NVIDIA CEO Jen-Hsun Huang shows off the company’s latest and most advanced GPU yet.
深度学习模型性能的提升仰赖手工精细的调整。然而炼丹工作近似黑箱问题,可参照的纲领不多。显然,这不是程序员所期望的。算力和需求的增长使得神经架构搜索( Neural Architecture Search,NAS)重回人们的视线。NAS 可迁移性更强,能够以快速且简单粗暴的方式获得高精度模型,成为工程师称手的砖块。强化学习(RL)可谓 NAS 中的核武器,谷歌开启并引领该方向的工作。由初期燃烧的显卡到专用硬件,对效率的追求犹如挖矿一般。
NAS

NAS 可以看作是用强化学习搜索网络的发端,在 CIFAR-10上搜索网络结构,搜索空间的拓扑连接与 DenseNet 相同。使用循环网络生成神经网络的模型描述,并通过强化学习训练此 RNN,以最大化生成结构在验证集上的预期准确性。
NAS 将网络搜索任务表示为预测配置字符串,其中每个字符串可以指定构建网络所需的所有信息,例如层之间的连接以及它们的超参数。这些配置字符串是可变长度的,因此可以由循环网络生成。 在给定字符串的情况下构建子网络并训练其收敛。 使用子网络的期望性能度量作为奖励信号,可以计算策略梯度以更新主循环网络,使得它将在下一次迭代中采样更好的架构。
为使控制器提出跳过连接或分支层,从而扩大搜索空间,NAS 使用一个基于注意力的集合类型选择(Neural Programmer)。在第 N N N 层添加一个锚点,该锚点具有 N − 1 N-1 N−1 个基于目录的 sigmoids,用于指示需要连接的先前层。每个 sigmoid 都是控制器的当前隐藏状态和先前 N − 1 N-1 N−1 锚点对应隐藏状态的函数:
P ( L a y e r j i s a n i n p u t t o l a y e r i ) = s i g m o i d ( v T t a n h ( W p r e v ∗ h j + W c u r r ∗ h i ) ) , \mathrm{P(Layer \ j \ is \ an \ input \ to \ layer \ i) = \ } \mathrm{sigmoid}(v^\mathrm{T} \mathrm{tanh}(W_{prev}*h_{j} + W_{curr} * h_{i})), P(Layer j is an input to layer i)= sigmoid(vTtanh(Wprev∗hj+Wcurr∗hi)),
其中
h
j
h_j
hj 表示第
j
j
j 层锚点处控制器的隐藏状态,
j
j
j 的范围从
0
0
0 到
N
−
1
N-1
N−1。算法从这些 sigmoid 中采样,以确定将哪些先前层用作当前层的输入。矩阵
W
p
r
e
v
W_{prev}
Wprev、
W
c
u
r
r
W_{curr}
Wcurr 和
v
v
v 是可训练的参数。
下图显示了控制器如何使用跳过连接来决定它想要哪些层作为当前层的输入。

可以将控制器预测的令牌列表视为动作列表
a
1
:
T
a_{1:T}
a1:T 来设计子网络的体系结构。为了找到最佳架构,训练子模型至收敛,获得其在保留数据集上的精度
R
R
R。NAS 使用此精度
R
R
R 作为奖励信号,并使用强化学习来训练控制器。要求控制器最大化其预期奖励,由
J
(
θ
c
)
J(\theta_c)
J(θc) 表示:
J
(
θ
c
)
=
E
P
(
a
1
:
T
;
θ
c
)
[
R
]
J(\theta_c) = E_{P(a_{1:T};\theta_c)}[R]
J(θc)=EP(a1:T;θc)[R]
由于奖励信号
R
R
R 不可微分,NAS 使用策略梯度方法迭代更新
θ
c
\theta_c
θc。具体实现为 REINFORCE规则:
▽
θ
c
J
(
θ
c
)
=
∑
t
=
1
T
E
P
(
a
1
:
T
;
θ
c
)
[
▽
θ
c
log
P
(
a
t
∣
a
(
t
−
1
)
:
1
;
θ
c
)
R
]
\bigtriangledown_{\theta_c} J(\theta_c) = \sum_{t=1}^{T} E_{P(a_{1:T};\theta_c)}\big[\bigtriangledown_{\theta_c} \log P(a_t|a_{(t-1):1};\theta_c)R\big]
▽θcJ(θc)=t=1∑TEP(a1:T;θc)[▽θclogP(at∣a(t−1):1;θc)R]
上述未知数的经验近似值为:
1
m
∑
k
=
1
m
∑
t
=
1
T
▽
θ
c
log
P
(
a
t
∣
a
(
t
−
1
)
:
1
;
θ
c
)
R
k
\frac{1}{m} \sum_{k=1}^{m} \sum_{t=1}^{T} \bigtriangledown_{\theta_c} \log P(a_t|a_{(t-1):1};\theta_c)R_{k}
m1k=1∑mt=1∑T▽θclogP(at∣a(t−1):1;θc)Rk
其中 m m m 是控制器在一个批次中采样的不同架构的数量,而 T T T 是控制器设计神经网络架构需预测的超参数的数量。第 k k k 个神经网络架构在训练数据集上训练后达到的验证精度为 R k R_k Rk。
上述更新是对梯度的无偏估计,但具有非常高的方差。为此,NAS 采用基线函数:
1 m ∑ k = 1 m ∑ t = 1 T ▽ θ c log P ( a t ∣ a ( t − 1 ) : 1 ; θ c ) ( R k − b ) \frac{1}{m} \sum_{k=1}^{m} \sum_{t=1}^{T} \bigtriangledown_{\theta_c} \log P(a_t|a_{(t-1):1};\theta_c)(R_{k} - b) m1k=1∑mt=1∑T▽θclogP(at∣a(t−1):1;θc)(Rk−b)
只要基线函数 b b b 不依赖于当前操作,那么这仍然是无偏的梯度估计。NAS 使用先前架构精度的指数移动平均值作为基线 b b b。
搜索空间由卷积结构组成,带有 ReLU、BN 和跳跃连接。对于每个卷积层,控制器 RNN 必须选择[1,3,5,7]中的滤波器高度,[1,3,5,7]中的滤波器宽度,以及[24, 36, 48, 64]中的滤波器个数。
框架中如果一个层有多个输入,则将输入特征图的通道拼接在一起。跳跃连接会导致“编译失败”,其中一个层与另一个层不兼容,或者一个层可能没有任何输入或输出。为了解决这些问题,文中采用了三种简单的技术:
- 如果该层没有输入层连接,则将图像作为输入。
- 最后一层获取所有未连接的层输出,将它们拼接起来送到分类器。
- 如果要连接的输入具有不同的大小,则用零填充补齐。
控制器 RNN 是两层 LSTM,每层有35个隐藏单元。采用谷歌所擅长的分布式训练,计算资源为 Nvidia K40 GPU x800。子网络起始有6层,每隔两轮增加两层。
最终的网络连接非常复杂。
 NAS" />
NAS" />
MetaQNN
MetaQNN 通过基于强化学习的元建模程序来自动化 CNN 结构选择过程。学习代理使用 Q Q Q-learning 和 ϵ \epsilon ϵ-greedy 探索策略[DQN]和经验回放训练,能够顺序选择 CNN 层。代理在大而有限的空间中探索合适的架构,并迭代地发现能够提升学习任务性能的设计。和 NAS一样,代理以模型的验证精度作为结构选择的奖励。经验回放的重复记忆采样能够加快学习过程。在图像分类任务中,代理设计的网络仅由标准卷积、池化和完全连接的层组成。代码 bowenbaker/metaqnn 基于 PyTorch。
图 Figure 1 显示了可行的状态和动作空间 (a) 以及代理选择 CNN 结构的潜在轨迹 (b) 。MetaQNN 将层选择过程建模为马尔可夫决策过程,假设一个网络中性能良好的层也应该在另一个网络中表现良好。

