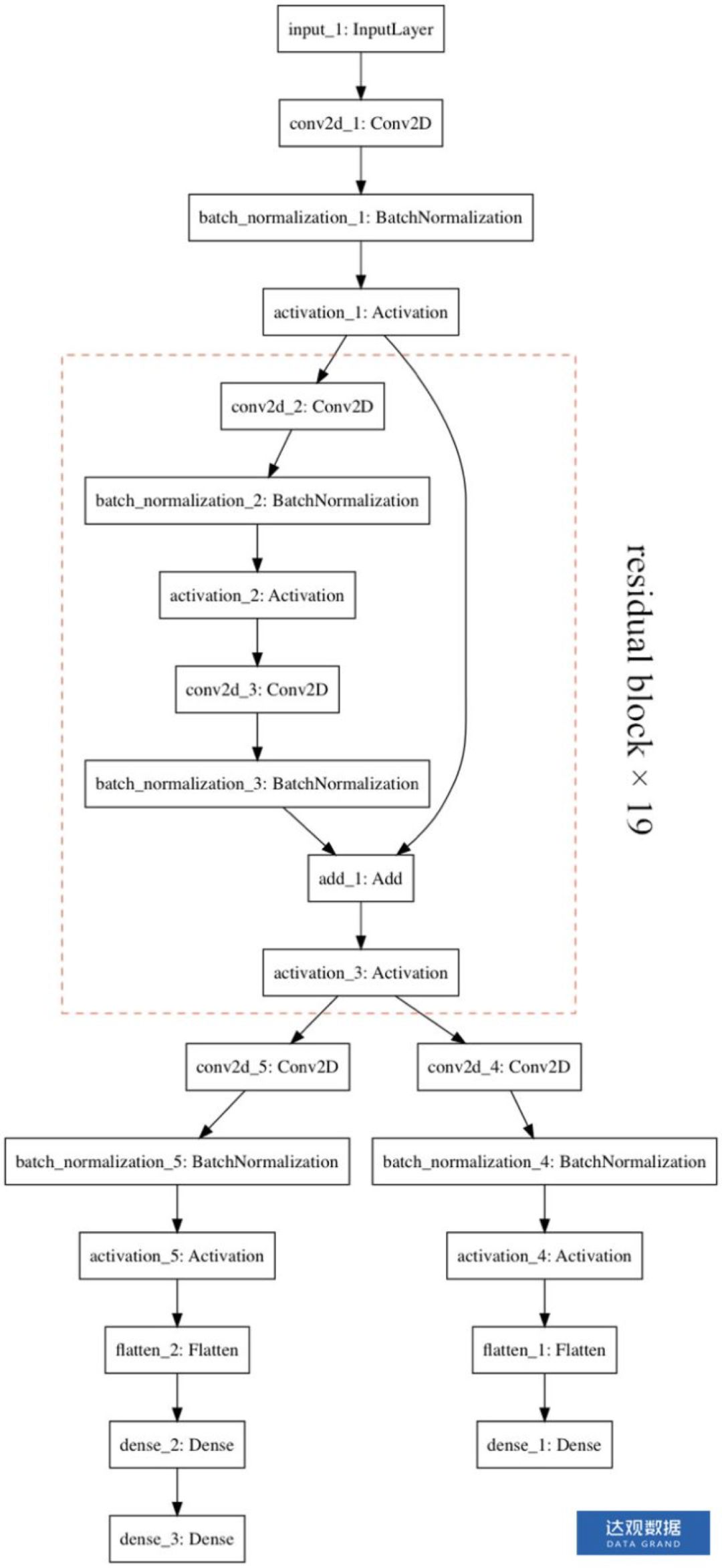
模型推荐看原文:
https://xueshu.baidu.com/usercenter/paper/show?paperid=a7600bdc74f5a07ed65256035cd15c6b&site=xueshu_se
自己的理解:
MCTS解决的是算力分配的问题,alphago主要解决了五个问题:
一是把深度学习和蒙特卡洛法相结合,取得一个准确和速度的平衡,用于评估当前局面。
二是使用监督数据,防止强化学习网络陷入策略循环,然后通过自博弈再提升自己。
三是网络训练方法,在监督学习阶段,将人类数据按照前后步切片,这样一局可以产生大量的训练数据,并且和输赢奖励联系起来,避免奖励稀疏。
四是使用策略网络模拟对手的落子,算是一种对minimax预测对手落子的一种改进吧?
