在线策略算法的样本效率比较低,而在DNQ算法中,做到了离线策略学习,但是只能处理动作空间有限的环境。如果动作空间无限,可将动作空间离散化,但比较粗糙,无法惊喜控制。深度确定性策略梯度DDPG(deep deterministic policy gradient)可以用来处理动作空间无限的离线策略算法。
DPG
为了适配连续动作空间,我们选择动作的过程变成从状态映射到具体动作的函数 μ θ ( s ) \mu_{\theta}(s) μθ(s) , θ \theta θ 是模型的参数 ,输出的结果是一个动作值,由于是输出一个值,可以成为确定性策略,而不是Actor-Critic算法输出的在输入状态s的情况下采取动作a的概率 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s) 。这就是Actor的任务。
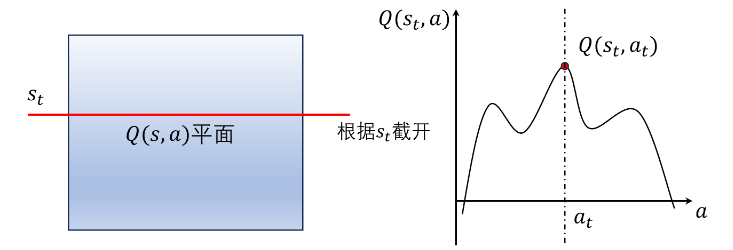
由于 Q ( s , a ) Q(s,a) Q(s,a) 由两个变量组成,在 s t s_t st 状态下,对 Q ( s , a ) Q(s,a) Q(s,a) 平面进行切片,将曲线平面截断成一条曲线,并寻找最高点对应的横坐标,即最大Q值对应的动作。
∇
θ
J
(
θ
)
≈
E
s
t
∼
ρ
β
[
∇
a
Q
(
s
t
,
a
)
∣
a
=
μ
θ
(
s
t
)
∇
θ
μ
θ
(
s
t
)
]
\nabla_\theta J(\theta)\approx\mathbb{E}_{s_t\sim\rho^\beta}\left[\nabla_aQ\left.(s_t,a)\right|_{a=\mu_\theta(s_t)}\nabla_\theta\mu_\theta(s_t)\right]
∇θJ(θ)≈Est∼ρβ[∇aQ(st,a)∣a=μθ(st)∇θμθ(st)]
ρ
β
\rho^{\beta}
ρβ 是策略的初始分布。
DDPG
在强化学习发展的算法中,主要关注两个方面:如何提高对值函数的估计,以及如何提高探索-利用的问题。通过深度学习,如增加目标网络、经验回访、引入噪声等操作,提高策略的探索性。
引入噪声的目的是在不破坏系统的前提下,提高系统运行的抗干扰性,譬如人体接种疫苗,在接种疫苗后,面对真正的病毒就有了一定的抵御能力。在噪声中使用一种OU噪声,具有回归特性的随机过程,拥有稳定性和可控性,同时更加平滑且可以控制噪声的幅度。较大的方差增加探索性、较小的方差增加利用性。
OU噪声有随即高斯噪声和回归项组成:
d
x
t
=
θ
(
μ
−
x
t
)
d
t
+
σ
d
W
t
dx_t=\theta\left(\mu-x_t\right)dt+\sigma dW_t
dxt=θ(μ−xt)dt+σdWt
x
t
x_t
xt是OU在时间t的值,也是强化学习中的时步。
μ
\mu
μ 是回归到的均值,表示噪声的平均值。
θ
\theta
θ 是OU过程中的回归速率,表示噪声向均值回归的速率。
σ
\sigma
σ 是OU过程的扰动项,表示随即高斯噪声的标准差。
d
W
t
dW_t
dWt 是随即向,可以称为维纳过程,表示随机高斯噪声的微小变化。实际过程中只需要调整
μ
\mu
μ 和
σ
\sigma
σ 。
DDPG算法实战
伪代码如下图所示:

训练参数如下: ================================================================================ 参数名 参数值 参数类型 algo_name DDPG <class 'str'> env_name Pendulum-v1 <class 'str'> train_eps 300 <class 'int'> test_eps 20 <class 'int'> max_steps 10000 <class 'int'> gamma 0.99 <class 'float'> critic_lr 0.001 <class 'float'> actor_lr 0.0001 <class 'float'> memory_capacity 8000 <class 'int'> batch_size 128 <class 'int'> target_update 2 <class 'int'> tau 0.01 <class 'float'> critic_hidden_dim 256 <class 'int'> actor_hidden_dim 256 <class 'int'> device cuda <class 'str'> seed 1 <class 'int'> ================================================================================ 开始训练! 回合:10/300,奖励:-79102.93 回合:20/300,奖励:-52642.69 回合:30/300,奖励:-77790.13 回合:40/300,奖励:-46309.66
...
回合:18/20,奖励:-84630.12 回合:19/20,奖励:-44238.94 回合:20/20,奖励:-75457.45 完成测试!
可能由于参数的问题,得到的结果并不太好: