提出nature-DQN算法的论文,主要改进:
- 使用bata-buffer的方式随机储存状态回放,消除数据的相关性,平滑数据的分布。
- 使用定期(T1)更新Q的方式,使减少与当前目标的相关性,也就是所谓的target-Q网络。值得注意的是,目前流行的方式是软更新(soft update),即定期(T2<T1)用一个Q网络部分更新另一个Q网络,类似于给Q网络加上了惯性属性,更新强度可调。
数据可视化:
t-SNE算法,用于在二维或三维的低维空间中表示高维数据集,从而使其可视化,对DQN得到的隐层输出进行降维,观察各种输入状态的相关性,很有用。
在论文中,人类和算法的操作,在镶嵌进2d空间后,有很强的的相关性,表明两者决策方法类似。

橙色人类,蓝色AI
数据预处理方法:
首先,要对单个帧进行编码,我们取编码帧和前一帧上每个像素颜色值的最大值。(没看懂),去除画面中的闪烁画面,因为没有信息。提取图像的明度。(但是具体怎么用呢?)
关于动作输出:
设置最快动作频率,防止做出超过正常玩家的作弊操作。atari是10hz操作一下。
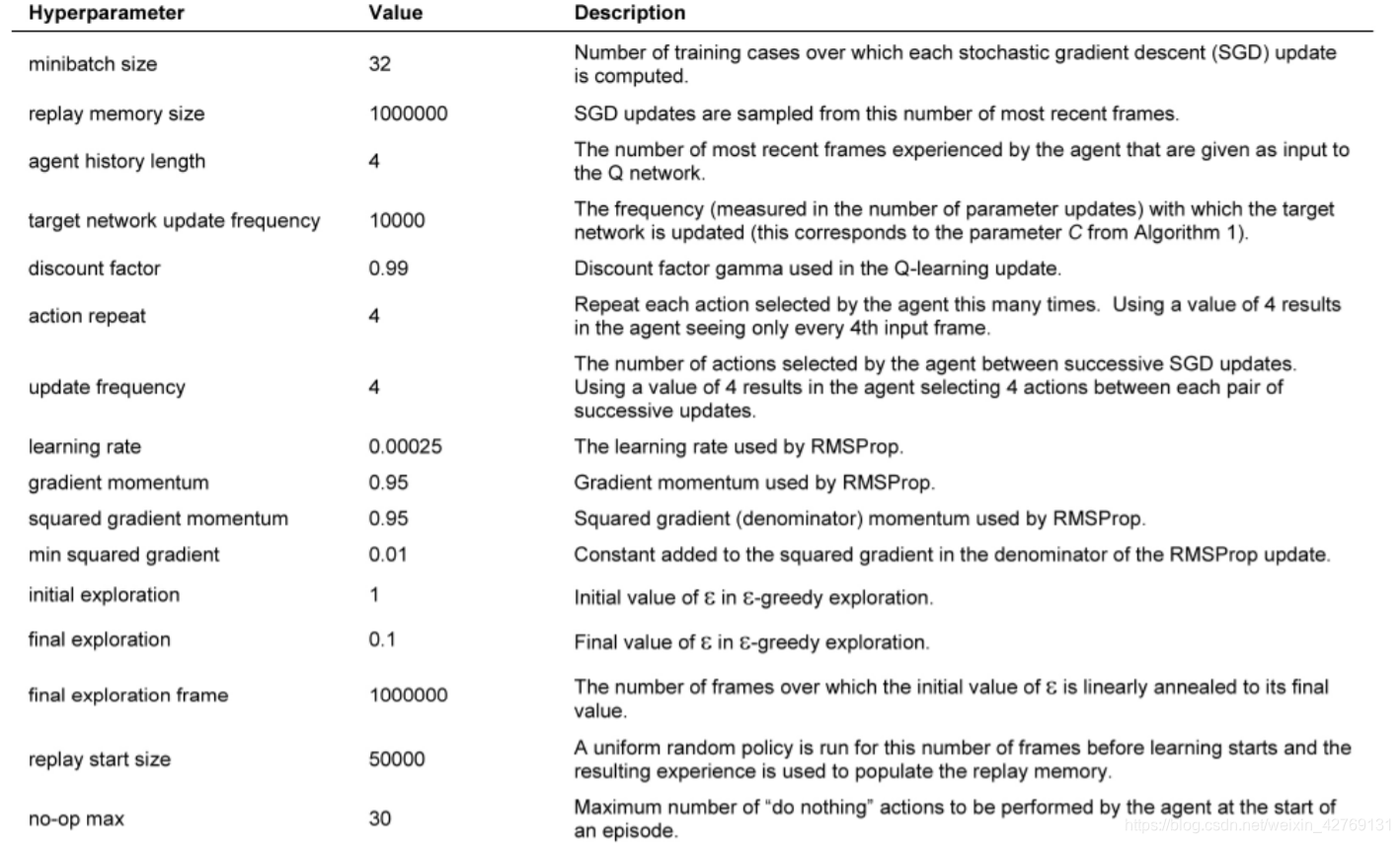
nature-DQN的超参数:
代码实现:
python">import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
import matplotlib.pyplot as plt
import copy
# hyper-parameters
BATCH_SIZE = 128
LR = 0.01
GAMMA = 0.90
EPISILO = 0.9
MEMORY_CAPACITY = 2000
Q_NETWORK_ITERATION = 100
env = gym.make("CartPole-v0")
env = env.unwrapped
NUM_ACTIONS = env.action_space.n
NUM_STATES = env.observation_space.shape[0]
ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample.shape
class Net(nn.Module):
"""docstring for Net"""
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(NUM_STATES, 50)
self.fc1.weight.data.normal_(0,0.1)
self.fc2 = nn.Linear(50,30)
self.fc2.weight.data.normal_(0,0.1)
self.out = nn.Linear(30,NUM_ACTIONS)
self.out.weight.data.normal_(0,0.1)
def forward(self,x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
action_prob = self.out(x)
return action_prob
class DQN():
"""docstring for DQN"""
def __init__(self):
super(DQN, self).__init__()
self.eval_net, self.target_net = Net().cuda(), Net().cuda()
self.learn_step_counter = 0
self.memory_counter = 0
self.memory = np.zeros((MEMORY_CAPACITY, NUM_STATES * 2 + 2))
# why the NUM_STATE*2 +2
# When we store the memory, we put the state, action, reward and next_state in the memory
# here reward and action is a number, state is a ndarray
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self, state):
state = torch.unsqueeze(torch.FloatTensor(state), 0).cuda() # get a 1D array
if np.random.randn() <= EPISILO:# greedy policy
action_value = self.eval_net.forward(state)
action = torch.max(action_value, 1)[1].cpu().data.numpy()
action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
else: # random policy
action = np.random.randint(0,NUM_ACTIONS)
