强化学习笔记
主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门.
第一章 强化学习基本概念
第二章 贝尔曼方程
第三章 贝尔曼最优方程
第四章 值迭代和策略迭代
文章目录
- 强化学习笔记
- 一、Value Iteration
- 1 原理
- 2 实例
- 二、Policy Iteration
- 1 原理
- 2 实例
- 参考资料
一、Value Iteration
1 原理
上一章讲贝尔曼最优方程(BOE)时,介绍了如何求解贝尔曼最优方程,将压缩映射原理应用到BOE上,我们得到了一个求解BOE的迭代算法,而那个迭代算法就是Value Iteration.回顾一下迭代算法的格式:
v
k
+
1
=
f
(
v
k
)
=
max
π
(
r
π
+
γ
P
π
v
k
)
,
k
=
1
,
2
,
3
…
v_{k+1}=f(v_k)=\max_{\pi}(r_\pi+\gamma P_\pi v_k),\quad k=1,2,3\ldots
vk+1=f(vk)=πmax(rπ+γPπvk),k=1,2,3…这个迭代可以分解为两个步骤:
- 步骤1:策略更新
这一步就是根据 v k v_k vk,更新策略
π k + 1 = arg max π ( r π + γ P π v k ) \begin{aligned}\pi_{k+1}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{k})\end{aligned} πk+1=argπmax(rπ+γPπvk)- 步骤2:状态值更新
v k + 1 = r π k + 1 + γ P π k + 1 v k \begin{aligned}v_{k+1}&=r_{\pi_{k+1}}+\gamma P_{\pi_{k+1}}v_k\end{aligned} vk+1=rπk+1+γPπk+1vk
上面都是用向量的形式写的,我们来具体看一下每个状态 s s s每一步是怎么做的:


2 实例
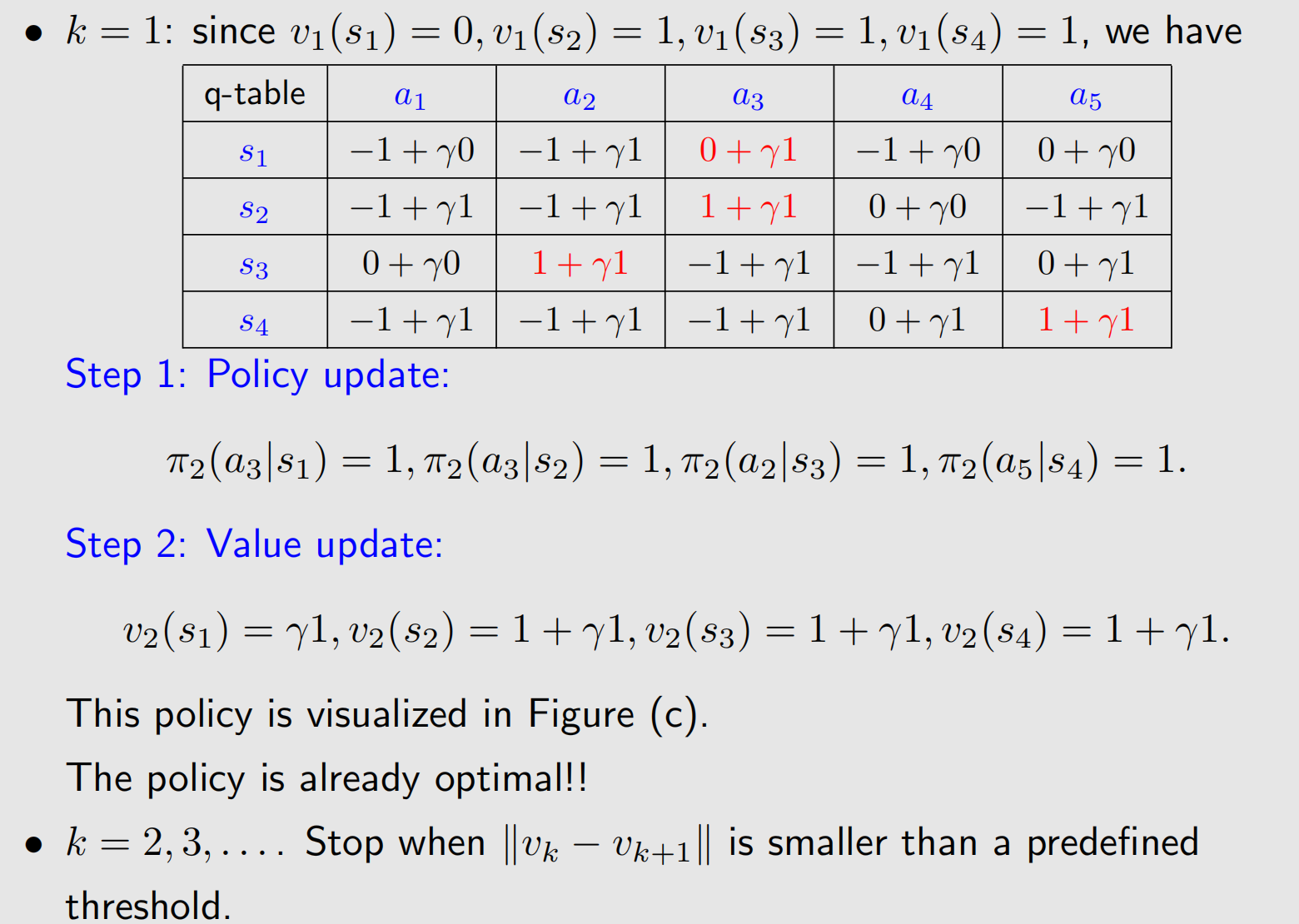
仍然来看agent-网格例子,下图的
a
1
,
a
