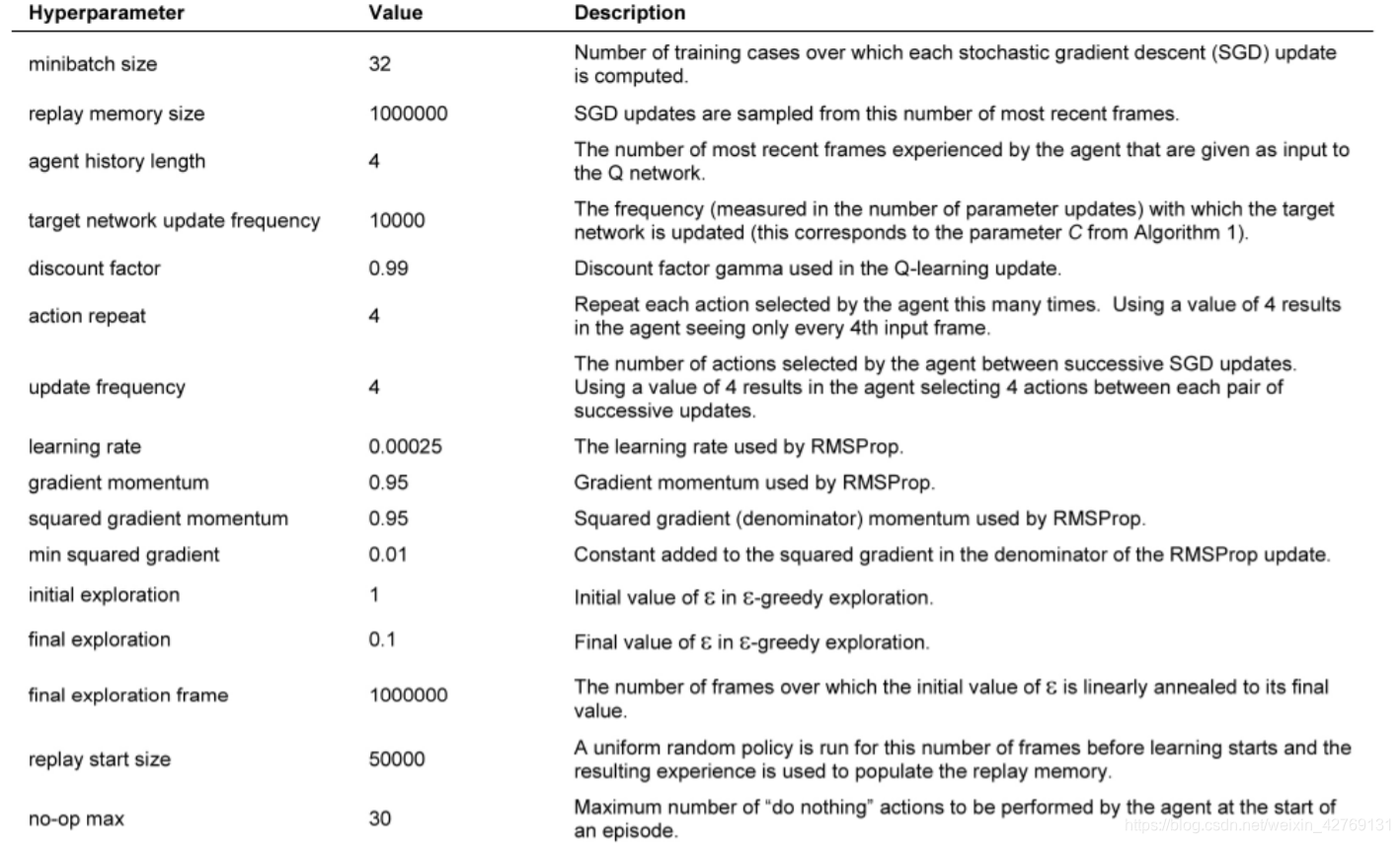
DQN系列算法的开山之作,这里的dqn通常称为NIPS-DQN,后来还有nature-DQN,更加好用。
论文的一些理解
Q-Learning的伪代码:

NIPS-DQN的伪代码:

有以下几个关键点:
一是图像的处理:
-
将图像压缩成灰度图
-
将图像降低分辨率
-
对图像进行裁剪,只保留中间有动作的部分,去不无用的边缘
-
对视频进行关键帧采样,不用每帧都处理
-
用多个关键帧组成输入,表述完整的动态过程。比如每次输入使用4个关键帧
-
所有奖励都剪裁成1,-1,0.这点不一定是好的
二是回放机制:
这个机制实际上是关键,因为回放机制打破了训练数据的强相关性,使训练偏差更小。
SGD的应用需要样本不相关,replay buffer能保证输入足够独立。(adam呢?)