action = action if ENV_A_SHAPE ==0 else action.reshape(ENV_A_SHAPE)
return action
def store_transition(self, state, action, reward, next_state):
transition = np.hstack((state, [action, reward], next_state))
index = self.memory_counter % MEMORY_CAPACITY
self.memory[index, :] = transition
self.memory_counter += 1
def learn(self):
#update the parameters
if self.learn_step_counter % Q_NETWORK_ITERATION ==0:
self.target_net.load_state_dict(self.eval_net.state_dict())
# 注意这里不是软更新,可以进行改进
self.learn_step_counter+=1
#sample batch from memory
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
batch_memory = self.memory[sample_index, :]
batch_state = torch.FloatTensor(batch_memory[:, :NUM_STATES]).cuda()
batch_action = torch.LongTensor(batch_memory[:, NUM_STATES:NUM_STATES+1].astype(int)).cuda()
batch_reward = torch.FloatTensor(batch_memory[:, NUM_STATES+1:NUM_STATES+2]).cuda()
batch_next_state = torch.FloatTensor(batch_memory[:,-NUM_STATES:]).cuda()
#q_eval
q_eval = self.eval_net(batch_state).gather(1, batch_action)
q_next = self.target_net(batch_next_state).detach()
q_target = batch_reward + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1)
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def reward_func(env, x, x_dot, theta, theta_dot):
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.5
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
reward = r1 + r2
return reward
def main():
dqn = DQN()
episodes = 400
print("Collecting Experience....")
reward_list = []
plt.ion()
fig, ax = plt.subplots()
for i in range(episodes):
state = env.reset()
ep_reward = 0
while True:
env.render()
action = dqn.choose_action(state)
next_state, _ , done, info = env.step(action)
x, x_dot, theta, theta_dot = next_state
reward = reward_func(env, x, x_dot, theta, theta_dot)
dqn.store_transition(state, action, reward, next_state)
ep_reward += reward
if dqn.memory_counter >= MEMORY_CAPACITY:
dqn.learn()
if done:
print("episode: {} , the episode reward is {}".format(i, round(ep_reward, 3)))
if done:
break
state = next_state
r = copy.copy(reward)
reward_list.append(r)
ax.set_xlim(0,300)
#ax.cla()
ax.plot(reward_list, 'g-', label='total_loss')
plt.pause(0.001)
if __name__ == '__main__':
main()

