- 文献题目:Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA
- 文献时间:2020
摘要
- 许多视觉场景包含带有关键信息的文本,因此理解图像中的文本对于下游推理任务至关重要。例如,警告标志上的深水标签警告人们现场的危险。最近的工作探索了 TextVQA 任务,该任务需要阅读和理解图像中的文本才能回答问题。然而,现有的 TextVQA 方法大多基于一对两种模态之间的自定义成对融合机制,并且通过将 TextVQA 转换为分类任务将其限制为单个预测步骤。在这项工作中,我们提出了一种新的 TextVQA 任务模型,该模型基于多模态转换器架构以及图像中文本的丰富表示。我们的模型通过将不同的模态嵌入到一个共同的语义空间中,自然地融合了不同的模态,在这个空间中,自我注意被应用于模态间和模态内的上下文。此外,它还支持使用动态指针网络进行迭代答案解码,允许模型通过多步预测而不是一步分类来形成答案。我们的模型在 TextVQA 任务的三个基准数据集上大大优于现有方法。
引言
- 作为视觉推理的一项突出任务,视觉问答 (VQA) 任务 [4] 在数据集(例如 [4, 17, 22, 21, 20])和方法(例如 [14] , 3, 6, 25, 33])。 然而,这些数据集和方法主要集中在场景中的视觉组件上。 另一方面,他们倾向于忽略一个关键的形式——图像中的文本——它为场景理解和推理提供了必要的信息。 例如,在图 1 中,标志上的深水警告人们现场的危险。 为了解决这个缺点,最近提出了新的 VQA 数据集 [44,8,37],其中明确需要理解和推理图像中的文本,这被称为 TextVQA 任务。
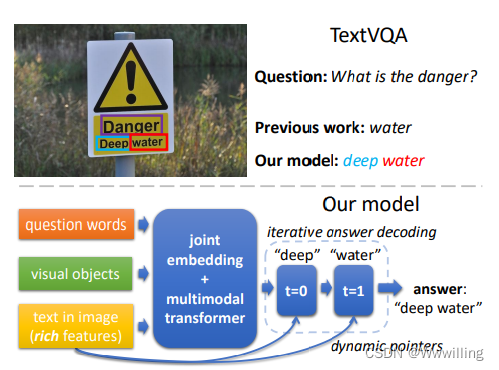
- 图 1. 与 TextVQA 任务上的先前工作(例如 [44])相比,我们的模型伴随着丰富的图像文本特征,在联合嵌入空间上使用多模态转换器处理所有模态,而不是模态之间的成对融合机制。 此外,答案是通过指针迭代解码来预测的,而不是在固定词汇表上进行一步分类或从图像中复制单个文本标记。
- TextVQA 任务明显要求模型通过三种模式来查看、阅读和推理:输入问题、图像中的视觉内容(例如视觉对象)和图像中的文本。 基于图像的 OCR 结果,已经为 TextVQA 任务提出了几种方法 [44、8、37、7]。 特别是,LoRRA [44] 使用 OCR 注意力分支扩展了先前的 VQA 模型 [43],并将 OCR 标记作为动态词汇添加到答案分类器中,允许从图像中复制单个 OCR 标记作为答案。 类似地,在 [37] 中,OCR 令牌被分组为块并添加到 VQA 模型的输出空间。
- 虽然这些方法可以在一定程度上读取图像中的文本,但它们通常依赖于两种模态之间的自定义成对多模态融合机制(例如图像区域上的单跳注意力和文本标记,以输入问题为条件),这限制了模态之间可能的交互类型。此外,他们将答案预测视为单步分类问题——要么从训练集中的答案中选择一个答案,要么从图像中复制一个文本标记——这使得生成复杂的答案变得困难,例如书名或带有多个单词的招牌名称,或使用常用词和特定图像文本标记的答案,例如麦当劳汉堡,其中麦当劳来自图像中的文本,汉堡来自模型自己的词汇。此外,之前工作中基于词嵌入的图像文本特征具有有限的表示能力,并且错过了诸如外观(例如字体和颜色)和文本标记在图像中的位置等重要线索。例如,对于具有不同字体并且在空间上彼此分开tokens,通常不属于同一个路牌。
- 在本文中,我们利用针对 TextVQA 任务的新型多模式多副本网格 (M4C) 模型解决了上述限制,该模型基于转换器 [48] 架构,并通过动态指针进行迭代答案解码,如图 1 所示。模型自然地融合了三种输入模态,并在多模态转换器内均匀地捕获模态内部和模态间的交互,将每个模态中的所有实体投影到一个共同的语义嵌入空间中,并应用自我注意机制 [38, 48] 来收集每个实体的关系表示。我们不是将答案预测作为分类任务,而是在多个步骤中执行迭代答案解码,并使用动态指针网络增强我们的答案解码器,该网络允许以排列不变的方式选择图像中的文本,而不依赖于任何广告- 先前工作中的 -hoc 位置索引,例如 LoRRA [44]。此外,我们的模型能够在生成的答案中将自己的词汇表与图像中的文本相结合,如图 4 和 5 中的示例所示。最后,我们引入了基于图像中文本标记的丰富表示多个线索,包括其词嵌入、外观、位置和字符级信息。
- 我们在本文中的贡献如下:1)我们表明,通过我们的多模态转换器架构,可以自然地融合和联合建模多个(两个以上)输入模态。 2) 与之前关于 TextVQA 的工作不同,我们的模型对答案的推理超出了单个分类步骤,并通过我们的指针增强多步解码器对其进行预测。 3)我们对图像中的文本标记采用了丰富的特征表示,并表明它比以前工作中仅基于词嵌入的特征要好。 4) 我们的模型在 TextVQA 任务的三个具有挑战性的数据集上的表现明显优于之前的工作:TextVQA [44](相对 +25%)、ST-VQA [8](相对 +65%)和 OCR-VQA [37] (+32% 相对)。
