项目开源地址:https://github.com/ZiwenZhuang/parkour
摘要:
跑酷对腿部机动性是一项巨大的挑战,要求机器人在复杂环境中快速克服各种障碍。现有方法可以生成多样化但盲目的机动技能,或者是基于视觉但专门化的技能,这些技能通过使用参考动物数据或复杂的奖励来实现。然而,自主跑酷需要机器人学习既基于视觉又多样化的技能,以感知并应对各种情景。在这项工作中,我们提出了一种系统,用于学习一个单一的端到端基于视觉的跑酷策略,该策略具有多样化的跑酷技能,并使用简单的奖励,而不需要任何参考动作数据。我们开发了一种受直接配置启发的强化学习方法来生成跑酷技能,包括翻越高障碍、跳过大裂缝、在低障碍下爬行、挤过窄缝以及奔跑。我们将这些技能蒸馏成一个单一的基于视觉的跑酷策略,并将其转移到使用自身中心深度相机的四足机器人上。我们证明了我们的系统可以使两种不同的低成本机器人自主选择和执行适当的跑酷技能,以穿越具有挑战性的现实世界环境。
方法:
我们的目标是构建一个端到端的跑酷系统,该系统直接使用原始的机载深度感知和本体感知来控制低成本机器人的每个关节,以执行各种敏捷的跑酷技能,如翻越高障碍、跳过大裂缝、在低障碍下爬行、挤过窄缝和奔跑。与之前使用不同方法和训练方案针对不同运动技能的工作不同,我们旨在自动和系统地生成这五种跑酷技能。为了实现这一目标,我们开发了一种受直接配置启发的两阶段强化学习方法,在同一个框架下学习这些跑酷技能。在RL预训练阶段,我们允许机器人穿透障碍物,使用自动课程强制执行软动力学约束。我们鼓励机器人逐渐学会克服这些障碍物,同时最小化穿透和机械能量。在RL微调阶段,我们使用现实动力学对预训练的行为进行微调。在这两个阶段,我们只使用一个简单的奖励函数,激励机器人向前移动,同时保存机械能量。在学会每个单独的跑酷技能后,我们使用DAgger将它们蒸馏成一个单一的基于视觉的跑酷策略,可以进行部署。为了在低成本机器人上实现稳健的实物到实际的部署,我们采用了几种深度图像的预处理技术,校准了机载视觉延迟,并采取了主动的电机安全措施。
- 通过两阶段强化学习学习跑酷技能
由于渲染深度图像的成本较高,且直接在视觉数据上训练强化学习(RL)并不总是稳定的,我们利用有关环境的特权视觉信息来帮助RL在模拟中生成专门的跑酷技能。特权视觉信息包括机器人当前位置到机器人前方障碍物的距离、障碍物的高度、障碍物的宽度,以及代表四种障碍类型的4维单热编码。我们将每个专门技能策略构建为一个门控循环神经网络(GRU)。除了循环潜在状态外,策略的输入还包括本体感知 s proprio t ∈ R 29 s_{\text{proprio}}^t \in \mathbb{R}^{29} spropriot∈R29(包括俯仰、基座角速度、关节位置和速度等)、上一次的动作 a t − 1 ∈ R 12 a_{t-1} \in \mathbb{R}^{12} at−1∈R12(用于约束策略的更新幅度,过于剧烈的策略更新可能导致无法收敛)、特权视觉信息 e vis t e_{\text{vis}}^t evist和特权物理信息 e phy t e_{\text{phy}}^t ephyt。我们采用与先前工作类似的方法来采样物理属性,如地形摩擦力、机器人基座的质心、电机强度等,以实现从模拟到真实世界的领域适应。策略输出目标关节位置 a t ∈ R 12 a_t \in \mathbb{R}^{12} at∈R12。
