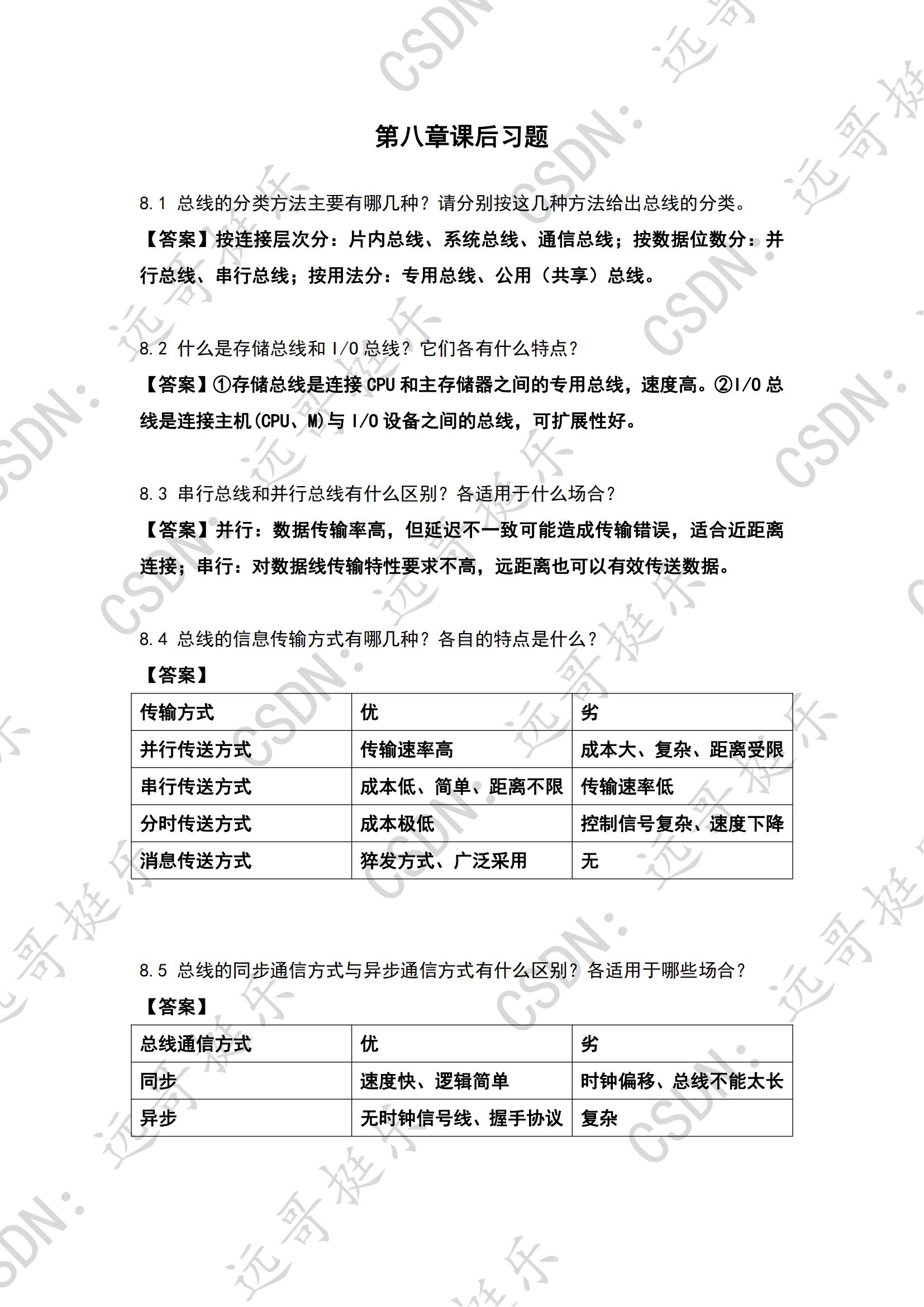
强化学习数学基础:基本概念
初识强化学习
强化学习是机器通过与环境交互来实现目标的一种计算方法。机器与环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。
一个网络世界的示例:
强化学习用智能体(agent)来表示决策的机器,它不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境。
智能体有3种关键要素:感知、决策和奖励
- 感知。agent在某种程度上感知环境的状态,从而指导自己所处的现状。
- 决策:agent根据当前的状态计算出达到目标需要采取的动作的过程叫做决策。
- 奖励:环境根据状态和agent采取的动作,产生一个标量信号作为奖励反馈。
另外,从数据层面看,强化学习中,数据是在智能体与环境交互的过程中得到的,如果agent不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。而对于有监督学习任务,则是建立在给定的数据分布中采样得到的训练数据集上,通过优化在训练数据集中设定的目标函数(如最小化预测误差)找到模型的最优参数。这里的训练数据集背后的数据分布是完全不变的。