MetaQNN 方法需要三个主要的设计选择:
- 将 CNN 层定义化简为状态元组;
- 定义代理可以采取的一组动作,即给定其当前状态的情况下代理可取的一组层;
- 平衡状态操作空间大小、模型容量和代理收敛所需的探索量。
每个状态都定义为所有相关层参数的元组。MetaQNN 设置五种候选层类型:
- 卷积(C)
- 池化(P)
- 全连接(FC)
- 全局平均池化(GAP)
- softmax(SM)
表 Table 1 显示每种层类型的相关参数以及可取值。每个层都有一个参数 layer depth(在图Figure 2 中显示为 Layer 1 , 2 , . . . 1, 2, ... 1,2,...)。利用 layer depth 可以限制动作空间,使得状态—动作图是有向无环图(DAG),并且还能指定代理在终止之前可以选择的最大层数。


每种层类型还有一个名为表示大小的参数(
R
R
R-size)。卷积网络通过池化和卷积逐步压缩原始信号的表示。状态空间中的这些层可能导致轨迹上的中间信号表示缩减到太小而不能进一步处理。为了避免这种情况,MetaQNN 将
R
R
R-size 参数添加到状态元组
s
s
s 中,对于
R
R
R-size 为
n
n
n 的状态,操作的感受野应小于或等于
n
n
n。为了进一步限制状态空间,MetaQNN 将表示大小分成三个不连续的桶。
对于动作空间的限制为:
- 允许代理在任意点上终止路径,即它可以从任何非终止状态中选择终止状态。
- 只允许层深度为 i i i 的状态转换为层深度为 i + 1 i+1 i+1 的状态,这样可确保图中没有循环。 此约束可确保状态—操作图始终为 DAG。表 Table 1 中规定的最大层深度的任何状态都只能转换到终止层。
- 限制全连接(FC)层的数量为最多两个,因为大量的 FC 层可能导致可学习参数过多。
- 禁止连续的池化层,因为这等同于状态空间之外的单个更大的池化层。
- 仅表示大小为 ( 8 , 4 ] (8, 4] (8,4] 和 ( 4 , 1 ] (4, 1] (4,1] 区间的状态可以转换到 FC 层,这可以确保权重的数量不会变得非常大。
NASNet
NASNet 在较小的代理数据集上搜索搜索基本单元(Normal Cell 和 Reduction Cell),然后迁移到 ImageNet 上。为此,
- NASNet 设计搜索空间(称之为“NASNet 搜索空间”)使得架构的复杂性与网络的深度和输入图像的大小无关。
- 引入一种称为 ScheduledDropPath 的新正则化技术,显着改善了 NASNet 模型的泛化能力。
NASNet 搜索空间中的所有卷积网络都由具有相同结构但不同权重的卷积层(或“单元”)组成。 因此,寻找最佳卷积架构简化为搜索最佳单元结构。 搜索最佳单元结构有两个主要好处:它比搜索整个网络架构快得多,并且单元本身更有可能推广到其他问题。
NASNet 将搜索空间分层:

NASNet 的搜索空间中,每个单元接收两个初始隐藏状态
h
i
h_i
hi 和
h
i
−
1
h_{i-1}
hi−1 作为输入,它们是前两个单元的输出或者是网络的输入图像。在给定这两个初始隐藏状态的情况下,控制器 RNN 递归地预测卷积单元的其余结构(图3)。控制器对每个单元的预测分组为
B
B
B 个块,其中每个块具有5个预测步骤,5个相应的 softmax 分类器对块中元素进行离散选择:
- 步骤1. 从 h i h_i hi 和 h i − 1 h_{i-1} hi−1 或先前块创建的隐藏状态集中选择第一个隐藏状态作为输入。
- 步骤2. 从与步骤1中相同的选项中选择第二个隐藏状态。
- 步骤3. 选择应用于第一个隐藏状态的操作。
- 步骤4. 选择应用于第二个隐藏状态的操作。
- 步骤5. 选择一种方法(相加或通道连接)来组合步骤3和4的输出以创建新的隐藏状态。

该算法将新创建的隐藏状态附加到现有隐藏状态集合作为后续块中的潜在输入。控制器 RNN重复对应于卷积单元中的
B
B
B 块的上述5个预测步骤
B
B
B 次。实验发现
B
=
5
B = 5
B=5 提供了良好的结果。最后,在卷积单元中生成的所有未使用的隐藏状态在深度上连接在一起以提供最终的单元输出。
NASNet 根据 CNN 文献中的流行情况收集了以下一系列操作:
- identity
- 3x3 average pooling
- 3x3 max pooling
- 5x5 max pooling
- 7x7 max pooling
- 1x3 then 3x1 convolution
- 1x7 then 7x1 convolution
- 1x1 convolution
- 3x3 convolution
- 3x3 depthwise-separable conv
- 5x5 depthwise-seperable conv
- 7x7 depthwise-separable conv
- 3x3 dilated convolution
为了使控制器 RNN 能够预测正常单元和缩减单元,NASNet 的控制器总共具有 2 × 5 B 2\times 5B 2×5B 个预测,其中前 5 B 5B 5B 预测正常单元,后 5B 5 B 5B 5B 预测缩减单元。
在 Drop-Path 中,单元内的每条路径在训练期间以一定的固定概率随机丢弃。 在改进版本 ScheduledDropPath 中,单元中的每个路径都会以线性增加的概率退出。
不同于使用 REINFORCE 规则 更新控制器的 NAS,NASNet 采用近端策略优化(Proximal Policy Optimization, PPO),学习率为0.00035,因为 PPO 训练更快,更稳定。
在 ImageNet 上训练模型时,NASNet 参考Inception-v4 :
- 使用值为0.1的标签平滑。
- 在网络的2/3处使用辅助分类器。 辅助分类器的损失加权0.4。
BlockQNN
BlockQNN 是商汤发表在 CVPR 2018的一篇文章,提出基于分布式训练的深度增强学习算法。文章把能重复组合的子结构称为 block。通过设计 block 结构,可以让网络结构的搜索空间大大减小。使用具有 epsilon-greedy 探索策略的 Q-learning 算法及 early-stop 策略在 CIFAR-100进行学习并迁移到 ImageNet 上。文章细节不是很清楚,如果层最大索引是23,则块内结构应该非常复杂才是。
BlockQNN 是 NASNet 的同期作品,区别是
- BlockQNN 没有搜索 reduce cell 而是直接使用 max pool。
- cell 内部没有定义 block 子结构。
- 仅使用传统卷积。
从性能表现而言, NAS ->BlockQNN ->NASNet 依次增强,而三者的搜索空间也存在这样的关系。说明人工加入先验是有用的。
BlockQNN 提出了一种称为网络结构代码(Network Structure Code,NSC)的新层表示,如表 Table 1 所示。然后用一组
5
5
5-D NSC 向量描述每个块。在 NSC 中,前三个数字代表层索引、操作类型和卷积核大小。最后两个是前层参数,它指的是结构代码中图层的前任层的位置。如果当前层只有一个输入,则将 Pred
2
2
2 设置为零。因此,所提出的NSC可以编码复杂性架构,如图 Figure 2 所示。


此外,块中没有后继的所有层都连接在一起以提供最终输出。
请注意,每个卷积操作,与ResNetV2 中的声明相同,是指具有三个组件的预激活卷积单元(Pre-activation Convolutional Cell, PCC),即 ReLU-CONV-BN。
这样使得搜索空间比三个组件单独搜索的小,因此通过 PCC,BlockQNN 可以获得更好的初始化搜索并通过快速训练生成最佳块结构。
每个块内没有下采样操作。 BlockQNN 直接通过汇集层执行下采样。如果通过合并操作将特征图的大小减半,则块的权重将加倍。
Q-learning 模型由代理、状态和一组动作组成。文中 s ∈ S s\in S s∈S 表示当前层的状态,该层由 NSC 定义,即 5 5 5-D 向量 {layer index, layer type, kernel size, pred 1 1 1, pred 2 2 2}。动作 a ∈ A a\in A a∈A 是下一个连续层的决定。
状态转换过程 ( s t , a ( s t ) ) → ( s t + 1 ) (s_t,a(s_t))\rightarrow (s_{t+1}) (st,a(st))→(st+1) 如图 Figure 4(a) 所示,其中 t t t 表示当前层。 图Figure 4(b) 中的块示例由图 Figure 4(a) 中的红色实线生成。

