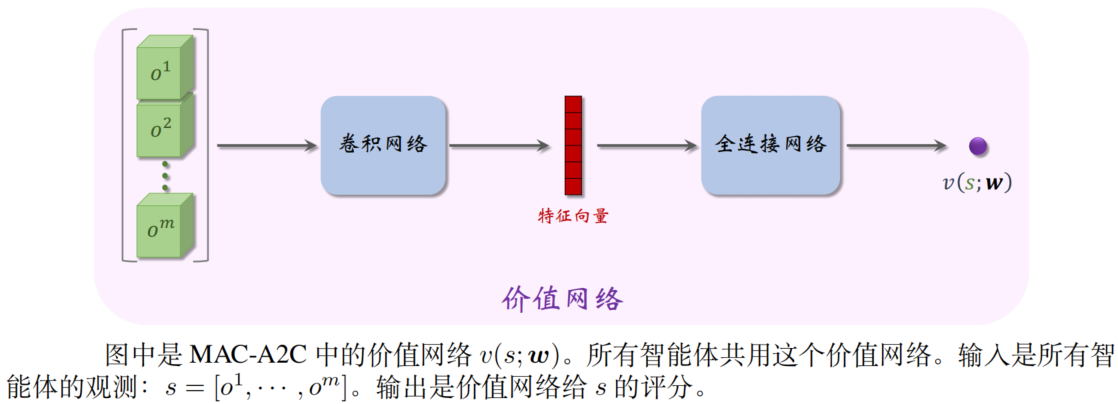
所有智能体共用一个价值网络。
每个智能体有自己的策略网络。



训练和决策


实现中的难点
最大的问题,在 MARL 的常见设定下,第 i 号智能体只知道 oi,而观测不到全局状态。

下面介绍中心化 (Centralized) 与去中心化 (Decentralized) 的实现方法。
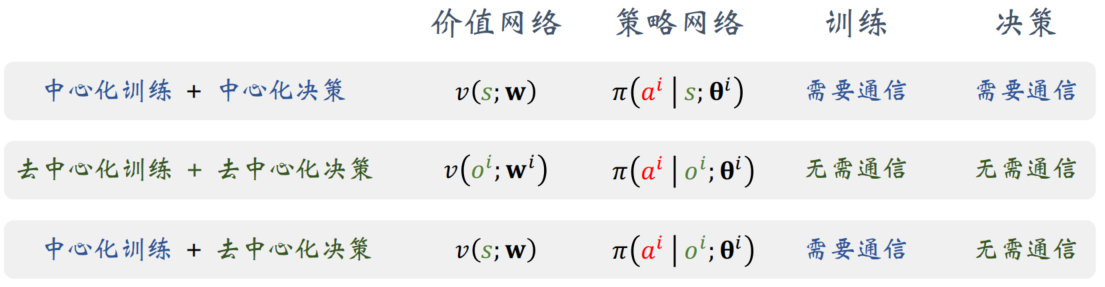
- 中心化让智能体共享信息;优点是训练和决策的效果好,缺点是需要通信,造成延时,影响速度。
- 去中心化需要做近似,避免通信;其优点在于速度快,而缺点则是影响训练和决策的质量。
三种架构
下面介绍MAC-A2C的三种实现方法。
完全中心化
中心化训练 + 中心化决策,这是MAC-A2C最忠实的实现方法,作出的决策最好,但是速度最慢,在很多问题中不适用。
训练和决策全部由中央控制器完成。智能体只负责与环境交互,然后把各种数据传给中央。智能体只需要执行中央下达的决策,而不需要自己“思考”,纯纯工具人。