相关工作
- 基于阅读和理解图像文本的 VQA。最近,一些数据集和方法 [44, 8, 37, 7] 被提出用于基于图像中文本的视觉问答(称为 TextVQA 任务)。 LoRRA [44] 是该任务的一项重要先前工作,它扩展了用于 VQA 的 Pythia [43] 框架,并允许它通过应用单个注意力跳跃(以问题为条件)从图像中复制单个 OCR 标记作为答案在 OCR 标记上,并在答案分类器的输出空间中包含 OCR 标记索引。 [37] 中提出了一个概念上相似的模型,其中 OCR 标记被分组为块并添加到 VQA 模型的输入特征和输出答案空间。此外,其他一些方法 [8, 7] 通过使用 OCR 输入增强现有 VQA 模型来实现文本阅读。然而,这些现有方法受到图像文本的简单特征表示、多模态学习方法和答案输出的一步分类的限制。在这项工作中,我们使用 M4C 模型解决了这些限制。
- 视觉和语言任务中的多模式学习。视觉和语言任务的早期方法通常通过关注一种以另一种方式为条件的方式来结合图像和文本,例如基于文本的图像注意(例如 [51, 34])。一些方法已经探索了多模态融合机制,例如双线性模型(例如 [14, 25])、自注意力(例如 [15])和图网络(例如 [30])。受 Transformer [48] 和 BERT [13] 架构在自然语言任务中的成功启发,最近的几项工作 [33, 1, 47, 31, 29, 45, 53, 11] 也应用了基于转换器的图像和图像之间的融合在大规模数据集上具有自我监督的文本。然而,大多数现有作品使用一组特定的参数来处理每种模态,这使得它们难以扩展到更多的输入模态。另一方面,在我们的工作中,我们将每个模态中的所有实体投影到一个联合嵌入空间中,并在所有事物列表上使用变压器架构对它们进行同质处理。我们的结果表明,在对多个(超过两个)输入模式进行建模时,联合嵌入和自我注意是有效的。
- 带指针的动态复制。 TextVQA 任务中的许多答案来自图像中的文本标记,例如书名或街道标志。由于在答案词汇表中包含所有可能的文本标记是很困难的,因此从图像中复制文本通常是答案预测的一个更简单的选择。先前的工作已经探索了在不同任务中动态复制输入,例如基于指针网络 [50] 及其变体的文本摘要 [42]、知识检索 [52] 和图像字幕 [35]。对于 TextVQA 任务,最近的工作 [44, 37] 提出通过将 OCR 的索引添加到分类器输出来将 OCR 复制到 kens。然而,除了它们只能复制单个标记(或块)的限制之外,这些方法的一个缺点是它们需要预定义数量的 OCR 标记(因为分类器具有固定的输出维度)和它们的输出取决于令牌的顺序。在这项工作中,我们使用置换不变指针网络和我们的多模态转换器克服了这个缺点。
多模式多副本网格 (M4C)
- 在这项工作中,我们提出了 Multimodal Multi-Copy Mesh (M4C),这是一种用于 TextVQA 任务的新方法,它基于具有迭代答案预测的指针增强多模态转换器架构。 给定一个问题和一个图像作为输入,我们从三种模式中提取特征表示——问题、图像中的视觉对象和图像中存在的文本。 这三种模式分别表示为问题词特征列表、现成对象检测器的视觉对象特征列表和基于外部 OCR 系统的 OCR 标记特征列表。
- 我们的模型将实体的特征表示(在我们的例子中,问题词、检测到的对象和检测到的 OCR 标记)从三种模态中投影为学习的公共嵌入空间中的向量。 然后,在所有投影特征列表上应用多层变换器[48],通过模态内和模态间上下文丰富它们的表示。 我们的模型通过伴随动态指针网络的迭代解码来学习预测答案。 在解码过程中,它以自回归方式输入先前的输出以预测下一个答案分量。 在每一步,它要么从图像中复制一个 OCR 标记,要么从其固定的答案词汇表中选择一个单词。 图 2 显示了我们模型的概述。
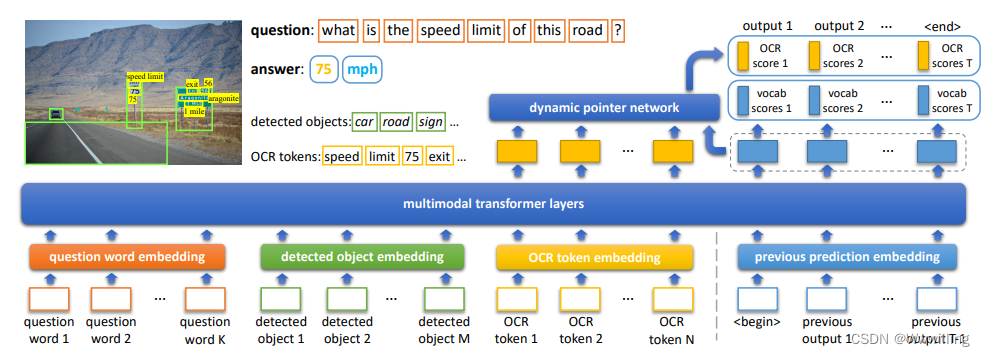
- 图 2.我们的 M4C 模型概述。 我们通过特定领域的嵌入方法将所有实体(问题词、检测到的视觉对象和检测到的 OCR 标记)投影到一个公共的 d 维语义空间中,并在投影事物列表上应用多个变换器层。 基于转换器的输出,我们通过迭代自回归解码来预测答案,在每一步,我们的模型要么通过我们的动态指针网络选择一个 OCR 标记,要么从其固定答案词汇表中选择一个词。
所有模式的公共嵌入空间
- 我们的模型接收来自三种模式的输入——问题词、视觉对象和 OCR 标记。 我们为每种模态提取特征表示,并通过如下领域特定的嵌入方法将它们投影到一个公共的 d 维语义空间中。
- 疑问词的嵌入。 给定一个问题作为 K K K个单词的序列,我们使用预训练的 BERT 模型 [13] 将这些单词嵌入到 d d d 维特征向量 { x k q u e s } \{x^{ques}_k\} {xkques}(其中 k = 1 , ⋅ ⋅ ⋅ ⋅ , K k = 1,····,K k=1,⋅⋅⋅⋅,K)的相应序列中。在训练期间,BERT 参数使用问答损失进行微调。
- 在我们的实现中,我们从 BERT-BASE 的前 3 层中提取问题词特征。 我们发现使用它的前几层就足够了,而不是使用它的所有 12 层,这样可以节省计算量。
- 检测到的对象的嵌入。 给定一张图像,我们通过预训练的检测器(在我们的例子中为 Faster R-CNN [41])获得一组
M
M
M 个视觉对象。 根据先前的工作 [3, 43, 44],我们使用检测器从第
m
m
m 个对象(其中
m
=
1
,
⋅
⋅
⋅
,
M
m = 1,···,M
m=1,⋅⋅⋅,M)的输出提取外观特征
x
m
f
r
x^{fr}_m
xmfr。 为了捕捉它在图像中的位置,我们从第
m
m
m 个对象的相对边界框坐标
[
x
m
i
n
/
W
i
m
,
y
m
i
n
/
H
i
m
,
x
m
a
x
/
W
i
m
,
y
m
a
x
/
H
i
m
]
[x_{min}/W_{im}, y_{min}/H_{im}, x_{max}/W_{im}, y_{max}/H_{im}]
[xmin/Wim,ymin/Him,xmax/Wim,ymax/Him] 中引入一个 4 维位置特征
x
m
b
x^b_m
xmb,其中
W
i
m
W_{im}
Wim 和
H
i
m
H_{im}
Him 分别是图像的宽度和高度。 然后,外观特征和位置特征通过两个学习的线性变换投影到
d
d
d 维空间中(其中
d
d
d 与上面问题词嵌入中的相同),并总结为最终的 object embedding
{
x
m
o
b
j
}
\{x^{obj}_m\}
{xmobj} 作为
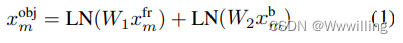
- 其中 W 1 W_1 W1 和 W 2 W_2 W2 是学习投影矩阵。 L N ( ⋅ ) LN(·) LN(⋅) 是层归一化[5],添加在线性变换的输出上,以确保对象嵌入与问题词嵌入具有相同的尺度。 我们在训练期间微调了 Faster R-CNN 检测器的最后一层。
- 具有丰富表示的 OCR 令牌的嵌入。直观地说,要在图像中表示文本,不仅需要编码其字符,还要编码其外观(例如颜色、字体和背景)和图像中的空间位置(例如出现在书本顶部的单词)封面更可能是书名)。我们在我们的模型中遵循这种直觉,并使用由四种类型的特征组成的丰富的 OCR 表示,在我们的实验中表明,这在之前的工作中明显优于单独的词嵌入(如 FastText)[44]。通过外部 OCR 系统获得图像中的一组 N N N 个 OCR 标记后,从第 n n n 个标记(其中 n = 1 , ⋅ ⋅ ⋅ , N n = 1,···,N n=1,⋅⋅⋅,N)中提取
- 一个300维的FastText[9]向量xftn,它是一个带有子词信息的词嵌入,
- 来自上述对象检测中相同 Faster R-CNN 检测器的外观特征 x n f r x^{fr}_n xnfr,通过 OCR 令牌边界框上的 RoI-Pooling 提取,
- 一个 604 维的字符金字塔直方图 (PHOC) [2] 向量 x n p x^p_n xnp,捕捉令牌中存在的字符——这对 OCR 错误更稳健,可以看作是粗略的字符模型,以及
- 基于 OCR 标记的相对边界框坐标
[
x
m
i
n
/
W
i
m
,
y
m
i
n
/
H
i
m
,
x
m
a
x
/
W
i
m
,
y
m
a
x
/
H
i
m
]
[x_{min}/W_{im}, y_{min}/H_{im}, x_{max}/W_{im}, y_{max}/H_{im}]
[xmin/Wim,ymin/Him,xmax/Wim,ymax/Him]的 4 维位置特征
x
n
b
x^b_n
xnb。我们将每个特征线性投影到
d
d
d 维空间中,并将它们相加(经过层归一化)作为最终的 OCR 令牌嵌入
{
x
n
o
c
r
}
\{x^{ocr}_n\}
{xnocr},如下所示
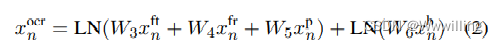
- 其中 W 3 W_3 W3、 W 4 W_4 W4、 W 5 W_5 W5 和 W 6 W_6 W6 是学习投影矩阵, L N ( ⋅ ) LN(·) LN(⋅) 是层归一化。
使用指针增强变换器的多模态融合和迭代答案预测
- 在将来自每个模态的所有实体(问题词、视觉对象和 OCR 标记)作为向量嵌入到 d d d 维联合嵌入空间中之后,如第 2 节所述。 在图 3.1 中,我们在来自 { x k q u e s } \{x^{ques}_k\} {xkques}、 { x m o b j } \{x^{obj}_m\} {xmobj} 和 { x n o c r } \{x^{ocr}_n\} {xnocr} 的所有 K + M + N K + M + N K+M+N 实体的列表上应用了 L L L 层变换层 [48],隐藏维度为 d d d。 通过 Transformer 中的多头自注意力机制,每个实体都可以自由地关注所有其他实体,无论它们是否来自同一模态。 例如,允许一个 OCR 令牌关注另一个 OCR 令牌、检测到的对象或疑问词。 这使得通过同一组变压器参数以同质的方式对模态间和模态内的关系进行建模。 我们的多模态转换器的输出是每个模态中实体的 d d d 维特征向量列表,这可以看作是它们在多模态上下文中的丰富嵌入。
- 我们通过迭代解码预测问题的答案,使用与解码器完全相同的转换器层。 我们以自回归的方式逐字解码答案,总共 T T T 步,其中每个解码的单词可能是图像中的 OCR 标记,也可能是我们固定的常用答案词词汇表中的一个词。 如图 2 所示,在解码过程的每个步骤中,我们输入先前预测的单词的嵌入,并使用动态指针网络根据转换器输出预测下一个答案单词。
- 令
{
z
1
o
c
r
,
⋅
⋅
⋅
⋅
,
z
N
o
c
r
}
\{z^{ocr}_1,····, z^{ocr}_N\}
{z1ocr,⋅⋅⋅⋅,zNocr} 为图像中
N
N
N 个 OCR 标记的
d
d
d 维变换器输出。 假设我们有一个经常出现在训练集答案中的
V
V
V 个单词的词汇表。 在第
t
t
t 个解码步骤,transformer 模型输出一个
d
d
d 维向量
z
t
d
e
c
z^{dec}_t
ztdec,对应于步骤
t
t
t 的输入
x
t
d
e
c
x^{dec}_t
xtdec(本节稍后解释)。 从
z
t
d
e
c
z^{dec}_t
ztdec中,我们预测从固定答案词汇表中选择单词的
V
V
V 维分数
y
t
v
o
c
y^{voc}_t
ytvoc 和在解码步骤
t
t
t 从图像中选择 OCR 标记的
N
N
N 维分数
y
t
o
c
r
y^{ocr}_ t
ytocr。 在我们的实现中,第
i
i
i 个单词(其中
i
=
1
,
⋅
⋅
⋅
,
V
i = 1,···,V
i=1,⋅⋅⋅,V)的固定答案词汇分数
y
t
,
i
v
o
c
y^{voc}_{t,i}
yt,ivoc 被预测为一个简单的线性层:
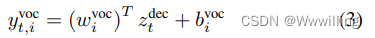
- 其中 w i v o c w^{voc}_i wivoc 是答案词汇表中第 i i i 个单词的 d d d 维参数, b i v o c b^{voc}_i bivoc 是标量参数。
- 为了从图像中的
N
N
N 个 OCR 标记中选择一个标记,我们使用动态指针网络增强了转换器模型,通过双线性预测每个标记的复制分数
y
t
,
n
o
c
r
y^{ocr}_{t,n}
yt,nocr(其中
n
=
1
,
⋅
⋅
⋅
,
N
n = 1,···,N
n=1,⋅⋅⋅,N) 解码输出
z
t
d
e
c
z^{dec}_t
ztdec 和每个 OCR 令牌的输出表示
z
n
o
c
r
z^{ocr}_n
znocr 之间的交互
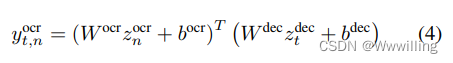
- 其中 W o c r W^{ocr} Wocr 和 W d e c W^{dec} Wdec 是 d × d d × d d×d 矩阵, b o c r b^{ocr} bocr 和 b d e c b^{dec} bdec 是 d d d 维向量。
- 在预测期间,我们在固定答案词汇分数和动态 OCR 复制分数的 concat y t a l l = [ y t v o c ; y t o c r ] y^{all}_t = [y^{voc}_t; y^{ocr}_t] ytall=[ytvoc;ytocr]上取 argmax,从所有 V + N V + N V+N 个候选中选择得分最高的元素(词汇词或 OCR 标记)。
- 在我们的迭代自回归解码过程中,如果解码时间步 t t t 的预测是一个 OCR 令牌,我们将其 OCR 表示 x n o c r x^{ocr}_n xnocr 作为变换器输入 x t + 1 d e c x^{dec}_{t+1} xt+1dec 输入到下一个预测步 t + 1 t + 1 t+1。否则(前一个预测是固定答案词汇表中的一个词),我们将其对应的权重向量 w i v o c w^{voc}_i wivoc 输入方程 3 作为下一步的输入 x t + 1 d e c x^{dec}_{t+1} xt+1dec。 此外,我们添加了两个额外的 d d d 维向量作为输入——一个对应于步骤 t t t 的位置嵌入向量,以及一个对应于先前预测是固定词汇词还是 OCR 标记的类型嵌入向量。 与机器翻译类似,我们使用两个特殊标记 < b e g i n > <begin> <begin> 和 < e n d > <end> <end> 来扩充我们的答案词汇。 这里 < b e g i n > <begin> <begin> 被用作第一个解码步骤的输入,我们在 < e n d > <end> <end>被预测后停止解码过程。
- 为了确保答案解码中的因果关系,我们掩盖了变压器架构 [48] 的自注意力层中的注意力权重,使得问题词、检测到的对象和 OCR 令牌不能参与任何解码步骤,并且所有解码步骤除了问题词、检测到的对象和 OCR 标记之外,只能关注之前的解码步骤。 这类似于 [40] 中的前缀 LM。
训练
- 在训练期间,我们在每个解码步骤监督我们的多模态转换器。 与机器翻译等序列预测任务类似,我们使用teacher forcing [28](即使用解码器的真实输入)来训练我们的多步答案解码器,其中每个基本事实答案都被标记为一系列单词。 鉴于答案词可以出现在固定答案词汇和 OCR 标记中,我们在级联分数 y t a l l y^{all}_t ytall 上应用多标签 sigmoid 损失(而不是 softmax 损失)。
实验
- 我们在 TextVQA 任务的三个具有挑战性的数据集上评估我们的模型,包括 TextVQA [44]、ST-VQA [8] 和 OCR-VQA [37](我们仅将这些数据集用于研究目的)。 我们的模型在所有三个数据集上都大大优于以前的工作。
TextVQA 数据集的评估
- TextVQA 数据集 [44] 包含来自 Open Images 数据集 [27] 的 28,408 张图像,其中包含人类编写的问题,要求对图像中的文本进行推理。 与 VQAv2 [17] 类似,TextVQA 数据集中的每个问题都有 10 个人工注释的答案,最终的准确性是通过对 10 个答案的软投票来衡量的。
- 有关详细信息,请参阅 https://visualqa.org/evaluation。
- 我们使用 d = 768 d = 768 d=768 作为联合嵌入空间的维数,并使用 BERT-BASE 使用前三层的 768 维输出提取问题词特征,这些输出在训练期间进行了微调。
- 对于视觉对象,按照 Pythia [43] 和 LoRRA [44],我们使用在视觉基因组数据集 [26] 上预训练的 Faster R-CNN 检测器 [41] 检测对象,并为每张图像保留 100 个得分最高的对象。 然后,从每个检测到的对象中提取 fc6 特征向量。 我们在提取的 fc6 特征上应用 Faster R-CNN fc7 权重,以输出 2048 维 fc7 外观特征并在训练期间微调 fc7 权重。 但是,我们没有像在 LoRRA 中那样使用 ResNet-152 卷积特征 [19]。
- 最后,我们使用 Rosetta OCR 系统 [10] 在每个图像上提取文本标记。 与使用多语言 Rosetta 版本的先前工作 LoRRA [44] 不同,在我们的模型中,我们使用仅英语版本的 Rosetta,我们发现它具有更高的召回率。 我们将这两个版本分别称为 Rosetta-ml 和 Rosetta-en。 如 3.1 节所述,我们从每个 OCR 标记中提取 FastText [9] 特征、Faster R-CNN (FRCN) 的外观特征、PHOC [2] 特征和边界框 (bbox) 特征。
- 在我们的多模态变换器中,我们使用 L = 4 L = 4 L=4 层多模态变换器和 12 个注意力头。 其他超参数(例如 dropout ratio)遵循 BERT BASE [13]。 但是,我们注意到多模态变压器参数是从头开始初始化的,而不是从预训练的 BERT 模型中初始化的。 除非另有说明,否则我们在答案预测中使用 T = 12 T = 12 T=12 的最大解码步长,这足以覆盖几乎所有答案。
- 我们从训练集中的答案中收集前 5000 个常用词作为我们的答案词汇。 在训练期间,我们使用 128 的批量大小,并训练最多 24,000 次迭代。 我们的模型使用 Adam 优化器进行训练,学习率为 1e-4 和阶梯式学习率计划,我们在 14000 和 19000 次迭代时将学习率乘以 0.1。 使用验证集准确度选择最佳快照。 整个训练在 4 个 Nvidia Tesla V100 GPU 上大约需要 10 个小时。
- 作为该数据集的一项值得注意的先前工作,我们展示了与 LoRRA 模型 [44] 的逐步比较。 LoRRA 在图像视觉特征和 OCR 特征上使用两个单跳注意力层。 然后将参与的视觉和 OCR 特征与问题的矢量编码融合,并输入单步分类器,以从训练集中选择频繁答案或从图像中选择单个 OCR 标记。 与我们在 Sec 3.1 中丰富的 OCR 表示不同。在 LoRRA 模型中,每个 OCR 令牌仅表示为 300 维的 FastText 向量。