图 Figure 4(c) 为 BlockQNN 的学习过程:
- 代理首先对一组结构代码进行采样以构建块体系结构;
- 基于该体系结构,通过顺序堆叠这些块来构建整个网络;
- 然后在特定任务上训练生成的网络;
- 将验证准确率视为更新 Q 值的奖励;
- 代理选择另一组结构代码以获得更好的块结构。
令学习代理顺序选择块的NSC。可将块的结构看作是动作选择轨迹 τ a 1 : T \tau_{a_{1:T}} τa1:T,即一系列 NSC。BlockQNN 将层选择过程建模为马尔可夫决策过程,假设一个块中性能良好的层也应该在另一个块中表现良好[MetaQNN]。
为了找到最佳架构,要求代理在所有可能的轨迹上最大化其预期奖励,用
R
τ
R_{\tau}
Rτ 表示,
R
τ
=
E
P
(
τ
a
1
:
T
)
[
R
]
,
R_{\tau}= \mathbb{E}_{P(\tau_{a_{1:T}})}[\mathbb{R}],
Rτ=EP(τa1:T)[R],
其中
R
\mathbb{R}
R 是累积奖励。对于这个最大化问题,通常使用递归 Bellman 方程来优化。给定状态
s
t
∈
S
s_t\in S
st∈S 和后续动作
a
∈
A
(
s
t
)
a\in A(s_t)
a∈A(st),最大总预期奖励定义为
Q
∗
(
s
t
,
a
)
Q^*(s_t,a)
Q∗(st,a),这是状态—动作对的 Q 值。然后可以将递归 Bellman 方程写为
Q
∗
(
s
t
,
a
)
=
E
s
t
+
1
∣
s
t
,
a
[
E
r
∣
s
t
,
a
,
s
t
+
1
[
r
∣
s
t
,
a
,
s
t
+
1
]
+
γ
max
a
′
∈
A
(
s
t
+
1
)
)
Q
∗
(
s
t
+
1
,
a
′
)
]
.
Q^*(s_t,a)=\mathbb{E}_{s_{t+1}|s_t,a}[\mathbb{E}_{r|s_t,a,s_{t+1}}[r|s_t,a,s_{t+1}]\\ +\gamma \max_{a'\in A(s_{t+1}))}Q^*(s_{t+1},a')].
Q∗(st,a)=Est+1∣st,a[Er∣st,a,st+1[r∣st,a,st+1]+γa′∈A(st+1))maxQ∗(st+1,a′)].
解决上述未知量的经验假设是将其表述为迭代更新:
Q
(
s
T
,
a
)
=
0
Q
(
s
T
−
1
,
a
T
)
=
(
1
−
α
)
Q
(
s
T
−
1
,
a
T
)
+
α
r
T
Q
(
s
t
,
a
)
=
(
1
−
α
)
Q
(
s
t
,
a
)
+
α
[
r
t
+
γ
max
a
′
Q
(
s
t
+
1
,
a
′
)
]
,
t
∈
{
1
,
2
,
.
.
.
T
−
2
}
,
\begin{aligned} Q(s_T,a) =& 0\\ Q(s_{T-1},a_T) =& (1-\alpha)Q(s_{T-1},a_T) + \alpha r_T\\ Q(s_t,a)=&(1-\alpha)Q(s_t,a)+ \alpha [r_t+\gamma \max_{a'}Q(s_{t+1},a')], t \in\{1,2,...T-2\}, \end{aligned}
Q(sT,a)=Q(sT−1,aT)=Q(st,a)=0(1−α)Q(sT−1,aT)+αrT(1−α)Q(st,a)+α[rt+γa′maxQ(st+1,a′)],t∈{1,2,...T−2},
其中 α \alpha α 是确定新获取的信息如何覆盖旧信息的学习率, g a m m a \ gamma gamma 是衡量未来奖励重要性的折扣因子。
r
t
r_t
rt 表示为当前状态
s
t
s_{t}
st 观察到的中间奖励,
s
T
s_{T}
sT 表示最终状态,即终端层。
r
T
r_T
rT 是在训练集上训练
a
T
a_T
aT——最终状态的动作——至收敛后相应的网络的验证准确率 。 由于奖励
r
t
r_t
rt 无法在搜索任务中明确衡量,BlockQNN 使用奖励重塑(Reward Shaping)来加速训练。 重塑的形状中间奖励定义为:
r
t
=
r
T
T
.
r_t = \frac{r_T}{T}.
rt=TrT.
MetaQNN 在迭代过程中忽略这些奖励,即将它们设置为零,这可能会导致开始时收敛缓慢。这种时间信用分配问题使得 RL 耗时。在这种情况下, s T s_T sT 的 Q-value 远远高于训练早期的其他值,因此导致代理更喜欢在一开始就停止搜索,即倾向于构建具有较少层的小块。
众所周知,提前停止训练过程可能导致准确性差。如下图所示,黄线的早期停止准确率远低于橙线的最终准确率,这意味着一些好的块在早期停止训练时表现不如坏块。同时,可以注意到相应块的 FLOPs 和密度与最终精度呈负相关。