具体而言,强化学习中有一个关于数据分布的概念,称为占用度量(occupancy measure)。归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程,采样得到一个具体的状态动作对(state-action pair)的概率分布。
占用度量的一个重要性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
基本概念
State(状态)和State Space(状态空间)
 状态与状态空间" />
状态与状态空间" />
Action(动作)与Action Space(动作空间)
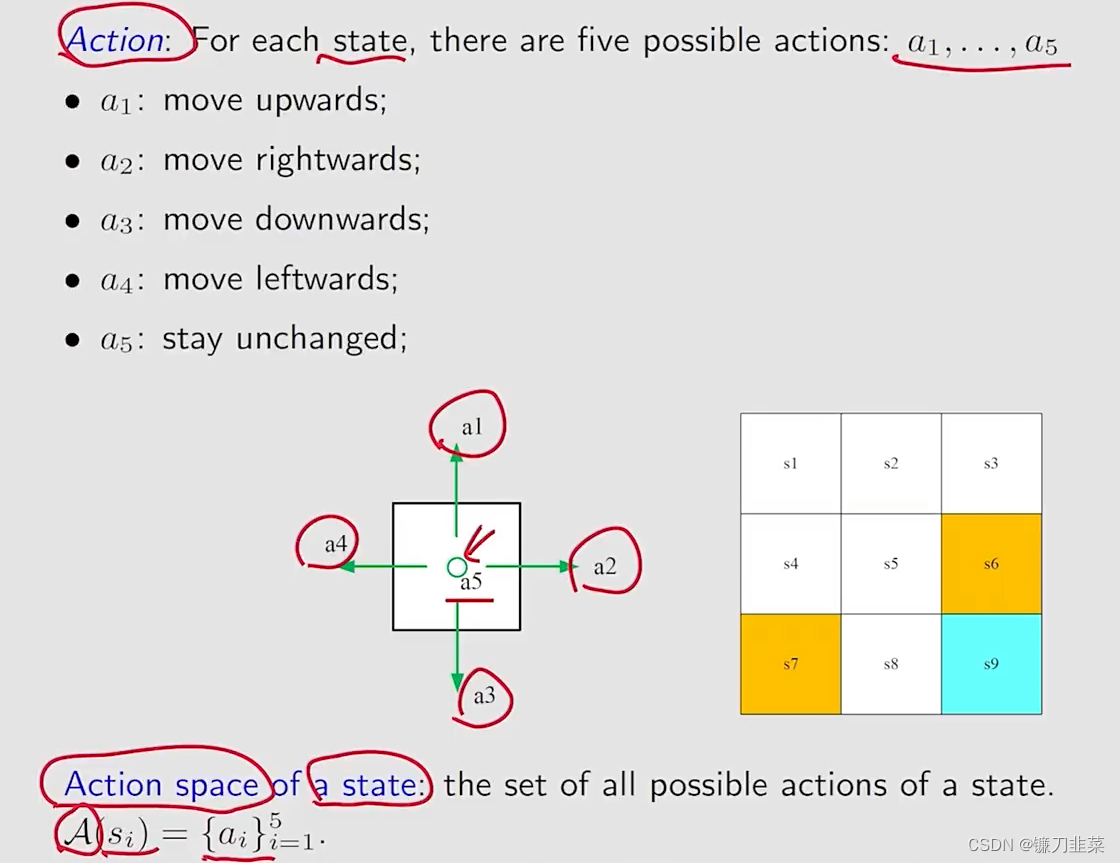
State transition(状态转移)

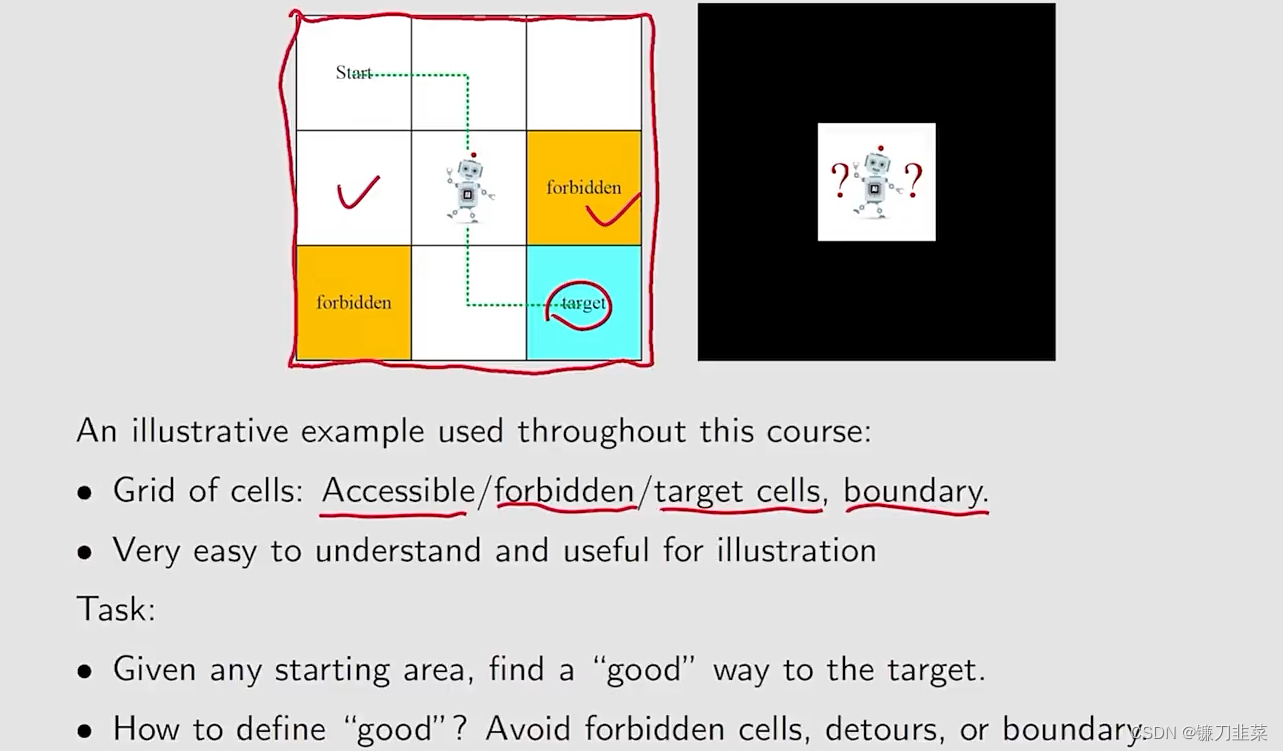
Forbidden area
在状态s5, 如果我们选择动作a2,也就是向右走,那么下一个状态是什么?
- 情况1:这个黄色区域(Forbidden area)是可达区域,但是会有惩罚;
- 情况2:这个forbidden area是不可达区域,也就是说这个区域是被封闭的;