- 预训练问题编码和 OCR 系统的消融。我们首先使用多模态转换器架构对我们模型的受限版本进行实验,但在答案预测中没有迭代解码,即表 1 中的 M4C (w/o dec.)。在这种情况下,我们只解码一步,并且从训练集中选择一个频繁的答案或复制图像中的单个 OCR 标记作为答案。作为与 LoRRA 的分步比较,我们首先从 Rosetta-ml 中提取 OCR 标记,仅使用 FastText 向量表示 OCR 标记,并在第 3.1 节中从头开始(而不是从预训练的BERT-BASE 模型)。结果如表 1 的第 3 行所示。与第 1 行中的 LoRRA 相比,我们模型的这个受限版本在 TextVQA 验证集上的性能已经超过 LoRRA 约 3%(绝对值)。该结果表明,我们的多模态变压器架构对于联合建模三种输入模态更有效。我们还尝试像在 LoRRA 中一样从 GloVe [39] 中初始化词嵌入,并从头开始初始化其余参数,如第 2 行所示。然而,我们发现这个设置在从头开始初始化所有内容时表现稍差,我们怀疑是由于 LoRRA 和我们模型中使用的 BERT 分词器之间的问题分词不同。然后,我们在第 4 行切换到预训练的 BERT 进行问题编码,在第 5 行切换到 Rosetta-en 进行 OCR 提取。比较第 3 行和第 5 行,我们看到预训练的 BERT 导致大约 0.6% 的准确度,而 Rosetta-en 又提高了 1%。
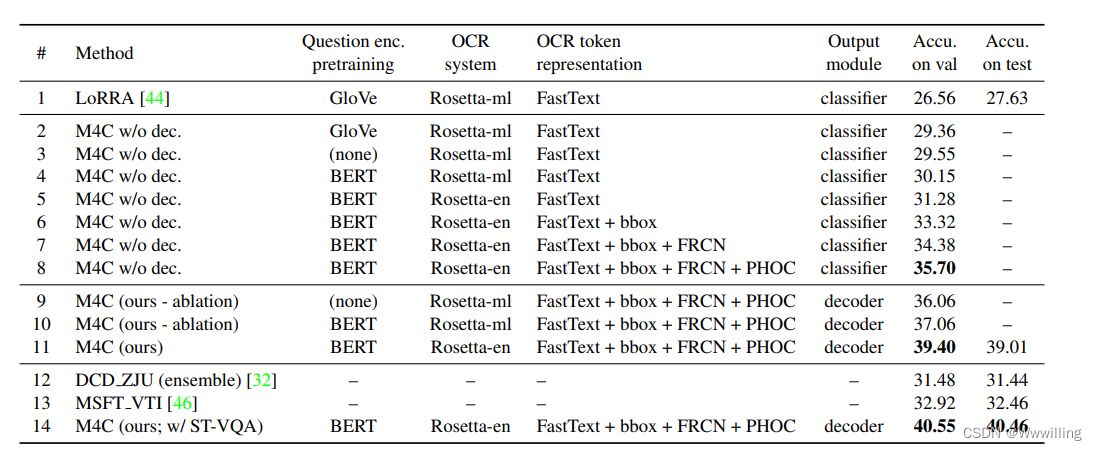
- 表 1. 在 TextVQA 数据集上,我们消融了我们的 M4C 模型,并显示了与先前工作 LoRRA [44] 的详细比较。 我们的多模态转换器(第 3 对 1 行)、我们丰富的 OCR 表示(第 8 对 5 行)和我们的迭代答案预测(第 11 对 8 行)都显着提高了准确性。 值得注意的是,即使使用较少的预训练参数(第 9 行与第 1 行),我们的模型仍比 LoRRA 高 9.5%(绝对值)。 我们的最终模型在没有和使用 ST-VQA 数据集作为额外训练的情况下实现了 39.01%(第 11 行)和 40.46%(第 14 行)的测试准确度
数据,比赢得挑战的 DCD ZJU 方法高出 9%(绝对值)。 有关详细信息,请参见第 4.1 节。 - 在这种情况下,我们预测整个(多词)答案,而不是像在我们的完整模型中那样从我们的答案词词汇表中预测单个词。
- OCR 特征表示的消融。我们通过表 1 第 5 到第 8 行中的消融分析了我们在第 3.1 节中丰富的 OCR 表示的影响。我们看到 OCR 位置 (bbox) 特征和 RoI-pooled 外观特征 (FRCN) 都显着提高了性能。 此外,我们发现 PHOC 作为 OCR 令牌的字符级表示也很有帮助。 与在 LoRRA 中仅使用 FastText 功能(第 8 行与第 5 行)相比,我们丰富的 OCR 表示提供了大约 4%(绝对)的准确度提高。 我们注意到,我们额外的 OCR 特征不需要更多的预训练模型,因为我们在 OCR 外观特征的对象检测中应用了完全相同的 Faster R-CNN 模型,而 PHOC 是手动设计的功能,不需要预训练。
- 迭代答案解码。然后,我们将带有迭代答案解码的完整 M4C 模型应用于 TextVQA 数据集。结果如表 1 第 11 行所示,比使用单步分类器的第 8 行中的对应项高约 4%(绝对),比第 1 行中的 LoRRA 高 13%(绝对)。此外,我们消融了我们的在第 9 行和第 10 行中使用 Rosetta-ml 和随机初始化的问题编码参数进行建模。在这里,我们看到第 9 行中的模型在使用相同的 OCR 时仍然比 LoRRA(第 1 行)高出 9.5%(绝对值)系统作为 LoRRA,甚至更少的预训练组件。我们还分析了我们的模型在最大解码步骤方面的性能,如图 3 所示,与单步相比,多步解码大大提高了性能。图 4 显示了我们在 TextVQA 数据集上的 M4C 模型与 LoRRA [44] 相比的定性示例(更多示例在附录中),其中我们的模型能够选择多个 OCR 标记并将它们与预测答案中的固定词汇表相结合。
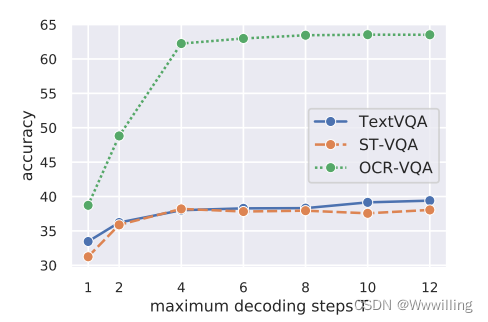
- 图 3. TextVQA、ST-VQA 和 OCR-VQA 验证集上不同最大解码步长
T
T
T 下的准确度。 单步
(
T
=
1
)
(T = 1)
(T=1) 和多步
(
T
>
1
)
(T > 1)
(T>1) 答案预测之间存在很大差距。 我们在实验中默认使用 12 个步骤。

- 图 4. 我们 M4C 模型在 TextVQA 验证集上的定性示例(橙色词来自 OCR 标记,蓝色词来自固定答案词汇表)。 与之前的工作 LoRRA [44] 从训练集中选择一个答案或仅复制单个 OCR 令牌相比,我们的模型可以复制多个 OCR 令牌并通过迭代解码将它们与固定词汇表结合起来。
- 定性见解。 在检查错误时,我们发现错误的主要来源是 OCR 失败(例如,在图 4 的最后一个示例中,我们发现未检测到手表上的数字)。 这表明我们的模型的准确性可以通过更好的 OCR 系统来提高,如表 1 中第 10 行和第 11 行之间的比较所支持的那样。另一个可能的未来方向是根据问题动态识别图像中的文本(例如 如果问题是关于产品品牌的价格,可能需要直接将图片中的品牌名称本地化)。 我们模型的其他一些错误包括解决对象和文本之间的关系或理解图像中的大块文本(例如书页)。 然而,我们的模型能够纠正以前工作中的大量错误,即需要复制多个文本标记来形成答案。