因此,作者将奖励函数重新定义为
r
e
w
a
r
d
=
ACC
EarlyStop
−
μ
log
(
FLOPs
)
−
ρ
log
(
Density
)
,
reward = \text{ACC}_{\text{EarlyStop}} - \mu\log(\text{FLOPs})- \rho\log(\text{Density}),
reward=ACCEarlyStop−μlog(FLOPs)−ρlog(Density),
其中 FLOPs 指的是块计算复杂度的估计,而 Density 是边块数除以块 DAG 中的点数。两个超参数,
μ
\mu
μ 和
ρ
\rho
ρ,用于平衡 FLOPs 和 Density 的权重。 通过重新定义的奖励功能,奖励与最终准确性更相关。
ENAS
ENAS 受迁移学习和多任务学习启发,通过强制所有子模型共享权重从而提升了 NAS 的效率,克服了 NAS 算力成本巨大且耗时的缺陷,GPU 运算时间缩短了1000倍以上。ENAS 在 CIFAR-10上实验,学习和挑选节点之间的连线关系。然而性能不及 NASNet。melodyguan/enas 是作者实现的 TensorFlow 程序。carpedm20/ENAS-pytorch 中卷积单元的搜索代码未完成,PyTorch 可参考 TDeVries/enas_pytorch。
ENAS 思想的核心是观察到 NAS最终迭代的所有图都可以视为一个较大图的子图。换句话说,我们可以使用单个有向无环图(DAG)来表示 NAS 的搜索空间。 ENAS 的 DAG 是 NAS 搜索空间中所有可能子模型的叠加,其中节点表示局部计算,边表示信息流。 每个节点的局部计算都有自己的参数,这些参数仅在特定计算被激活时使用。 因此,ENAS 的设计允许在搜索空间中的所有子模型(即架构)之间共享参数。
ENAS 架构之间共享权重的设计受到神经模型演化中权重继承概念的启发[Evolution, Peephole]。此外,ENAS 使用 DAG 表示计算受到随机计算图概念的启发,它将具有随机输出的节点引入到计算图中。 ENAS 利用网络中的这些随机决策来制定离散的架构决策,控制网络中的后续计算,训练决策者,即控制器,最后收集决策以获得架构。
与 ENAS 密切相关的是 SMASH,它设计了一个架构,然后使用 HyperNetwork 来生成它的权重。超网络的这种用法将 SMASH 的子架构的权重限制到低秩空间。这是因为超网络通过张量乘积为 SMASH 的子模型生成权重,对于任意矩阵 A \mathbf{A} A 和 B \mathbf{B} B,其受到低秩限制总是有不等式: rank ( A ⋅ B ) ≤ min { rank ( A ) , rank ( B ) } \text{rank}(\mathbf{A} \cdot \mathbf{B}) \leq \min{\{\text{rank}(\mathbf{A}), \text{rank}(\mathbf{B})\}} rank(A⋅B)≤min{rank(A),rank(B)}。由于这个限制, SMASH 将找到在其权重的受限低秩空间中表现良好的架构,而不是在正常训练设置中表现良好的架构,其中权重不再受限制。而 ENAS 允许其子模型的权重是任意的,有效地避免了这种限制。
ENAS 的控制器网络是一个带有 100 100 100 个隐藏单元的 LSTM。该 LSTM 以自回归方式通过 softmax 分类器进行采样决策:上一步骤中的决策作为输入嵌入到下一步骤中。 在第一步,控制器网络接收空嵌入作为输入。
ENAS 中有两组可学习的参数:
- 控制器 LSTM 的参数,由 θ \theta θ 表示;
- 子模型的共享参数,由 ω \omega ω 表示。
训练采用交替的方式进行。
训练子模型的共享参数
ω
\omega
ω。 在这一步中固定控制器的策略
π
(
m
;
θ
)
\pi(\mathrm{m}; \theta)
π(m;θ) 并在
ω
\omega
ω 上执行随机梯度下降(SGD)以最小化预期的损失函数
E
m
∼
π
[
L
(
m
;
ω
)
]
\mathbb{E}_{\mathrm{m} \sim \pi} \left[ \mathcal{L}(\mathrm{m}; \omega) \right]
Em∼π[L(m;ω)]。 这里,
L
(
m
;
ω
)
\mathcal{L}(\mathrm{m}; \omega)
L(m;ω) 是标准的交叉熵损失,根据训练数据的小批量计算,模型
π
(
m
;
θ
)
\pi(\mathrm{m}; \theta)
π(m;θ)。 使用蒙特卡洛估计来计算梯度
∇
ω
E
m
∼
π
(
m
;
θ
)
[
L
(
m
;
ω
)
]
≈
1
M
∑
i
=
1
M
∇
ω
L
(
m
i
,
ω
)
,
\begin{aligned} \nabla_\omega \mathbb{E}_{\mathrm{m} \sim \pi(\mathrm{m}; \theta)} \left[ \mathcal{L}(\mathrm{m}; \omega) \right] &\approx \frac{1}{M} \sum_{i=1}^{M} \nabla_\omega \mathcal{L}(\mathrm{m}_i, \omega), \end{aligned}
∇ωEm∼π(m;θ)[L(m;ω)]≈M1i=1∑M∇ωL(mi,ω),
其中 m i \mathrm{m}_i mi 是从 π ( m ; θ ) \pi(\mathrm{m}; \theta) π(m;θ) 中采样的,如上所述。公式提供梯度的无偏估计 ∇ ω E m ∼ π ( m ; θ ) [ L ( m ; ω ) ] \nabla_\omega \mathbb{E}_{\mathrm{m} \sim \pi(\mathrm{m}; \theta)} \left[ \mathcal{L}(\mathrm{m}; \omega) \right] ∇ωEm∼π(m;θ)[L(m;ω)]。但是,此估计值的方差高于标准 SGD 梯度,其中 m \mathrm{m} m 是固定的。然而——这也许是令人惊讶的 —— 我们发现 M = 1 M = 1 M=1 工作正常,也就是说我们可以使用任何单个模型 m \mathrm{m} m 的梯度来更新 ω \omega ω 从 π ( m ; θ ) \pi(\mathrm{m}; \theta) π(m;θ) 中抽样。
训练控制器参数 θ \theta θ。 在此步骤中,我们固定 ω \omega ω 并更新策略参数 θ \theta θ,旨在最大化预期奖励 E m ∼ π ( m ; θ ) [ R ( m , ω ) ] \mathbb{E}_{\mathrm{m} \sim \pi(\mathrm{m}; \theta)}\left[ \mathcal{R}(\mathrm{m}, \omega) \right] Em∼π(m;θ)[R(m,ω)]。使用 REINFORCE 规则 计算梯度,优化器采用 Adam 并借助移动平均基线来减少方差。
奖励 R ( m , ω ) \mathcal{R}(\mathrm{m}, \omega) R(m,ω) 是在验证集上而不是在训练集上计算的,以促使 ENAS 选择范化性好而不是过度拟合的模型。在我们的图像分类实验中,奖励函数是验证图像的小批量的准确性。
- 第一阶段训练 ω \omega ω 一个 epoch。对于CIFAR-10, ω \omega ω 所用训练图像 45 , 000 45,000 45,000 张,最小批量为 128 128 128 ,其中 ∇ ω \nabla_\omega ∇ω 使用标准的反向传播计算。
- 第二阶段训练控制器 LSTM 的参数 θ \theta θ,固定步数,实验中设置为 2000 2000 2000。
ENAS 在实验中搜索了网络的宏架构和微架构,从而与 NAS 和 NASNet 进行对比。
在宏结构搜索中,除跳跃连接外,控制器可用的 6 6 6 种操作是:
- 3 × 3 3 \times 3 3×3 convolution
- 5 × 5 5 \times 5 5×5 convolution
- 3 × 3 3 \times 3 3×3 average pooling
- 5 × 5 5 \times 5 5×5 average pooling
- 3 × 3 3 \times 3 3×3 max pooling
- 5 × 5 5 \times 5 5×5 max pooling
- 3 × 3 3 \times 3 3×3 depthwise-separable conv
- 5 × 5 5 \times 5 5×5 depthwise-seperable conv
在宏搜索空间中,我们通过将层间跳跃概率与 预定概率 ρ = 0.4 \rho = 0.4 ρ=0.4 之间 KL散度加入奖励来强制跳过连接中的稀疏性。
微架构搜索时设定类似于 NASNet,但操作种类减少到5个:
- identity
- 3 × 3 3 \times 3 3×3 depthwise-separable conv
- 5 × 5 5 \times 5 5×5 depthwise-seperable conv
- 3 × 3 3 \times 3 3×3 average pooling
- 3 × 3 3 \times 3 3×3 max pooling
同时,单元节点数 B = 7 B = 7 B=7,又比 NASNet 中的 B = 5 B = 5 B=5 多。
在节点 i i i ( 3 ≤ i ≤ B 3 \leq i \leq B 3≤i≤B),控制器可以从前 i − 1 i - 1 i−1 个节点中选择任意两个节点,并从 5 5 5 操作中选择任意两个操作。由于所有决策都是独立的,因此有 ( 5 × ( B − 2 ) ! ) 2 (5 \times (B-2)!)^2 (5×(B−2)!)2 种可能的单元。由于我们为卷积单元和缩减单元独立采样,因此搜索空间的最终大小为 ( 5 × ( B − 2 ) ! ) 4 (5 \times (B-2)!)^4 (5×(B−2)!)4。在我们的实验中, B = 7 B = 7 B=7,搜索空间可以覆盖 1.3 × 1 0 11 1.3 \times 10^{11} 1.3×1011 种网络。
文章实验发现 ENAS 找到的模型在某种意义上是搜索空间中的局部最小值。特别是,在 ENAS 从宏搜索空间中找到的模型中,如果用正常卷积替换所有可分离卷积,然后调整模型大小以使参数数保持不变,则测试误差增加 1.7 % 1.7\% 1.7%。同样,如果随机更改微搜索空间中找到的单元格中的多个连接,则测试错误会增加 2.1 % 2.1\% 2.1%。当 ENAS 搜索 RNN 单元以及 CNN 单元时,也会观察到这种行为。因此,作者认为通过 ENAS 学习的控制器 RNN 与 NAS 学习的控制器 RNN 一样好,并且 NAS 和 ENAS 之间的性能差距是由于没有像 NAS 一样从独立训练子模型造成的。
MnasNet
MnasNet 为移动设备设计卷积神经网络,该方法显式将模型延迟加入到目标函数中,以便搜索出在准确性和延迟之间实现良好折衷的模型。其通过在手机上执行模型来直接测量实际推理延迟。