Tabular representation(表格化表示)
用一个表格描述状态转移的情况。如下所示
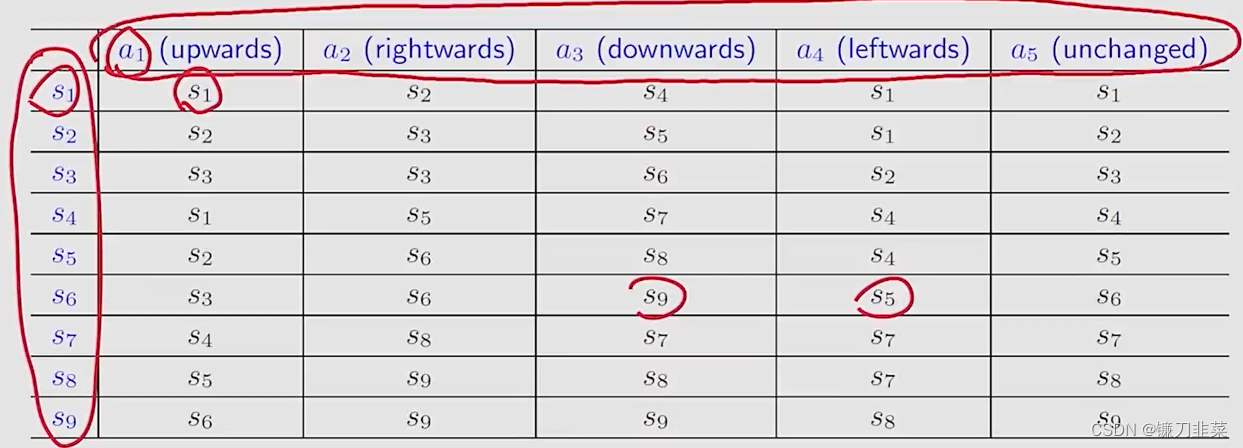
第一行表示动作,第一列表示当前位置,表格中的元素表示在当前位置选择动作执行后的状态。但是这种表格只能表示确定性的情况。
State transition probability(状态转移概率)
使用概率表述状态转移。
 状态转移概率" />
状态转移概率" />
这种方式尽管也是确定性的情况,但是也可以描述随机性(stochastic)的情况。
Policy(策略)
告诉agent在某个state应该采取什么action。
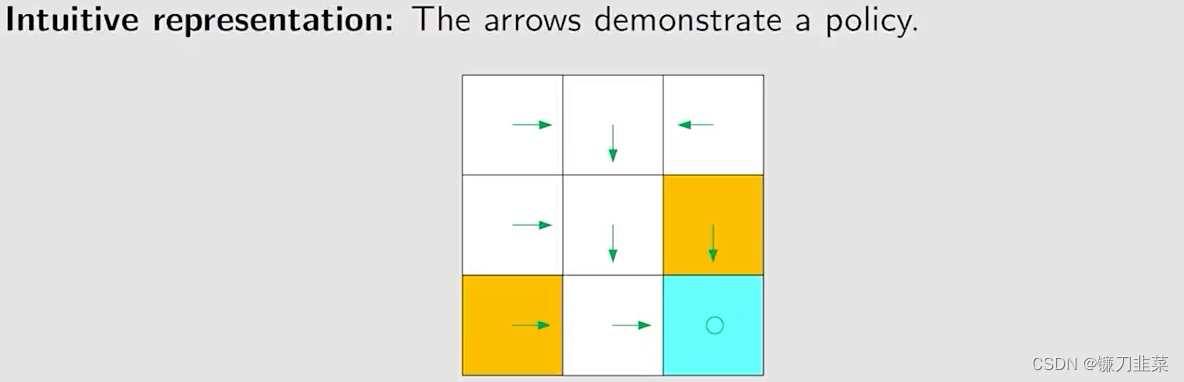
基于上面的策略,可以得到在不同起始点的路径:
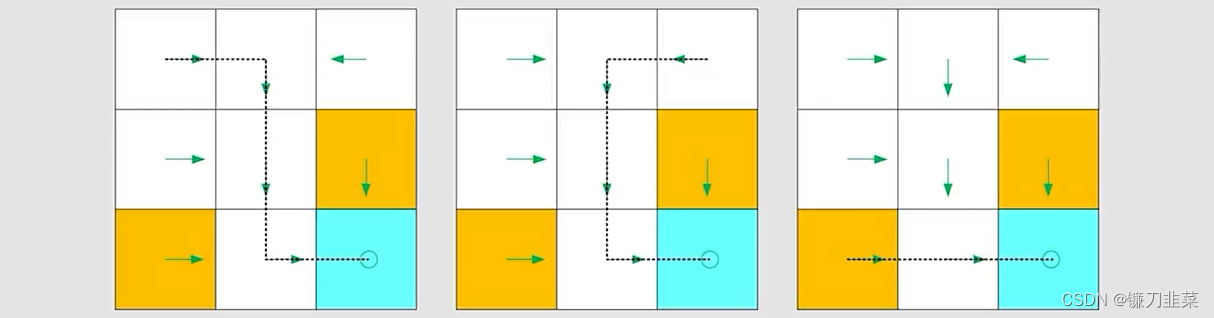
数学方式表示(Methematical representation):使用条件概率,如下,对于状态s1,有:
π
(
a
1
∣
s
1
)
=
0
\pi (a_1|s_1)=0
π(a1∣s1)=0
π
(
a
2
∣
s
1
)
=
1
\pi (a_2|s_1)=1
π(a2∣s1)=1
π
(
a
3
∣
s
1
)