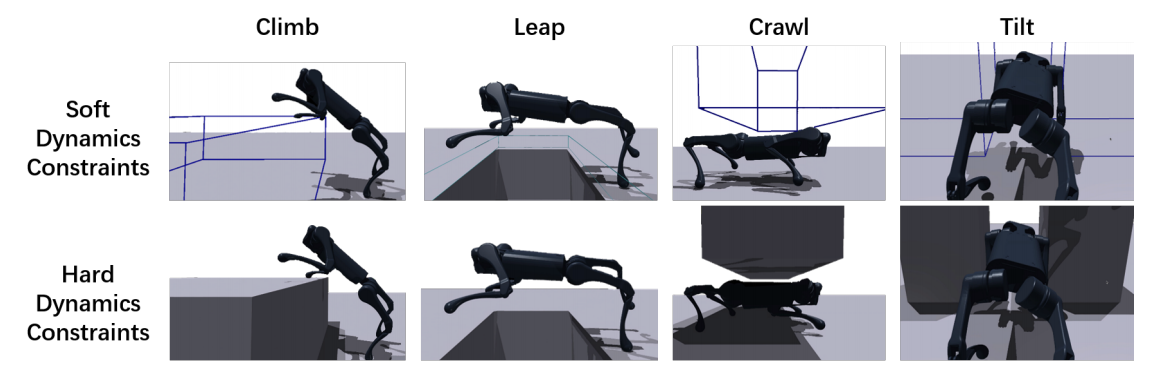
图3:每项技能的软动力学约束和硬动力学约束。在软动力学约束下,障碍物是可穿透的。
我们在图3中展示的相应地形上分别训练所有专门技能策略
π
climb
\pi_{\text{climb}}
πclimb,
π
leap
\pi_{\text{leap}}
πleap,
π
crawl
\pi_{\text{crawl}}
πcrawl,
π
tilt
\pi_{\text{tilt}}
πtilt,
π
run
\pi_{\text{run}}
πrun,使用相同的奖励结构。我们采用在文献[35]中提出的最小化机械能量的方法来导出一个适合生成所有自然动作技能的通用技能奖励
r
skill
r_{\text{skill}}
rskill,它只包含三个部分,前进奖励
r
forward
r_{\text{forward}}
rforward,能量奖励
r
energy
r_{\text{energy}}
renergy和生存奖励
r
alive
r_{\text{alive}}
ralive:
r
skill
=
r
forward
+
r
energy
+
r
alive
,
r_{\text{skill}} = r_{\text{forward}} + r_{\text{energy}} + r_{\text{alive}},
rskill=rforward+renergy+ralive,
其中
r
forward
=
−
α
1
⋅
∣
v
x
−
v
x
target
∣
−
α
2
⋅
∣
v
y
∣
2
+
α
3
⋅
e
−
∣
ω
yaw
∣
,
r_{\text{forward}} = -\alpha_1 \cdot |v_x - v_{x_{\text{target}}}| - \alpha_2 \cdot |v_y|^2 + \alpha_3 \cdot e^{-|\omega_{\text{yaw}}|},
rforward=−α1⋅∣vx−vxtarget∣−α2⋅∣vy∣2+α3⋅e−∣ωyaw∣,
r
energy
=
−
α
4
⋅
∑
j
∈
joints
∣
τ
j
q
˙
j
∣
2
,
r_{\text{energy}} = -\alpha_4 \cdot \sum_{j \in \text{joints}} |\tau_j \dot{q}_j|^2,
renergy=−α4⋅∑j∈joints∣τjq˙j∣2,
r
alive
=
2.
r_{\text{alive}} = 2.
ralive=2.