给定模型 m m m,令 A C C ( m ) ACC(m) ACC(m) 表示其在目标任务上的准确性, L A T ( m ) LAT(m) LAT(m) 表示目标移动平台上的推理延迟, T T T 是目标延迟。一种常见的方法是将 T T T 视为硬约束并在此约束下最大化准确度:
maximize m A C C ( m ) subject to L A T ( m ) ≤ T \begin{aligned} & \underset{m}{\text{maximize }} & & ACC(m) \\ & \text{subject to} & & LAT(m) \le T \end{aligned} mmaximize subject toACC(m)LAT(m)≤T
然而,这种方法仅最大化单个度量并且不提供多个 Pareto 最优解。 非正式地,如果模型具有最高精度而不增加延迟,或者它具有最低延迟而不降低精度,则称为 Pareto 最优。考虑到执行架构搜索的计算成本,MnasNet 更感兴趣的是在单一架构搜索中找到多个 Pareto 最优解决方案。MnasNet 使用自定义加权乘积方法近似帕累托最优解,优化目标定义为:
maximize
m
A
C
C
(
m
)
×
[
L
A
T
(
m
)
T
]
w
\begin{aligned} & \underset{m}{\text{maximize }} & & {ACC(m)} \times \left[ \frac{ LAT(m)}{T} \right] ^ w \end{aligned}
mmaximize ACC(m)×[TLAT(m)]w
其中
w
w
w 是权重因子,定义如下:
w
=
{
α
,
if
L
A
T
(
m
)
≤
T
β
,
otherwise
\begin{aligned} w = \begin{cases} \alpha, & \text{if } LAT(m) \leq T\\ \beta, & \text{otherwise} \end{cases} \end{aligned}
w={α,β,if LAT(m)≤Totherwise
其中 α \alpha α 和 β \beta β 是特定于应用程序的常量。选择 α \alpha α 和 β \beta β 的经验规则是确保 Pareto 最优解决方案在不同的准确率 - 延迟权衡下具有相似的奖励。例如,作者凭经验观察到延迟加倍通常会带来5%的相对准确度增益。假设两种模型:
- (1)M1的延迟为 l l l,准确度为 a a a;
- (2)M2有延迟 2 l 2l 2l 和 5%更高的准确度 $ a \cdot (1 + 5%)$
他们应该有类似的奖励:
R
e
w
a
r
d
(
M
2
)
=
a
⋅
(
1
+
5
%
)
⋅
(
2
l
/
T
)
β
≈
R
e
w
a
r
d
(
M
1
)
=
a
⋅
(
l
/
T
)
β
Reward(M2) = a \cdot (1+ 5\%) \cdot (2l / T)^\beta \approx Reward(M1) = a \cdot (l / T)^\beta
Reward(M2)=a⋅(1+5%)⋅(2l/T)β≈Reward(M1)=a⋅(l/T)β
求解此问题得到
β
≈
−
0.07
\beta \approx -0.07
β≈−0.07。 因此,除非明确说明,否则 MnasNet 在实验中使用
α
=
β
=
−
0.07
\alpha=\beta=-0.07
α=β=−0.07。
Figure 3 显示了具有两个典型值
(
α
,
β
)
(\alpha, \beta)
(α,β) 的目标函数。在上半图(
α
=
0
,
β
=
−
1
\alpha=0, \beta=-1
α=0,β=−1)中,如果测量的延迟小于目标延迟
T
T
T,只需将精度用作目标值; 否则,函数会严厉惩罚目标值,以阻止模型违反延迟限制。底部图像(
α
=
β
=
−
0.07
\alpha=\beta=-0.07
α=β=−0.07)将目标延迟
T
T
T 视为软约束,并根据测量的延迟平滑调整目标值。