五是工程上使用分布式计算,但是不知道怎么实现的,分布式mcts?
六.特征工程
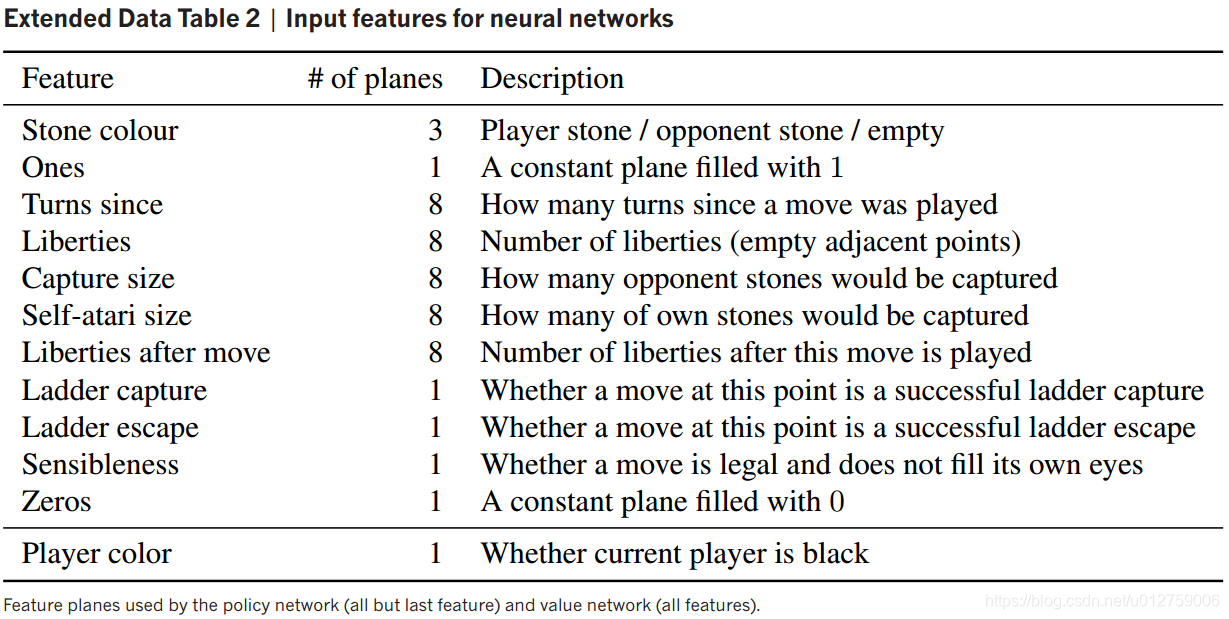
如上图所示,AlphaGo的策略网络和价值网络用于描述棋局当前局势的49个特征,棋盘上的361个点每个点都可以用这49个特征进行描述,下面将一一进行解读:
1、Stonecolour:
这个点放的黑子、白子还是空点。
2、Ones
赋值为常量1,具体作用不详。
3、Turns since
在周围的八个点中,这一步棋有多少变化。
4、Liberties
环绕这个点的八个点中,有几个空点。
5、Capture size
周围的八个点中,有几个点是对方的死子。
6、Self-atari size
周围的八个点中,有几个点是自己一方的死子。
7、Liberties after move
走过一步棋后,周围八个点有几个空点。
8、Ladder capture
征子是否成功捕获。
9、Ladder escape
征子是否成功逃脱。
10、Sensibleness
下步棋如果下这个点,是否合法(填在对方的眼里,并且没有气,则为不合法),或者有没有填自己的眼。
11、Zeros
和Ones一样,赋值为常量0,具体作用不详。
12、Player color
下一步是否该黑棋下。
alphago模型实际上并不美观,更多的一种训练网络的工程方法。
对alphago zero的期待:
zero没有使用监督数据,如何避免的低级策略循环?