小程序
sqlserver
虚拟设备
聚类
安全威胁分析
关联数组
bert
博通蓝牙使能
big data
RHCE
产品设计误区
wireshark
训练数据
几何
BH1750
三栏布局
tornado
es6
图像视图
非线性函数拟合
【Decision Transformer】












相关文章
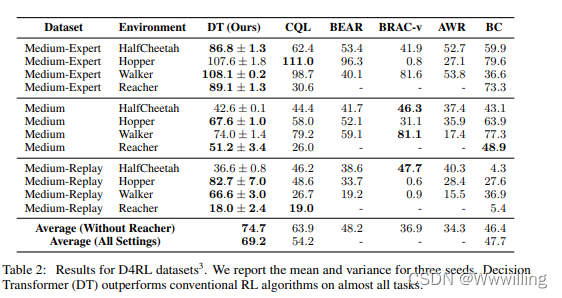
【强化学习论文】Decision Transformer:通过序列建模进行强化学习
Article
文献题目:Decision Transformer: Reinforcement Learning via Sequence Modeling 文献时间:2021
摘要
我们引入了一个将强化学习(RL)抽象为序列建模问题的框架。 这使我们能够利用 Transformer 架构的简单性和可扩展性…
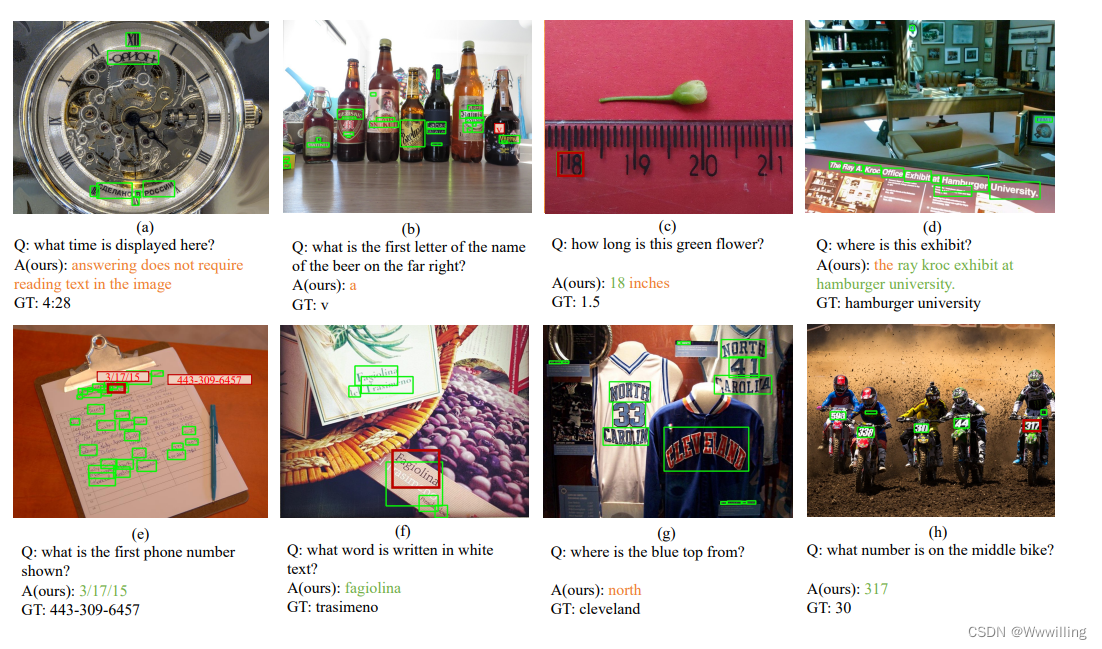
【Transformer论文】简单并不容易:TextVQA 和 TextCaps 的简单强基线
文献题目:Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
摘要
OCR(光学字符识别)工具可以识别的日常场景中出现的文本包含重要信息,例如街道名称、产品品牌和价格。两项任务——基于文本的视觉问答和…

【Transformer论文】用于 TextVQA 的指针增强多模态变换器的迭代答案预测
文献题目:Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA文献时间:2020
摘要
许多视觉场景包含带有关键信息的文本,因此理解图像中的文本对于下游推理任务至关重要。例如,警告标志上…
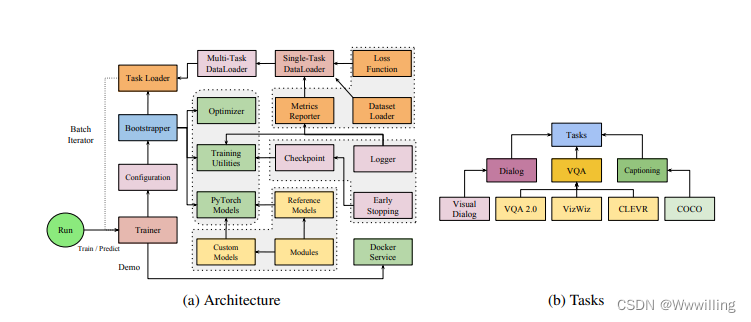
Pythia - 视觉和语言研究平台
文献题目:Pythia - A platform for vision & language research
摘要 本文介绍了 Pythia,一个用于视觉和语言任务的深度学习研究平台。 Pythia 以即插即用策略为核心,使研究人员能够为视觉和语言任务(如视觉问答 (VQA)、视觉…

【计算机视觉】TextFuseNet:具有更丰富融合特征的场景文本检测
文献题目:TextFuseNet: Scene Text Detection with Richer Fused Features文献时间:2020
摘要
自然场景中的任意形状文本检测是一项极具挑战性的任务。与仅基于有限特征表示来感知文本的现有文本检测方法不同,我们提出了一个新颖的框架&…
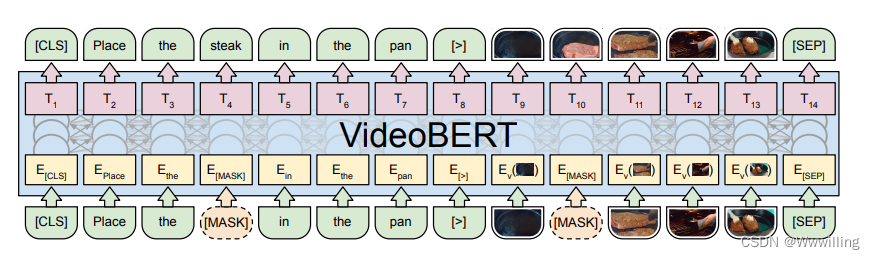
【Transformer论文】VideoBERT:视频和语言表示学习的联合模型
文献题目:VideoBERT: A Joint Model for Video and Language Representation Learning代码:https://github.com/ammesatyajit/VideoBERT
摘要
自我监督学习对于利用 YouTube 等平台上可用的大量未标记数据变得越来越重要。尽管大多数现有方法都学习低级…
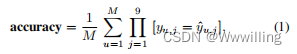
【Transformer论文】使用 Transformer 网络的会话感知项目组合推荐
文献题目:Session-aware Item-combination Recommendation with Transformer Network
摘要
在本文中,我们详细描述了我们的 IEEE BigData Cup 2021 解决方案:基于 RL 的 RecSys(Track 1:Item Combination Prediction…

【推荐系统论文】推荐系统的监督优势 Actor-Critic
文章标题:Supervised Advantage Actor-Critic for Recommender Systems发表时间:2022
摘要
通过奖励信号将基于会话或顺序的推荐作为强化学习 (RL) 是朝着最大化累积利润的推荐系统 (RS) 的一个有前途的研究方向。 然而,由于策略外训练、巨…