在强化学习领域,传统的要素为环境,观察表述,奖励,动作,这里的奖励完全由环境给出,论文提出一种内部驱动的奖励系统,如下图所示:

本文将奖励分为内部驱动的奖励和外部驱动的奖励,二者相互作用指导智能体的行动。
这在生物学上有一定的依据,生物在进化中学习到了很多的品质,比如喜欢探索,好奇心,这些品质即使没有外部奖励,一些生物的个体依然会保持,可见其合理性。
论文使用两个实验证明,使用自身相关的奖励,比单纯使用外部的适应度奖励更好。
论文使用的算法为Q-learning。
一是饥饿-口渴实验:
条件是这样的,一个智能体,在一个6*6的网格中寻找食物和水,二者随机分布在网格当中,agent到达食物的点,并且执行吃的动作,就可以增加适应去,下一时刻立即又饿了,但是这个智能体会口渴,在口渴状态下无法吃食物,喝完水之后有0.1的概率随机的边的口渴,水和食物都无限供应。吃食物为外部的奖励,喝水不会增加适应度,为内部的奖励。

最终比较好的智能体使用的策略如下:agent在口渴且饥饿的状态下,会朝水的点走,在不口渴且饥饿的状态下,会朝食物走。

最终得到,在考虑口渴的奖励函数,比不考虑奖励的agent适应能力更强,虽然考虑口渴的因素不会直接增强适应度。
二是盒子实验:
在6*6的格子空间里,有2个随机位置的箱子,agent只有到达箱子位置,打开箱子,吃掉里边的食物,增加使用度。一个关闭的箱子打开后一定有食物,箱子打开后,有0.1的概率再关闭,关闭之后再打开再次有食物。
湿度度为agent迟到食物的数量,本文使用的奖励:吃掉食物的数量和agent是否把箱子打开。
打开箱子的动作,不会增加实用度,指agent好奇心的体现。
最终表现显然,有好奇心的agent表现更好。

如果在前5000步,任何盒子都没有食物,5000步之后才给食物,喜欢探索的agent同样很有优势,因为提前把盒子打开了:

可以看到,使用内部的参数做奖励,表现很好。
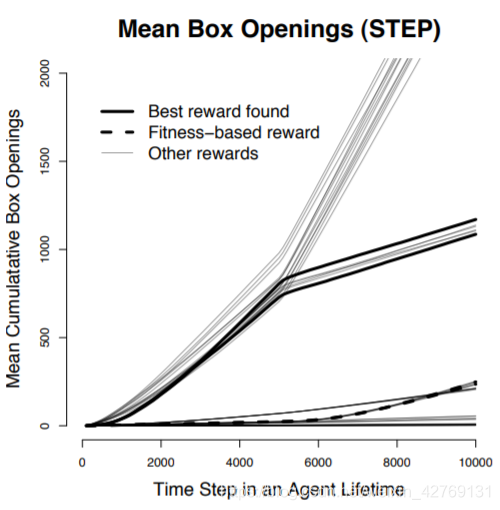
这幅图是平均开箱数的图,使用内部奖励的agent更喜欢开箱。
最终的得到结论:
agent自身的内部奖励会影响agent整体的适应度。
疑惑:
感觉实验有点牵强,因为内部的动作和外部的奖励有一个固定的状态转换概率,其实相当于间接的增加外部奖励的比率,感觉有点问题。