每个时间步测量,
v
x
v_x
vx是前向基座线速度,
v
x
target
v_{x_{\text{target}}}
vxtarget是目标速度,
v
y
v_y
vy是横向基座线速度,
ω
yaw
\omega_{\text{yaw}}
ωyaw是基座偏航角速度,
τ
j
\tau_j
τj是关节
j
j
j处的扭矩,
q
˙
j
\dot{q}_j
q˙j是关节
j
j
j处的关节速度,而
α
\alpha
α 是超参数。我们将所有技能的目标速度设定为约1米/秒。我们使用每个关节处电机功率的平方来减少所有关节上电机功率的平均值和方差。所有超参数的详细信息请参见补充材料。
- 在软动力学约束下的强化学习(RL)预训练。
如图2所示,跑酷技能的复杂学习环境阻碍了通用RL算法有效地找到能够克服这些挑战性障碍的策略。受到带有软约束的直接配置法的启发,我们提出使用软动力学约束来解决这些困难的探索问题。如图3所展示,我们设置障碍物为可穿透的,使得机器人可以在模拟中违反物理动力学直接穿过障碍物,而不会因为使用真实动力学即硬动力学约束的RL训练的局部最小值而陷于障碍物附近。类似于直接配置法中的拉格朗日表述,我们开发了一个穿透奖励
r
penetrate
r_{\text{penetrate}}
rpenetrate逐渐执行动力学约束,并设计了一个自动课程来适应性地调整障碍物的难度。这个想法也在机器人操作中被探索过。如图4所示,为了测量动力学约束违反的程度,我们在机器人的碰撞体内采样碰撞点,以测量穿透的体积和深度。由于机器人的臀部和肩部包含了所有的电机,我们在这些体积周围采样更多的碰撞点以强制执行更强的动力学约束,鼓励在现实世界中这些脆弱部位的碰撞减少。将碰撞体上的一个碰撞点表示为
p
p
p,表示
p
p
p是否违反软动力学约束的指示函数为
I
[
p
]
\mathbb{I}[p]
I[p],
p
p
p到被穿透障碍物表面的距离为
d
(
p
)
d(p)
d(p)。穿透的体积可以通过所有碰撞点上的
I
[
p
]
\mathbb{I}[p]
I[p]之和来近似,穿透的平均深度可以通过
d
(
p
)
d(p)
d(p)之和来近似。在图4中,违反软动力学约束的碰撞点(
I
[
p
]
=
1
\mathbb{I}[p] = 1
I[p]=1)为红色,而
I
[
p
]
=
0
\mathbb{I}[p] = 0
I[p]=0的为绿色。具体来说,穿透奖励定义为
r
penetrate
=
−
∑
p
(
α
5
⋅
I
[
p
]
+
α
6
⋅
d
(
p
)
)
⋅
v
x
,
r_{\text{penetrate}} = - \sum_{p} (\alpha_5 \cdot \mathbb{I}[p] + \alpha_6 \cdot d(p)) \cdot v_x,
rpenetrate=−∑p(α5⋅I[p]+α6⋅d(p))⋅vx,
其中
α
5
\alpha_5
α5和
α
6
\alpha_6
α6是两个固定常数。我们将穿透体积和穿透深度与前向基座速度
v
x
v_x
vx相乘,以防止机器人通过快速穿越障碍物来利用穿透奖励,从而避免随时间累积过高的惩罚。此外,我们实施了一个自动课程,该课程在重置后根据在模拟中并行模拟的个别机器人的性能自适应地调整障碍物的难度。我们首先根据机器人在重置前一集的平均穿透奖励来计算其性能。如果穿透奖励超过一个阈值,我们将机器人将要面对的障碍物的难度得分
s
s
s增加一个单位(0.05);如果较低,则减少一个单位。每个机器人起始难度得分为0,最大难度得分为1。我们根据难度得分通过公式
(
1
−
s
)
⋅
l
easy
+
s
⋅
l
hard
(1 - s) \cdot l_{\text{easy}} + s \cdot l_{\text{hard}}
(1−s)⋅leasy+s⋅lhard设置机器人的障碍物属性,其中
l
easy
l_{\text{easy}}
leasy和
l
hard
l_{\text{hard}}
lhard是与不同跑酷技能相对应的障碍物属性范围的两个极限(如表1所示)。我们使用PPO算法预训练具有软动力学约束的专门跑酷技能,奖励函数为通用技能奖励和穿透奖励之和