=
0
\pi (a_3|s_1)=0
π(a3∣s1)=0
π
(
a
4
∣
s
1
)
=
0
\pi (a_4|s_1)=0
π(a4∣s1)=0
π
(
a
5
∣
s
1
)
=
0
\pi (a_5|s_1)=0
π(a5∣s1)=0
显然,这是一个确定性的策略。显然,还有一个随机性的策略,如下:
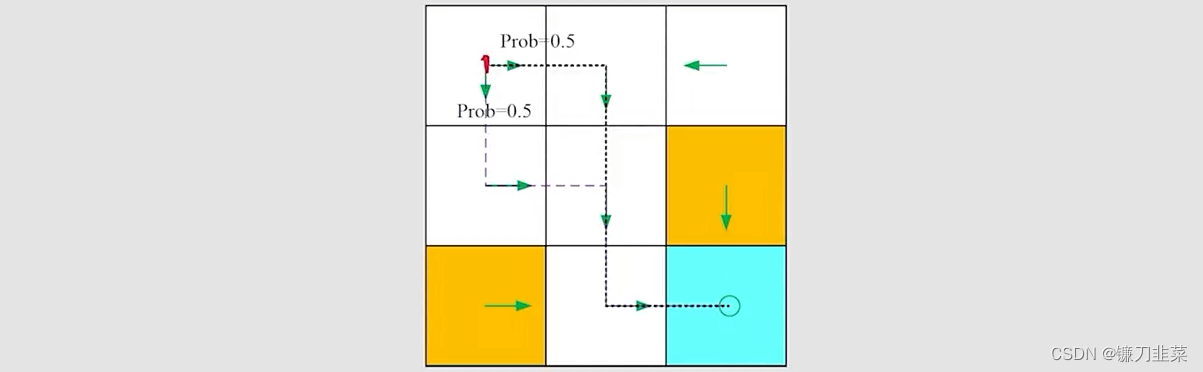
在这种策略下,对于s1,有:
π
(
a
1
∣
s
1
)
=
0
\pi (a_1|s_1)=0
π(a1∣s1)=0
π
(
a
2
∣
s
1
)
=
0.5
\pi (a_2|s_1)=0.5
π(a2∣s1)=0.5
π
(
a
3
∣
s
1
)
=
0.5
\pi (a_3|s_1)=0.5
π(a3∣s1)=0.5
π
(
a
4
∣
s
1
)
=
0
\pi (a_4|s_1)=0
π(a4∣s1)=0
π
(
a
5
∣
s
1
)
=
0
\pi (a_5|s_1)=0
π(a5∣s1)=0
同理,使用表格的形式描述该策略的状态,如下所示:
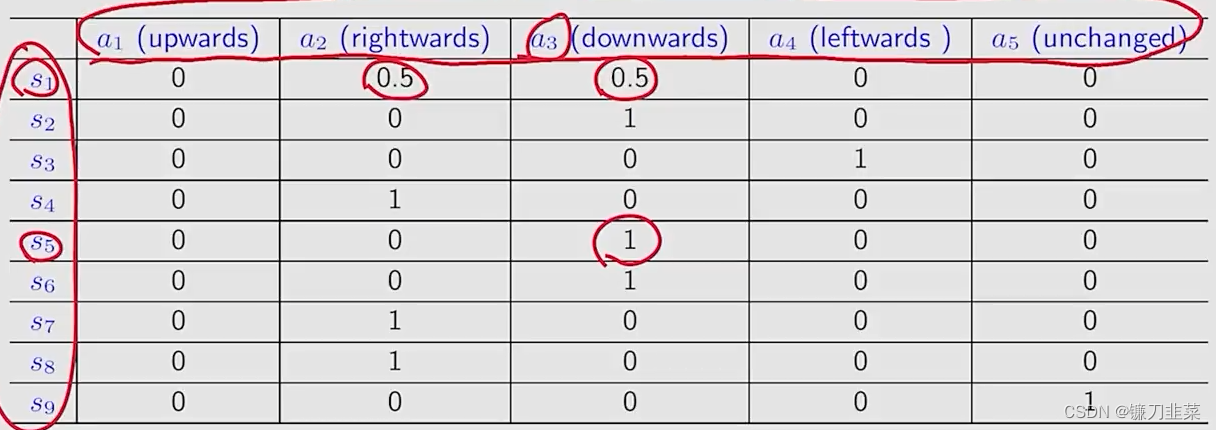
这种形式既可以描述确定性情况,也可以描述随机性情况。
Reward(奖励)