2
,
a
3
,
a
4
,
a
5
a_1,a_2,a_3,a_4,a_5
a1,a2,a3,a4,a5分别代表向上、向右、向下、向左、原地不动.
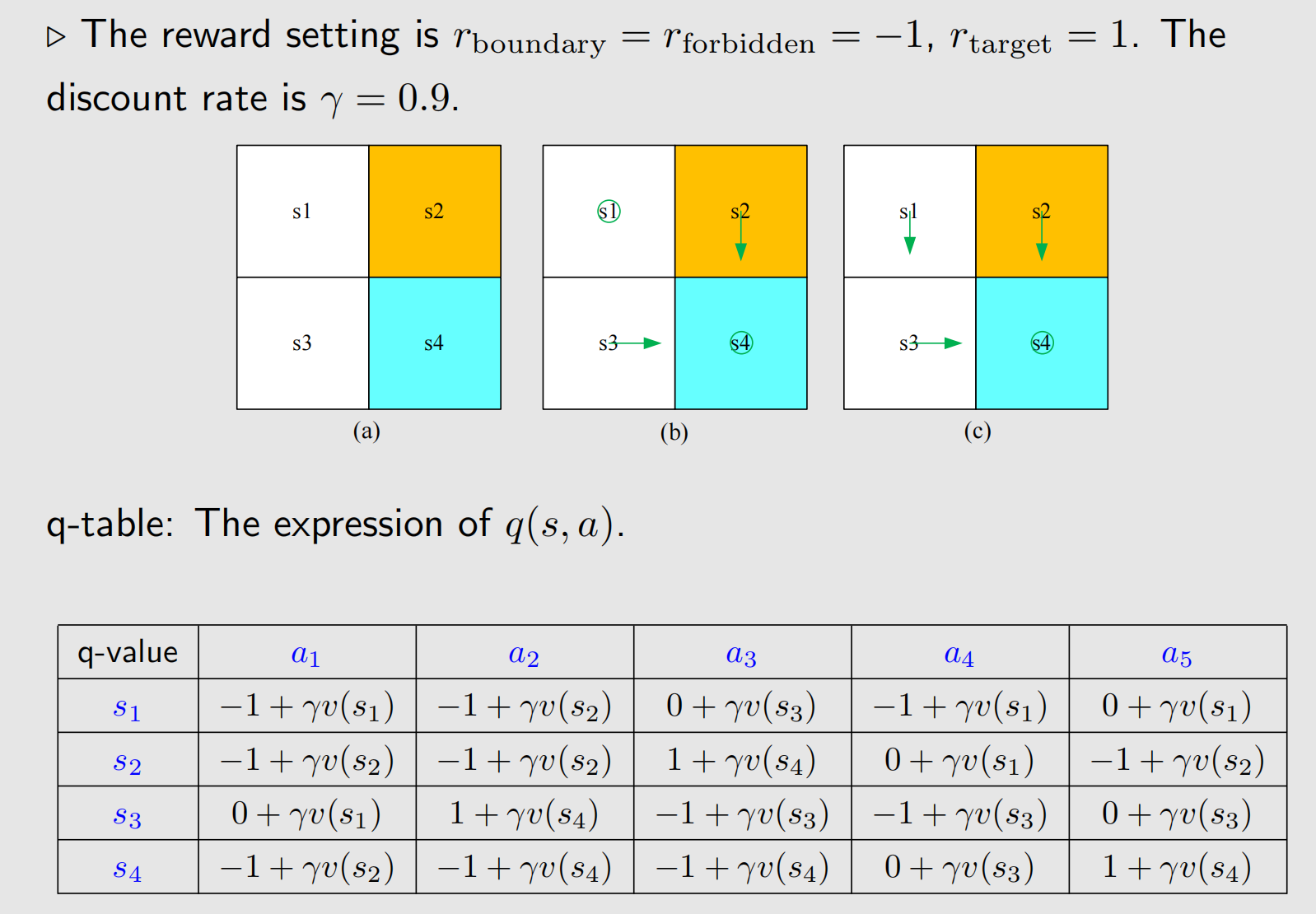
给定一个初始值 v 0 ( s ) v_0(s) v0(s),可以计算出 q 0 ( s , a ) q_0(s,a) q0(s,a),每个状态下选择最大的 q q q值对应的动作作为策略.
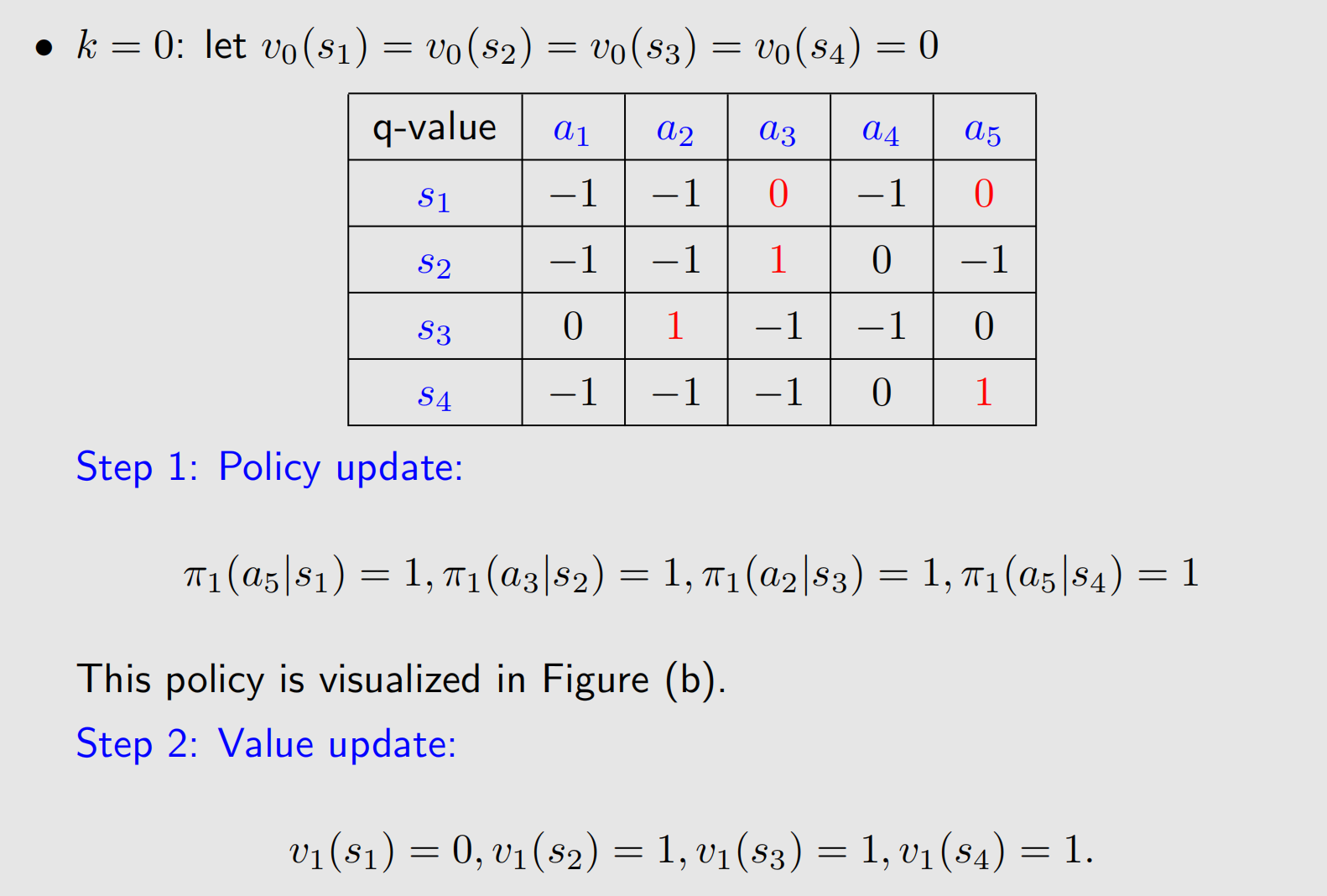
第一次迭代我们发现 s 1 s_1 s1的策略不是最优的,继续迭代,我们发现通过两次迭代就能得到最优策略,当然算法停止还得根据停机准则来.
二、Policy Iteration
1 原理
相较于值迭代算法,策略迭代算法是给定一个初始策略而不是给定一个初始的
v
v
v。下面首先介绍一下Policy Iteration算法框架:
- 首先给定随机初始策略 π 0 \pi_0 π0.
- 第一步:策略评估(PE)
这一步是计算 π k \pi_k πk的状态值 v π k v_{\pi_k} vπk是:
v π k = r π k + γ P π k v π k \begin{aligned}v_{\pi_k}&=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k}\end{aligned} vπk=rπk+γPπkvπk- 第二步:策略改进(Pl)
基于上一步算出的 v π k v_{\pi_k} vπk,更新策略:
π k + 1 = arg max π ( r π + γ P π v π k ) \pi_{k+1}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_k}) πk+1=argπmax(rπ+γPπvπk)
下面我们具体来看一下每一步是怎么做的,首先来看PE,我们发现给定了策略,我们要求的是 v π k v_{\pi_k} vπk,这不就是解贝尔曼方程吗!前面介绍过解贝尔曼方程的两种方法,所以这里我们同样可以用迭代法来求解得到一个 v π k v_{\pi_k} vπk的近似值.