r
skill
+
r
penetrate
r_{\text{skill}} + r_{\text{penetrate}}
rskill+rpenetrate。
- 在硬(现实)动力学约束下的强化学习微调。
在强化学习(RL)的预训练阶段接近收敛之后,我们在现实的硬动力学约束下(如图3所示)对每个专门的跑酷技能策略进行微调;因此,在RL的第二阶段,机器人与障碍物之间不可能发生穿透。我们使用PPO算法,并仅使用通用技能奖励 r skill r_{\text{skill}} rskill 来微调这些专门技能。在微调过程中,我们从表1中列出的范围内随机采样障碍物属性。由于跑步技能是在没有障碍物的地形上训练的,我们直接在硬动力学约束下训练跑步技能,并跳过带有软动力学约束的RL预训练阶段。
- 通过蒸馏学习单一跑酷策略
学习到的专门跑酷技能是五个策略,它们既使用特权视觉信息
e
vis
t
e_{\text{vis}}^t
evist,也使用特权物理信息
e
phy
t
e_{\text{phy}}^t
ephyt。然而,真实的特权信息在真实世界中是不可获得的,只能在模拟中获得。此外,每个专门策略只能执行一种技能,并且不能基于对环境的视觉感知自主地执行和切换不同的跑酷技能。我们提出使用DAgger来蒸馏一个单一的基于视觉的跑酷策略
π
parkour
\pi_{\text{parkour}}
πparkour,仅使用来自五个专门技能策略
π
climb
,
π
leap
,
π
crawl
,
π
tilt
,
π
run
\pi_{\text{climb}}, \pi_{\text{leap}}, \pi_{\text{crawl}}, \pi_{\text{tilt}}, \pi_{\text{run}}
πclimb,πleap,πcrawl,πtilt,πrun的机载感测。我们从表1中随机抽取障碍物类型和属性,形成一个由40条轨道和每条轨道上20个障碍物组成的模拟地形。

图8:在蒸馏过程中模拟中的跑酷训练环境。
由于我们完全了解与每个状态 s t s_t st相关的障碍物类型,我们可以指派相应的专门技能策略 π s specialized t \pi_{s_{\text{specialized}}}^t πsspecializedt来教授跑酷策略在某个状态下如何行动。例如,我们指派爬行策略 π climb \pi_{\text{climb}} πclimb来监督跑酷策略应对高障碍。我们将策略参数化为GRU。输入除了循环潜在状态外,还包括本体感知 s proprio t s_{\text{proprio}}^t spropriot、前一个动作 a t − 1 a_{t-1} at−1和通过小型CNN处理的深度图像 I t depth I_{t_{\text{depth}}} Itdepth的潜在嵌入。蒸馏目标是
arg min θ parkour E s t , a t ∼ π parkour , sim [ D ( π parkour ( s proprio t , a t − 1 , I t depth ) , π s specialized t ( s proprio t , a t − 1 , e vis t , e phy t ) ) ] , \text{arg min}_{\theta_{\text{parkour}}} E_{s_t, a_t \sim \pi_{\text{parkour}}, \text{sim}} \left[ D \left( \pi_{\text{parkour}} \left( s_{\text{proprio}}^t, a_{t-1}, I_{t_{\text{depth}}} \right), \pi_{s_{\text{specialized}}}^t \left( s_{\text{proprio}}^t, a_{t-1}, e_{\text{vis}}^t, e_{\text{phy}}^t \right) \right) \right], arg minθparkourEst,at∼πparkour,sim[D(πparkour(spropriot,at−1,Itdepth),πsspecializedt(spropriot,at−1,evist,ephyt))],