Reward是强化学习(RL)中的一个最独特的概念。是agent采取一个action后得到的一个实数(real number)。环境根据状态和智能体采取的动作,产生一个标量信号作为奖励反馈。这个标量信号衡量智能体这一轮动作的好坏。

在上面的网格案例中,奖励可以设计为:
 奖励设计" />
奖励设计" />
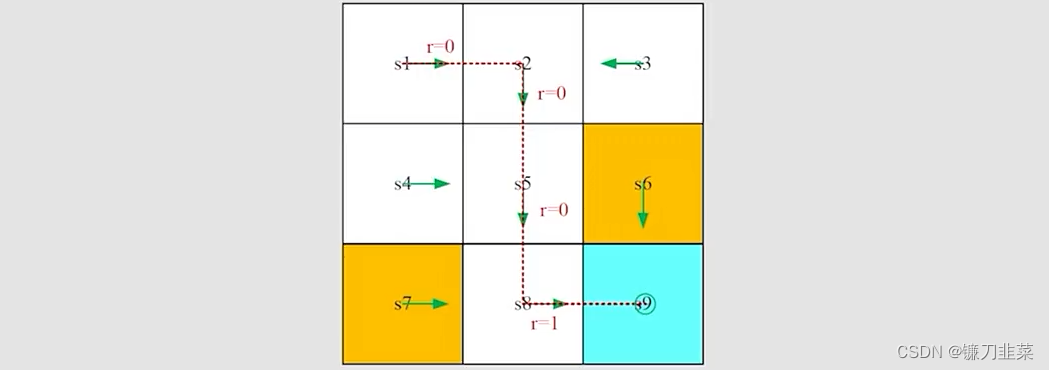
Reward可以被解释为一种人机交互(human-machine interface),基于此可以用于指导agent做出我们期望的行为。对于上面的网格示例,基于上面设计的奖励机制,agent将会避免逃出边界,并且不会进入到forbidden cells中。同样地,用表格形式表示基于奖励的状态转移:
 奖励的状态转移" />
奖励的状态转移" />
数学语言描述:条件概率
- 直观描述:在状态s1,如果我们选择动作a1,奖励是-1。
- 数学表示: p ( r = − 1 ∣ s 1 , a 1 ) = 1 p(r=-1|s_1, a_1)=1 p(r=−1∣s1,a1)=1且 p ( r ≠ − 1 ∣ s 1 , a 1 ) = 0 p(r≠-1|s_1, a_1)=0 p(r=−1∣s1,a1)=0
注意:
- 这里是一个确定性的例子,奖励转移可以是随机性的;
- 例如,如果你努力学习,你将会得到奖励,但是不确定性的程度是未知的?
- reward依赖于state和action,但是不依赖下一个state(例如,可以考虑s1,a1和s2,a5)
Trajectory and return
A trajectory(轨迹) is a state-action-reward chain,如下图所示:
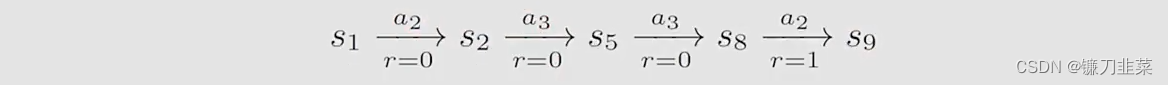
The return of this trajectory is the sum of all the rewards collected along the trajectory:
r
e
t
u
r
n
=
0
+
0
+
0
+
1
=
1
return = 0+0+0+1=1
return=0+0+0+1=1
另一种不同的策略得出一个不同的轨迹(trajectory):
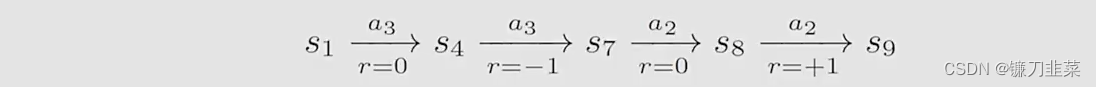
该路径的返回(return)是:
r
e
t
u
r
n
=
0
−
1
+
0
+
1
=
0
return=0-1+0+1=0
return=0−1+0+1=0
上面两种策略哪一个比较好?