完全去中心化
想要避免通信代价,就不得不对策略网络和价值网络做近似,变为“去中心化训练 + 去中心化决策”。

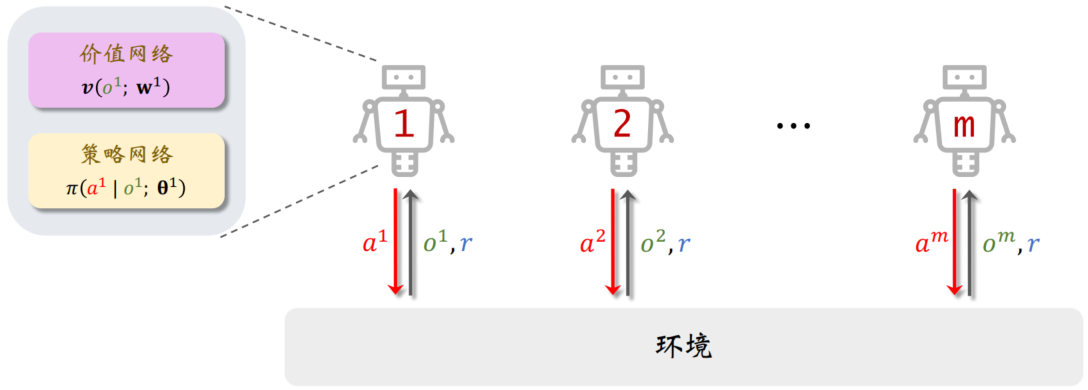
MAC-A2C 变成了标准的 A2C,每个智能体独立学习自己的参数 θi 与 wi。
去中心化训练的本质就是单智能体强化学习 (SARL),而非多智能体强化学习 (MARL)。在 MARL 中,智能体之间会相互影响,而本节中的“去中心化训练”把智能体视为独立个体,忽视它们之间的关联,直接用 SARL 方法独立训练每个智能体。用上述 SARL 的方法解决 MARL 问题,在实践中效果往往不佳。
中心化训练 + 去中心化决策
当前更流行的MARL 架构是“中心化训练 + 去中心化决策”,相对于上面两种方法,有效结合了它们的优点又缓解了它们的缺点,近年来很流行。
训练的时候使用中央控制器,辅助智能体做训练;
训练结束之后,不再需要中央控制器,每个智能体独立根据本地观测 oi 做决策。
训练:
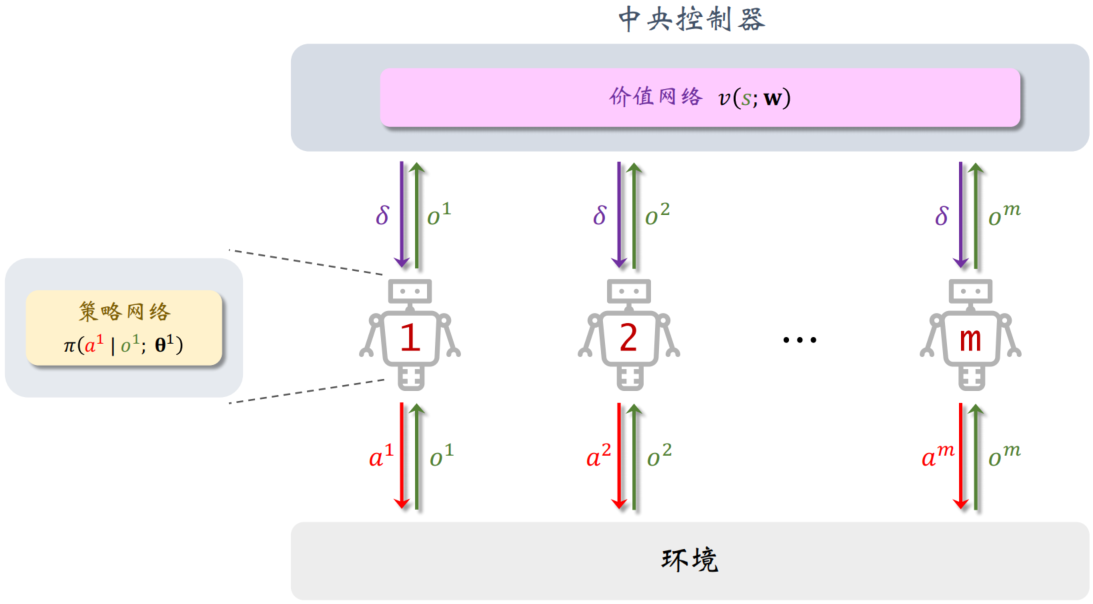
决策:
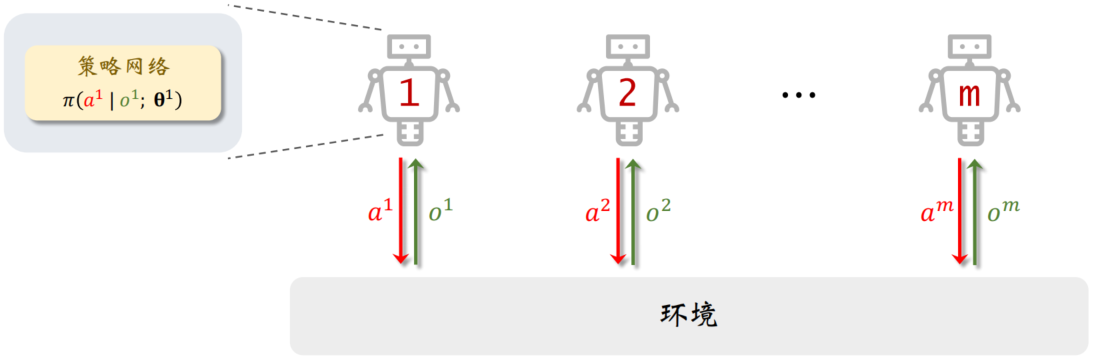
智能体只需要用其本地部署的策略网络π做决策,决策过程无需通信。
中心化执行的速度很快,可以做到实时决策。
本文内容为看完王树森和张志华老师的《深度强化学习》一书的学习笔记,十分推荐大家去看原书!