再来看PI,得到
v
π
k
v_{\pi_k}
vπk之后我们需要更新策略,这里就和Value Iteration一样了,可以采用greedy policy的方式更新策略,根据
v
π
k
v_{\pi_k}
vπk计算
q
(
s
,
a
)
q(s,a)
q(s,a),选择每个状态最大的
q
q
q对应的动作即可。

值得注意的是在第二步策略更新中,我们更新的策略一定比原策略好吗?可以证明确实是这样的,详见参考资料对应的章节,只要通过这样的迭代一定会收敛到最优策略。
2 实例
仍然来看agent-网格例子,(a)中是给定的初始策略。
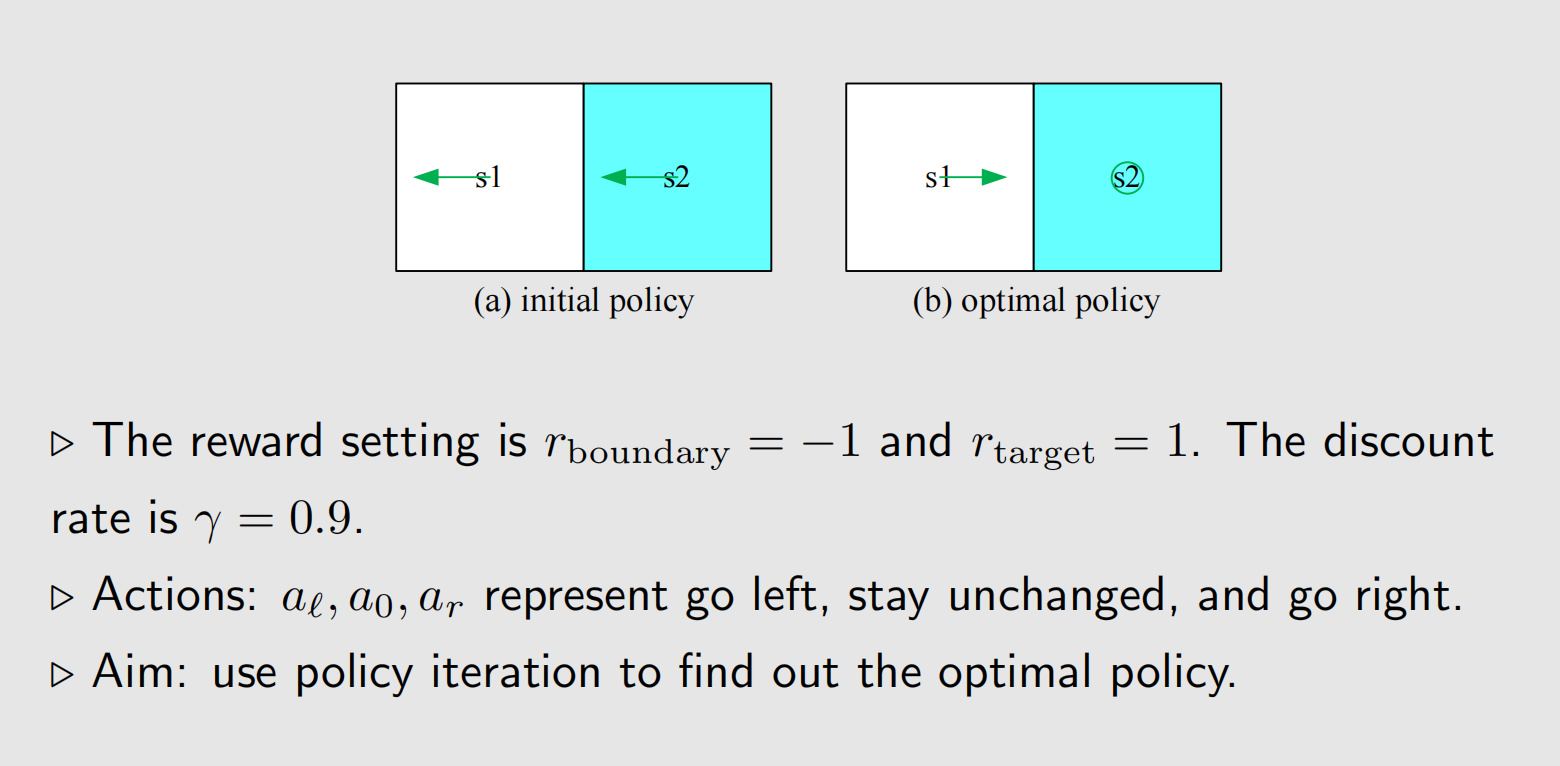
第一步就是解贝尔曼方程,下面给了两种方法,算法中常用的是迭代法.

第二步是策略改进,和Value Iteration一样的做法.

参考资料
- Zhao, S… Mathematical Foundations of Reinforcement Learning. Springer Nature Press and Tsinghua University Press.
- Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.