- 直观上,第一种比较好,因为它避免了forbidden区域;
- 数学上,第一种比较好,因为它得到了一个较大的return;
- Return可以用来评估Policy是否好或者不好。
Discounted return
一种轨迹如下:
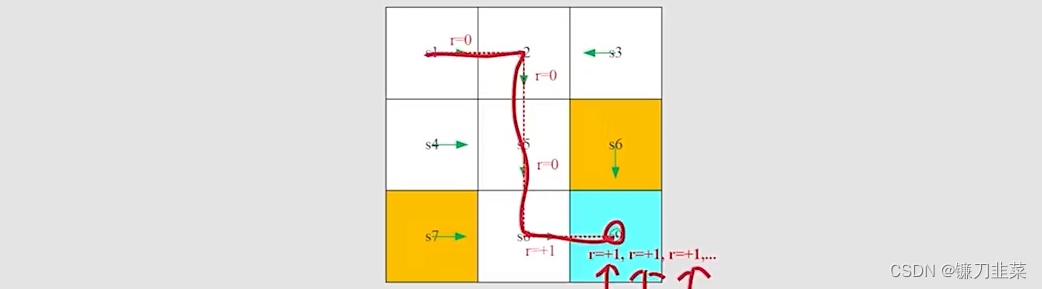
上面这种轨迹的定义如下:
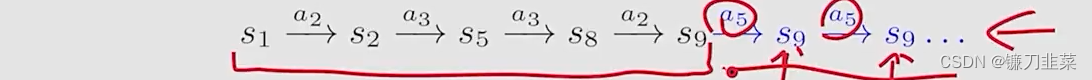
这时候,return就是:
r
e
t
u
r
n
=
0
+
0
+
0
+
1
+
1
+
1
+
.
.
.
=
∞
return=0+0+0+1+1+1+...=∞
return=0+0+0+1+1+1+...=∞。这种路径应当避免,因为他的return是发散的(diverges)。
那么如何解决这个问题?可以引入一个discount rate(折扣率)
γ
∈
[
0
,
1
)
\gamma\in [0,1)
γ∈[0,1)
Discounted return:
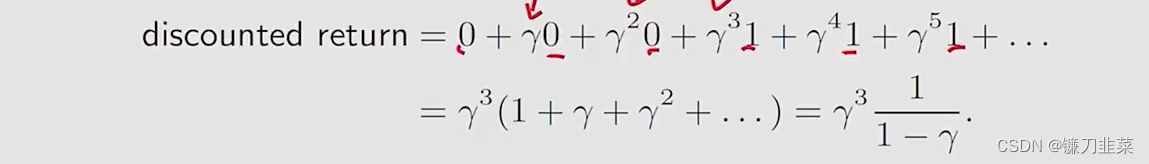
这个折扣率(discount rate)有两种作用:1)将sum变为有限的(finite);2)平衡近期和远期reward:
- 如果γ接近0,discounted return的值更加注重近期的reward
- 如果γ接近1,discounted return的值更加注重远期reward
Episode
当agent基于一个policy和环境进行交互的时候,它容易停留在某些terminal states。该过程的轨迹trajectory称为episode(或者一个trial)。例如下面路径:
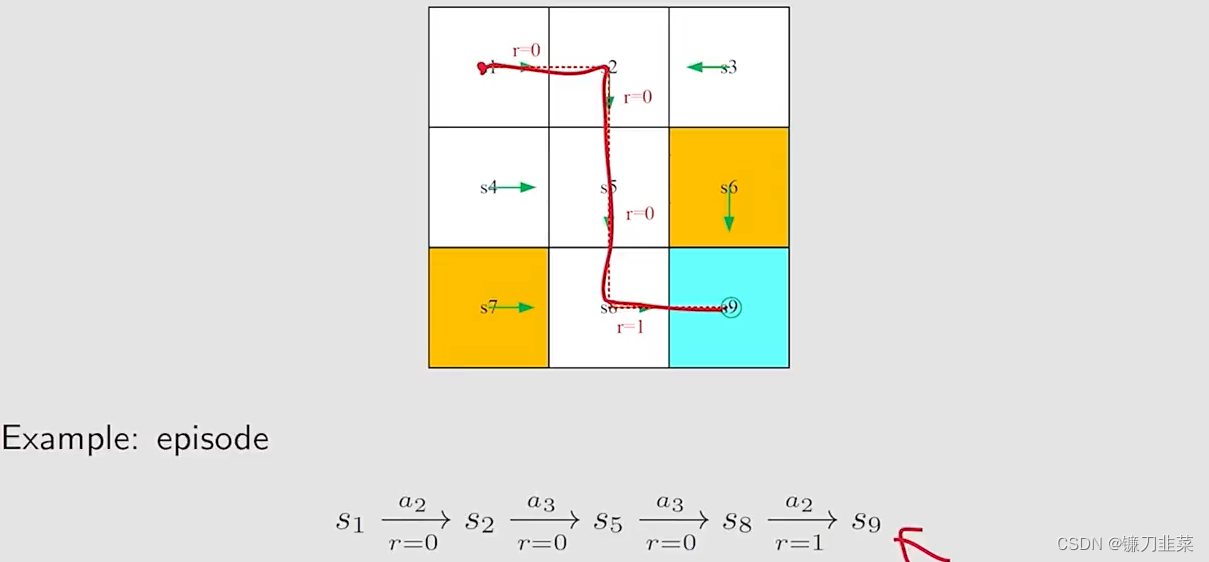
一个episode通常假设是一个有限的trajectory。具有episode的任务(Tasks)被称为episode tasks。
有些任务没有terminal states,意味着和环境的相互作用将不会停止。这样的任务称为continuing tasks。
在之前的网格案例中,当达到target之后是否应当停止?事实上,我们可以将episode和continuing tasks置于一个统一的数学框架下,通过将episode tasks转换为continuing tasks。
- 操作1:将target state视为一个特殊的absorbing state(吸收态)。一旦agent到达一个absorbing state,它将不会离开。后续的reward r = 0 r=0 r=0。
- 操作2:将target state视为一个具有一种policy的normal state(正常态)。agent仍然可以离开target state,并且当再次进入target state时,收益r=+1。