(类似教师-学生框架,专门技能网络 π s specialized t \pi_{s_{\text{specialized}}}^t πsspecializedt是教师,拥有特权信息的输入,跑酷策略 π parkour \pi_{\text{parkour}} πparkour是学生,散度函数就是求两者的区别,最终优化目标就是最小化两者的期望区别)
其中 θ parkour \theta_{\text{parkour}} θparkour是跑酷策略的网络参数,sim 是具有硬动力学约束的模拟器,D 是散度函数,对于最后一层为tanh的策略网络采用二元交叉熵损失。策略 π parkour \pi_{\text{parkour}} πparkour和 π s specialized t \pi_{s_{\text{specialized}}}^t πsspecializedt 均为有状态的。跑酷策略网络的更多细节请参见补充材料。
- Sim-to-Real和部署
尽管3.2节中的蒸馏训练可以弥合物理动力学属性(如地形摩擦力和机器人的质量属性)之间的模拟到现实的差距,但我们仍需解决模拟中渲染的深度图像与真实世界中深度摄像头拍摄的机载深度图像在视觉外观上的模拟到现实差距。如图5所示,我们对原始渲染的深度图像和原始真实世界的深度图像都应用了预处理技术。我们对原始渲染的深度图像应用深度裁剪、像素级高斯噪声和随机伪影处理,并对原始真实世界的深度图像应用深度裁剪、孔洞填充、空间平滑和时间平滑处理。
模拟和真实世界中的深度图像分辨率均为48*64。由于机载计算能力有限,机载深度图像的刷新率为10Hz。我们的跑酷策略在模拟和真实世界中均以50Hz的频率运行,以实现敏捷的运动技能,并异步获取由小型CNN处理的深度图像的最新潜在嵌入。策略的输出动作是目标关节位置,通过PD控制器(Kp=50,Kd=1)转换为1000Hz的扭矩。为确保安全部署,我们通过裁剪目标关节位置应用了25Nm的扭矩限制:clip( q target q_{\text{target}} qtarget, (Kd * q ˙ \dot{q} q˙- 25)/Kp + q, (Kd * q ˙ \dot{q} q˙+ 25)/Kp + q)。
实验结果:
机器人与模拟设置:我们使用IsaacGym作为模拟器来训练所有的策略。为了训练专门的跑酷技能,我们构建了由40个轨道和每个轨道上20个障碍物组成的大型模拟环境。每条轨道上的障碍物难度根据表1中的障碍物属性范围线性递增。我们使用配备Nvidia Jetson NX的Unitree A1和Unitree Go1进行机载计算,并使用Intel RealSense D435进行机载视觉感测。更多细节请参见补充材料。
baseline与消融实验:我们将我们的跑酷策略与几个baseline和消融实验进行了比较。baseline包括Blind, RND , MLP and RMA。消融实验包括无蒸馏(No Distill)和没有软动力学的先知(Oracles w/o Soft Dyn)。为了比较的完整性,我们还包括了在模拟中基于特权信息的专门跑酷技能,称为先知(Oracles)。
| 策略名称 | 描述 |
|---|---|
| Blind | 从专门技能中蒸馏出的盲跑酷策略baseline,通过将深度图像 I depth I_{\text{depth}} Idepth设为零来实现。 |
| RND | 一种基于前向预测误差(?)的奖励的RL探索baseline方法,用于训练专门技能。我们没有在软动力学约束上进行我们的RL预训练。 |
| 多层感知机(MLP) | 从专门技能中蒸馏出的MLP跑酷策略baseline。不使用GRU,只在当前时间步使用深度图像、本体感知和前一个动作,没有任何记忆输出动作。 |
| RMA | 一个域适应baseline,它在环境外部特征的潜在空间上而不是动作空间上蒸馏跑酷策略。 |
| 无蒸馏(No Distill) | 直接使用PPO通过我们的两阶段RL方法训练一个基于视觉的跑酷策略,但跳过蒸馏阶段。 |