- TextVQA Challenge 2019。我们还与 TextVQA Challenge 2019 中的获胜条目进行了比较。我们将我们的方法与 DCD [32](挑战获胜者,基于 ensemble)和 MSFT_VTI [46](挑战后的最高条目),都依赖于一步预测。 我们表明,我们的单一模型(第 11 行)在 TextVQA 测试集上大大优于这些挑战获胜条目。 我们还尝试使用 ST-VQA 数据集 [8] 作为额外的训练数据(之前的一些挑战参与者使用的一种做法),这又带来了 1% 的改进和 40.46% 的最终测试准确率——这是 TextVQA 数据集上的最新技术。
- https://textvqa.org/challenge
ST-VQA 数据集的评估
- ST-VQA 数据集 [8] 包含来自多个来源的自然图像,包括 ICDAR 2013 [24]、ICDAR 2015[23]、ImageNet [12]、VizWiz [18]、IIIT STR [36]、Visual Genome [26] 和 COCO-Text [49].5 ST VQA 数据集的格式类似于 Sec 4.1 中的 TextVQA 数据集。 但是,每个问题都只附有问题作者提供的一两个基本事实答案。 该数据集涉及三个任务,其任务 3 - 开放字典(包含 18,921 个训练验证图像和 2,971 个测试图像)对应于我们的一般 TextVQA 设置,其中在测试时不提供候选答案。
- 我们注意到,在下载的 ST-VQA 数据中,来自 COCO-Text [49] 的许多图像(约占所有图像的 1/3)由于未知原因被调整为 256×256,这会降低图像质量并扭曲它们的宽高比。 在我们的实验中,我们将这些图像替换为来自 COCO-Text 的原始版本,作为对象检测和 OCR 系统的输入。
- ST-VQA 数据集采用平均归一化 Levenshtein Similarity (ANLS) 作为其官方评估指标,定义为所有问题的平均分数 1 − d L ( a p r e d , a g t ) / m a x ( ∣ a p r e d ∣ , ∣ a g t ∣ ) 1 - d_L(a_{pred}, agt)/ max(|a_{pred}|, |a_{gt}|) 1−dL(apred,agt)/max(∣apred∣,∣agt∣)(其中 a p r e d a_{pred} apred 和 a g t a_{gt} agt 是预测和真实答案, d L d_L dL 是编辑距离)。 此外,所有低于阈值 0.5 的分数在平均之前都被截断为 0。 为了便于比较,我们在实验中报告了准确性和 ANLS。
- https://rrc.cvc.uab.es/?ch=11&com=tasks
- 由于 ST-VQA 数据集没有用于训练和验证的官方拆分,我们随机选择 17,028 张图像作为我们的训练集,并使用剩余的 1,893 张图像作为我们的验证集。 我们在 ST-VQA 数据集上训练我们的模型,设置与第 4.1 节中的 TextVQA 实验中完全相同的设置(表 1 中的第 11 行),我们使用 Rosetta-en 提取图像文本标记,使用 FastText + bbox + FRCN + PHOC 作为我们的 OCR 表示,并从预训练的 BERT-BASE 模型初始化问题编码参数。 结果如表2所示。
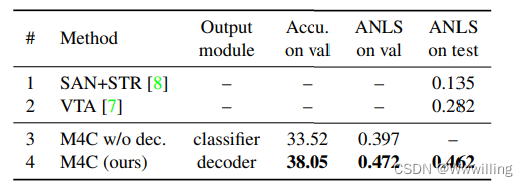
- 表 2. 在 ST-VQA 数据集上,我们没有解码器的受限模型(M4C w/o dec.)已经大大优于以前的工作。 我们的最终模型比挑战获胜者 VTA [7] 实现了 +0.18(绝对)ANLS 提升。 有关详细信息,请参见第 4.2 节。
- 我们模型的消融。 我们训练了我们模型的两个版本,一个受限版本(表 2 中的 M4C w/o dec.)使用固定的单步分类器作为输出模块(类似于表 1 中的第 8 行)和一个完整版本(M4C),具有迭代 答案解码。 比较这两个模型的结果,可以看出我们的迭代答案预测机制有很大的改进。
- 与以前的工作进行比较。 我们在此数据集上与之前的两种方法进行比较:
- SAN+STR [8],结合 SAN 用于 VQA [51] 和 Scene Text Retrieval [16] 用于答案词汇检索,以及
- VTA [7],ICDAR 2019 ST-VQA Challenge6 的获胜者,基于用于问题编码的 BERT [13] 和用于 VQA 的 BUTD [3]。 从表 2 可以看出,我们的受限模型(M4C w/o dec.)已经比这两个模型实现了更高的 ANLS,我们的完整模型比之前的最佳工作实现了 +0.18(绝对)ANLS 提升。
- 我们还在图 3 中消除了我们模型中的最大复制数,表明对多个(而不是一个)步骤进行解码是有益的。 图 5 显示了我们模型在 ST-VQA 数据集上的定性示例。