这里我们使用的是option 2,它相对来说,更具有一般化,对目标不区别对待,即把目标当作一个normal state。
Markov decision process (MDP)
MDP的关键要素
-
Sets(集合)
-
Probability distribution(概率分布):
-
Policy(策略):在状态s,采取动作a的概率是 π ( a ∣ s ) \pi(a|s) π(a∣s)
-
Markov property:memoryless property(和历史无关)
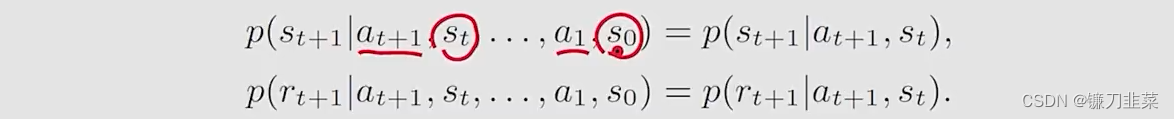
上面介绍的网格示例可以抽象为一个一般化的模型,Markov process,如下:
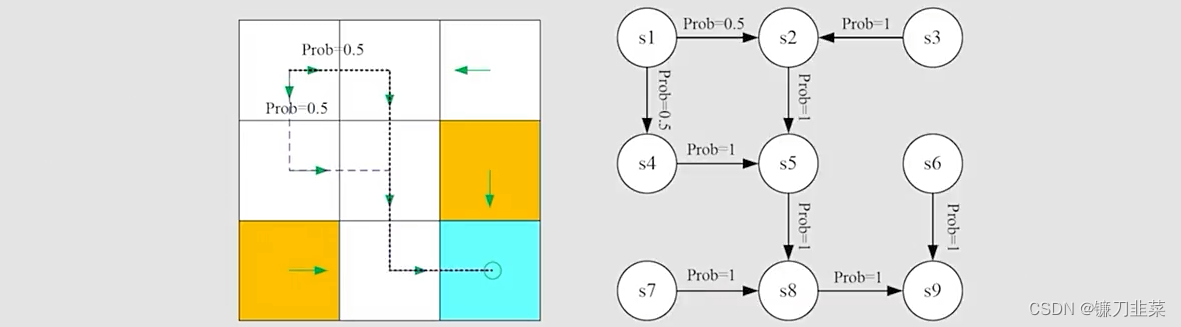
圆圈表示状态,有箭头的线表示状态转移。Markov decision process becomes Markov process once the policy is given!
总结
强化学习的关键概念如下:
- State
- Action
- State transition, state transition probability p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)
- Reward, reward probability p(r|s, a)
- Trajectory, episode, return, discounted return
- Markov decision process
补充
强化学习本质的思维方式:
(1)强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。因此,强化学习的一大难点在于,agent看到的数据分布是随着agent的学习而不断发生改变的。
(2)由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
有监督学习和强化学习的相似点和不同点:
(1)有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望。
(2)二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变。
总之,有监督学习是寻找一个最优的模型,尽可能拟合给定的数据分布;强化学习是寻找一个agent策略,使其能够最大化最有数据分布下一个给定奖励函数的期望。



![[神经网络]基干网络之ResNet、MobileNet](https://img-blog.csdnimg.cn/347b980114d64392a421579033d63c60.png)