MnasNet 引入了一个新颖的分解的分层搜索空间,它将CNN 模型分解为独立的 block,然后分别搜索每个块的操作和连接,从而给予不同块以不同的层结构。如 Figure 4所示,MnasNet 将 CNN 模型划分为一系列预定义块,逐渐降低输入分辨率并增加滤波器大小。每个块具有相同层的列表,其操作和连接由每块子搜索空间确定。具体来说,块
i
i
i 的子搜索空间包含以下选项:
- 卷积操作 C o n v O p ConvOp ConvOp: regular conv (conv), depthwise conv (dconv), and mobile inverted bottleneck conv.
- 卷积核大小 K e r n e l S i z e KernelSize KernelSize: 3x3, 5x5.
- 压缩—激发比率 S E R a t i o SERatio SERatio: 0, 0.25.
- 跳跃连接 S k i p O p SkipOp SkipOp: pooling, identity residual, or no skip.
- 输出滤波器尺寸 F i F_i Fi.
- 每个 block 卷积层数量 N i N_i Ni.
C o n v O p ConvOp ConvOp、 K e r n e l S i z e KernelSize KernelSize、 S E R a t i o SERatio SERatio、 S k i p O p SkipOp SkipOp 和 F i F_i Fi 确定层结构,而 N i N_i Ni 确定层将重复多少次。例如,Figure 4中的块4的每一层都具有 inverted bottleneck 5x5 convolution 和恒等残差跳跃连接,并且同一层重复 N 4 N_4 N4次。MnasNet 参考 MobileNetV2 离散所有搜索选项:
- 对于每个块中的层,基于 MobileNetV2 搜索{0, +1, -1} ;
- 对于每层的滤波器数量,在{0.75, 1.0, 1.25}中搜索其相对于 MobileNetV2 的大小。

MnasNet 的分解分层搜索空间具有平衡层的多样性和总搜索空间大小的独特优势。假设将网络划分为 B B B 块,并且每个块都有一个大小为 S S S 的子搜索空间,每块平均 N N N层,那么总搜索空间大小将是 S B S^B SB,相应不分级的逐层搜索空间大小为 S B ∗ N S ^{B*N} SB∗N。典型案例是 S = 432 , B = 5 , N = 3 S=432, B=5, N=3 S=432,B=5,N=3,其中 MnasNet 的搜索空间大小约为 1 0 13 10^{13} 1013,,逐层搜索空间大小为 1 0 39 10^{39} 1039。
为了确保精度的提高源于搜索空间的改进,MnasNet 使用与 NASNet 相同的 RNN 控制器,即使它效率不高:每个架构搜索在 64个TPUv2设备上需要大约4.5天。 在训练期间,MnasNet 通过在 Pixel 1手机的单线程大 CPU 核心上运行来测量每个采样模型的实际延迟。 总的来说,控制器在架构搜索期间对大约8K 模型进行采样,但只将15个表现最佳的模型迁移到完整的 ImageNet,只有1个模型迁移到 COCO。

MnasNet 搜索到的网络包含 5x5卷积,这与之前的轻量模型有很大不同。
MobileNetV3
构建 MobileNetV3 主要分为3步:
- 使用 MnasNet 搜索整体网络结构;
- NetAdapt 逐层对网络精调;
- 根据经验人工对网络进行调整。
训练过程中测算移动设备上的模型延时可谓一大挑战。
NetAdapt 本质是一种自动化的网络剪枝(prune filter)算法,采用逐层渐进式修剪。剔除幅值过小的卷积核,逐步拔高延时要求。每剪一次,模型调整训练1万轮。
EfficientNet