| 无软动力学的先知(Oracles w/o Soft Dyn) | 直接使用特权信息在硬动力学约束下训练专门技能策略的消融实验。 |
| 先知(Oracles w/ Soft Dyn) | 使用我们的两阶段RL方法和特权信息训练的专门技能策略。 |
- 仿真实验
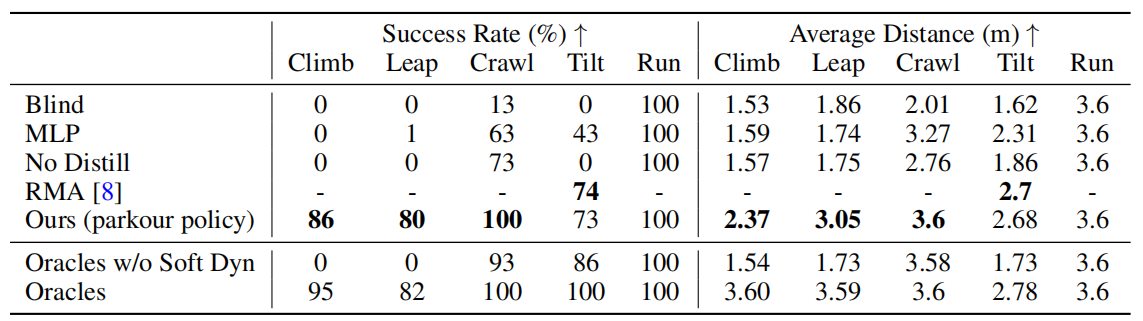
表2:我们在最大距离为3.6米的模拟环境中将我们的方法与几个基线和消融实验进行了对比测试。我们测量了每项技能在100次试验和3个随机种子下的成功率和平均距离。我们的跑酷策略仅使用在真实世界中可用的传感器展示了最佳性能。我们在测试环境中进行评估,这些环境中的障碍物属性比表1中展示的训练环境中的障碍物更加困难。
视觉对于学习跑酷至关重要:我们将盲目baseline与我们的方法进行比较。如表2所示,没有深度感知,仅依靠本体感知,蒸馏出的盲目策略无法完成任何攀爬、跳跃或倾斜试验,而在爬行中仅能达到13%的成功率。这是预期的,因为视觉能够感知障碍物属性,并在接近障碍物时为机器人执行敏捷技能做准备。
通过软动力学约束的RL预训练能够促进跑酷技能的学习:我们比较了RND、无软动力学约束的先知(Oracles w/o Soft Dyn)和我们的方法(带有软动力学约束的先知,Oracles w/ Soft Dyn),所有方法都使用了特权信息,但没有进行蒸馏阶段的训练。我们旨在验证我们的软动力学约束下的RL预训练方法能否进行有效的探索。
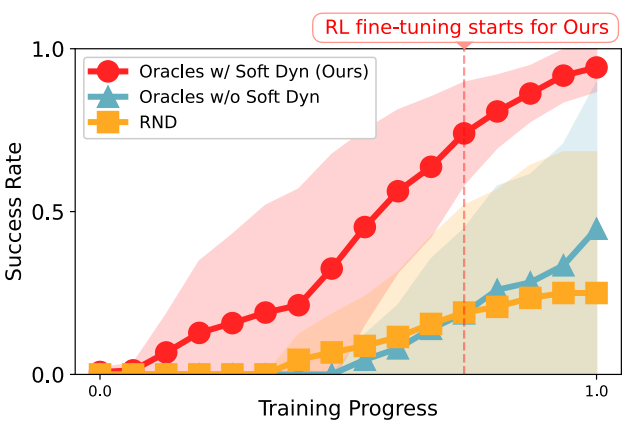
图7:使用软动力学约束训练的专门先知与基线的比较,跨越每项技能和三次试验取平均值。
在图7中,我们测量了每种方法在包括攀爬、跳跃、爬行和倾斜在内的所有需要探索的跑酷技能上的平均成功率,平均值基于100次试验。我们使用三个随机种子为每种方法进行训练,以测量标准偏差。我们的方法通过软动力学约束下的RL预训练可以实现更快的学习进度和约95%的更高最终成功率。我们注意到,RND在需要精细操作的场景中(如通过窄缝爬行)难以学习到有意义的行为,这是因为它倾向于达到未来状态难以预测的状态。RND和无软动力学约束的先知在攀爬和跳跃这两项最困难的跑酷技能上无法取得任何学习进度。更多显示每项技能单独成功率的图表请参见补充材料。
循环网络使需要记忆的跑酷技能成为可能:我们将使用GRU来参数化基于视觉的跑酷策略的我们的方法与MLP baseline进行比较。如表2所示,MLP baseline无法学习攀爬和跳跃技能,并且在爬行和倾斜上的表现也要低得多。攀爬和跳跃都要求机器人保持对过去视觉感知的短期记忆。例如,在攀爬过程中,当机器人的前腿在障碍物上时,它仍需要记住过去深度图像中捕获的障碍物的空间尺寸,以控制后腿完成攀爬。
蒸馏对于模拟到现实(Sim2Real)是有效的:我们将RMA baseline和无蒸馏(No Distill)baseline与我们的方法进行比较。虽然RMA可以在其训练的一个技能上,即倾斜,达到类似的表现,但RMA固定了处理主干GRU潜在嵌入的MLP的网络参数,并直接从专门技能复制到蒸馏策略。因此,它无法将具有不同MLP参数的多个专门技能策略蒸馏到一个跑酷策略中。由于直接从视觉观察训练的复杂性以及没有特权信息,无蒸馏无法学习攀爬、跳跃和倾斜。
- 真实世界实验
见项目网站:https://robot-parkour.github.io/
结论:
我们提出了一套面向低成本机器人的跑酷学习系统。我们提出了一种两阶段强化学习方法,用于克服学习跑酷技能时的困难探索问题。我们还在模拟和真实世界中对我们的系统进行了广泛测试,并展示了我们的系统在具有挑战性的室内和户外环境中对各种具有挑战性的跑酷技能具有稳健的表现。然而,当前系统需要手动构建模拟环境。因此,只有在模拟中添加了具有不同障碍物和外观的新环境时,才能学习新技能。这减少了新技能可以自动学习的程度。未来,我们希望利用最近在3D视觉和图形学中的进展,自动从大规模真实世界数据构建多样化的模拟环境。我们还将研究如何直接从包含语义信息的RGB图像而不是深度图像中训练敏捷的运动技能。