- 保证输入网络的数据,相关性很低,保证样本相互独立。
- 一般用100w或10w长度
- 使训练数据更加平稳。
- 多次重采样,保证数据的利用率。
三是如何观察agent是否在训练
- 看loss
- 看看每个episode中,reward的大小
- 没有state的q value,一般应该越来越大,默认是好的动作
代码:
import torch
import torch.nn as nn
from collections import deque
import numpy as np
import gym
import random
from net import AtariNet
from util import preprocess
BATCH_SIZE = 32
LR = 0.001
START_EPSILON = 1.0
FINAL_EPSILON = 0.1
EPSILON = START_EPSILON
EXPLORE = 1000000
GAMMA = 0.99
TOTAL_EPISODES = 10000000
MEMORY_SIZE = 1000000
MEMORY_THRESHOLD = 100000
TEST_FREQUENCY = 1000
env = gym.make('Pong-v0')
env = env.unwrapped
ACTIONS_SIZE = env.action_space.n
class Agent(object):
def __init__(self):
self.network = AtariNet(ACTIONS_SIZE)
self.memory = deque()
self.optimizer = torch.optim.Adam(self.network.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def action(self, state, israndom):
if israndom and random.random() < EPSILON:
return np.random.randint(0, ACTIONS_SIZE)
state = torch.unsqueeze(torch.FloatTensor(state), 0)
actions_value = self.network.forward(state)
return torch.max(actions_value, 1)[1].data.numpy()[0]
def learn(self, state, action, reward, next_state, done):
if done:
self.memory.append((state, action, reward, next_state, 0))
else:
self.memory.append((state, action, reward, next_state, 1))
if len(self.memory) > MEMORY_SIZE:
self.memory.popleft()
if len(self.memory) < MEMORY_THRESHOLD:
return
batch = random.sample(self.memory, BATCH_SIZE)
state = torch.FloatTensor([x[0] for x in batch])
action = torch.LongTensor([[x[1]] for x in batch])
reward = torch.FloatTensor([[x[2]] for x in batch])
next_state = torch.FloatTensor([x[3] for x in batch])
done = torch.FloatTensor([[x[4]] for x in batch])
eval_q = self.network.forward(state).gather(1, action)
next_q = self.network(next_state).detach()
target_q = reward + GAMMA * next_q.max(1)[0].view(BATCH_SIZE, 1) * done
loss = self.loss_func(eval_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
agent = Agent()
for i_episode in range(TOTAL_EPISODES):
state = env.reset()
state = preprocess(state)
while True:
env.render()
action = agent.action(state, True)
next_state, reward, done, info = env.step(action)
next_state = preprocess(next_state)
agent.learn(state, action, reward, next_state, done)
state = next_state
if done:
break
if EPSILON > FINAL_EPSILON:
EPSILON -= (START_EPSILON - FINAL_EPSILON) / EXPLORE
# TEST
if i_episode % TEST_FREQUENCY == 0:
state = env.reset()
state = preprocess(state)
total_reward = 0
while True:
# env.render()
action = agent.action(state, israndom=False)
next_state, reward, done, info = env.step(action)
next_state = preprocess(next_state)
total_reward += reward
state = next_state
if done:
break
print('episode: {} , total_reward: {}'.format(i_episode, round(total_reward, 3)))
env.close()