Figure 5. FLOPS vs. ImageNet Accuracy
之前的算法搜索通用微架构或者整个网络,EfficientNet 提出一种新的思路:搜索一个小网络,然后按系数放大,衍生出满足不同延时要求的系列化模型。有几分 Xeon Scalable 的味道。
 图片取自论文。
图片取自论文。
-
EfficientNet 的第一步同 MobileNetV3 一样,使用 MnasNet 方法搜索出一个基础网络。EfficientNet 着眼于通用性,将 FLOPS 作为优化目标。
-
第2步复合缩放网络深度(Depth)、宽度(Width)和分辨率(resolution)。3个维度参数通过网格搜索方式确定,未说明训练细节。
MixNet
EfficientNet 问鼎 ImageNet 引发热议,结果不到两个月其续作就来了。MixNet 系统地研究了深度分离卷积中不同卷积核大小的影响,并观察到结合多个卷积核大小可以实现更好的精度和效率。据此,
- MixNet 提出了一种新的混合深度卷积 MDConv,在一个卷积操作中混合使用多个尺寸的卷积核。
- 将 MDConv 集成到 AutoML 搜索空间,基于 MnasNet 搜索出一系列新模型 MixNets。
其中 MixNet-L 在典型的移动设置(<600M FLOPS)下实现了ImageNet top-1 78.9%精度。模型参见 mnasnet/mixnet。
下图展示了普通深度卷积和 MDConv 的结构。MDConv 将通道分成多个组,并为每组通道应用不同尺寸的卷积核。

MixNet 的神经架构搜索基于 MnasNet ,并增加 MDConv 搜索选项。 具体来说,有五个 MDConv候选,相应分组数为
g
=
1
,
.
.
.
,
5
g=1,...,5
g=1,...,5:
- 3x3: 一组 3x3 卷积核( g = 1 g=1 g=1)的 MDConv。
- …
- 3x3, 5x5, 7x7, 9x9, 11x11: 包含五组卷积核( g = 5 g=5 g=5)的 MDConv,核大小为{3x3,5x5,7x7,9x9,11x11 }。每个组的通道数大致相同。
表 Table 2 展示了MixNets 在 ImageNet 上的性能。搜索的模型为 MixNet-S和 MixNet-M ,使用深度乘数1.3扩展 MixNet-M 可以得到 MixNet-L。

MixNet-S 和 MixNet-M 的网络架构如下图所示:
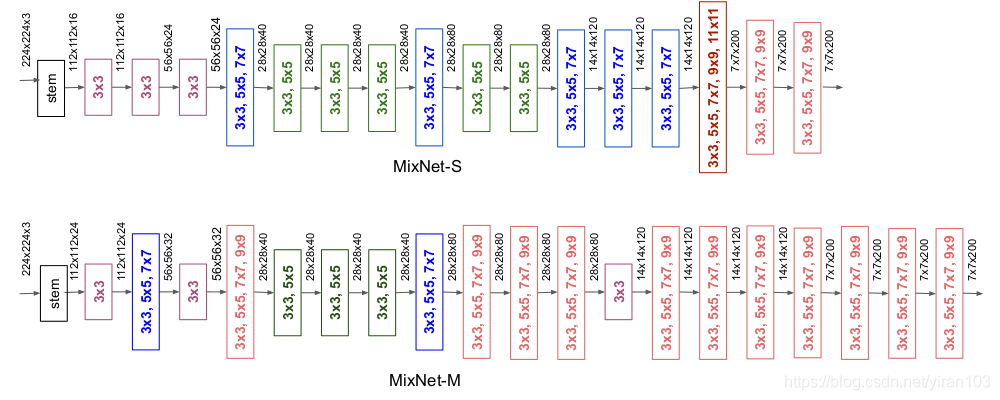
- 小卷积核在早期阶段更常见以节省计算成本,而后期大内核居多以获得更高的精度。
- 更大的 MixNet-M 倾向于使用更多的大内核和更多的层来获得更高的精度,同时消耗更多的参数和 FLOPS。
- MixNets 能够利用非常大的内核(如9x9和11x11)从输入图像中捕获高分辨率的模式,而不会损害模型的精度和效率。
参考资料:
- 如何评价google Searching for MobileNetV3?
- The Lightweight Face Recognition Challenge
- guan-yuan/awesome-AutoML-and-Lightweight-Models
- Literature on Neural Architecture Search
- D-X-Y/Awesome-NAS
- google-research/nasbench
- microsoft/nni
- 神经网络架构搜索(Neural Architecture Search)杂谈
- Xuanyi Dong
- ENAS的原理和代码解析
- 业界 | 谷歌提出移动端AutoML模型MnasNet:精度无损速度更快
- 多图演示高效的神经架构搜索
- Gumbel-Softmax Trick和Gumbel分布
- 旷视提出One-Shot模型搜索框架的新变体
- 另一种可微架构搜索:商汤提出在反传中学习架构参数的SNAS
- ICLR 2019|随机神经网络结构搜索 (SNAS)
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
- ENAS: 更有效地设计神经网络模型(AutoML)
- 万字解读商汤科技ICLR2019论文:随机神经网络结构搜索
- 同济和华为诺亚提出:渐进式可微网络结构搜索,显著提升可微式搜索的性能和稳定性,已开源
- 论文解读:Single-Path NAS
- 【ICLR 19】DARTS可微网络结构搜索
- CVPR 2018 | 商汤科技Oral论文详解:BlockQNN自动网络设计方法
- AutoML:NAS 之 Randomly Wired Neural Networks
- A Survey on Neural Architecture Search
- Neural architecture search
- AutoML (1) - Introduction
- Review: NASNet — Neural Architecture Search Network (Image Classification)
- ENAS的原理和代码解析
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
- 旷视首席科学家孙剑:深度学习变革视觉计算丨CCF-GAIR 2019
- pretrained-models.pytorch/pretrainedmodels/models/nasnet.py
- 自动选模型+调参:谷歌AutoML背后的技术解析
- NAS发展史:从放弃到入门
- MnasNet:终端轻量化模型新思路
- 论文笔记《Prioritized Experience Replay》
- 轻量型网络:MixNet解读
- CVPR 2019 神经网络架构搜索进展综述
- Fermi Arrives - NVIDIA GeForce GTX 480