- 图 5. 我们的 M4C 模型在 ST-VQA 验证集上的定性示例(OCR 令牌中的橙色词和固定答案词汇中的蓝色词)。 我们的模型可以选择多个 OCR 标记并将它们与固定词汇表结合起来以预测答案。
OCR-VQA 数据集的评估
- OCR-VQA 数据集 [37] 包含 207,572 张书籍封面图像,并带有基于模板的问题,询问有关书籍的标题、作者、版本、流派、年份或其他信息。 每个问题都有一个真实的答案,并且数据集假设这些问题的答案可以从书籍封面图像中推断出来。
- 我们使用与第 4.1 节和第 4.2 节中相同的超参数来训练我们的模型,但由于 OCR-VQA 数据集包含更多图像,因此使用了 2 倍的总迭代次数和适应的学习率计划。 结果如表 3 所示。与使用单步分类器(M4C w/o dec.)相比,我们具有迭代解码的完整模型实现了显着更好的准确性,这与图 3 一致,即具有多个解码步骤对该数据集非常有益。 这可能是因为 OCR-VQA 数据集通常包含多字答案,例如书名和作者姓名。

- 表 3. 在 OCR-VQA 数据集上,我们尝试使用迭代解码器(我们的完整模型)或单步分类器(M4C w/o dec.)作为输出模块,其中我们的迭代解码器极大地提高了准确性,并且大大优于基线方法。 有关详细信息,请参见第 4.3 节。
- 我们与 [37] 中的四种基线方法进行比较,它们是基于
1)来自卷积网络(CNN)的视觉特征,
- 使用手动定义的规则将 OCR 标记分组为文本块 (BLOCK),
- 图像中所有 OCR tokens 的平均 word2vec (W2V) 特征,以及
4)它们的组合。 请注意,虽然 BLOCK 基线也可以选择多个 OCR 标记,但它依赖于手动定义的规则将标记合并到组中,并且只能选择一个组作为答案,而我们的方法从数据中学习如何复制 OCR 标记来组成答案。 与这些基线相比,我们的 M4C 的测试准确度高出 15%(绝对)以上。 图 6 显示了我们模型在该数据集上的定性示例。

- 图 6. 我们的 M4C 模型在 OCR VQA 验证集上的定性示例(OCR 标记中的橙色词和固定答案词汇中的蓝色词)。
结论
- 在本文中,我们提出了基于对图像中文本的理解和推理的视觉问答的多模态多副本网格 (M4C)。 M4C 对图像中的文本采用丰富的表示,通过指针增强的多模态变换器架构在联合嵌入空间上对所有模态进行联合建模,并通过迭代解码预测答案,在 TextVQA 任务的三个具有挑战性的数据集上大大优于以前的工作。 我们的结果表明,通过特定领域的嵌入处理多种模态,然后是同质的自我关注,并生成复杂的答案作为多步解码而不是一步分类是有效的。
附录
M4C 中的超参数
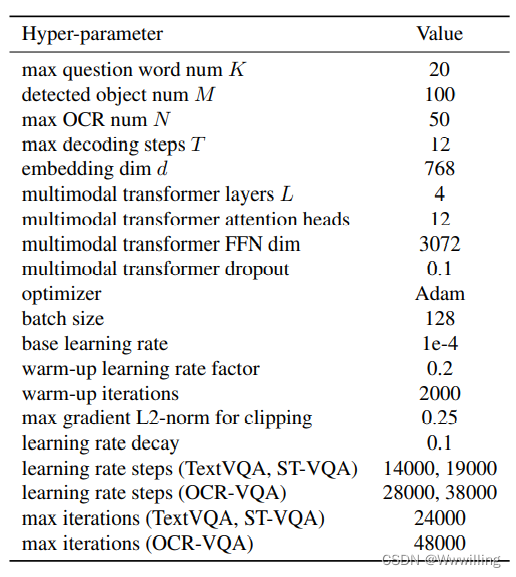
- 我们在表 A.1 中总结了 M4C 模型中的超参数。 大多数超参数在所有三个数据集(TextVQA、ST-VQA 和 OCR-VQA)上都是相同的,除了我们在 OCR-VQA 数据集上使用 2 倍的总迭代次数和自适应学习率计划,因为它包含更多图像。
附加消融分析
- 在迭代答案解码过程中,在每个步骤中,我们的 M4C 模型都可以从模型的固定词汇表或从图像中提取的 OCR 标记中解码答案词。 我们在实验中发现,必须同时拥有固定的词汇空间和 OCR 标记。
- 表 B.1 显示了我们的消融研究,其中我们从 M4C 中删除了用于 OCR 复制的固定答案词汇或动态指针网络。 与我们的完整模型相比,这两个消融版本都有很大的精度下降。 然而,我们注意到,即使没有固定的答案词汇,我们的受限模型(表 B.1 中没有固定词汇的 M4C)仍然优于之前的工作 LoRRA [44],这表明学习复制多个 OCR 标记以形成答案是特别重要的(我们模型中的关键特征,但在 LoRRA 中没有)。

- 表 B.1。 我们通过在 TextVQA 数据集上删除其固定答案词汇表(M4C w/o fixed词汇表)或其用于 OCR 复制的动态指针网络(M4C w/o OCR copying)来消融我们的 M4C 模型。 我们看到我们的完整模型比这些消融具有显着更高的准确性,这表明同时拥有固定和动态词汇表(即 OCR 标记)很重要。
其他定性示例
- 如第二节所述。 在主论文 4.1 中,我们发现 OCR 失败是我们 M4C 模型预测的主要错误来源。 图 C.1 显示了 TextVQA 数据集上 OCR 系统无法精确定位图像中相应文本标记的情况,这表明我们的模型的准确性可以通过更好的 OCR 系统来提高。
- 图 C.2、C.3 和 C.4 分别显示了我们的 M4C 模型在 TextVQA 数据集、ST-VQA 和 OCR-VQA 数据集上的其他定性示例。 虽然我们的模型在读取大量文本或解析文本与对象之间的关系时偶尔会失败,如图 C.2 (f) 和 (h) 所示,但在大多数情况下,它会学习从图像中识别和复制文本标记,并将它们与其固定词汇结合起来以预测答案。