java-rocketmq
Arduino
leetcode
论文阅读
CMake
汇编
文学
网络技术
intellij-idea
客快物流大数据项目
基因组学
两数之和
三十
ThingsBoard
uml
FANUC机器人
医院运营
proteus
php桶装水配送系统
数据库增删改查
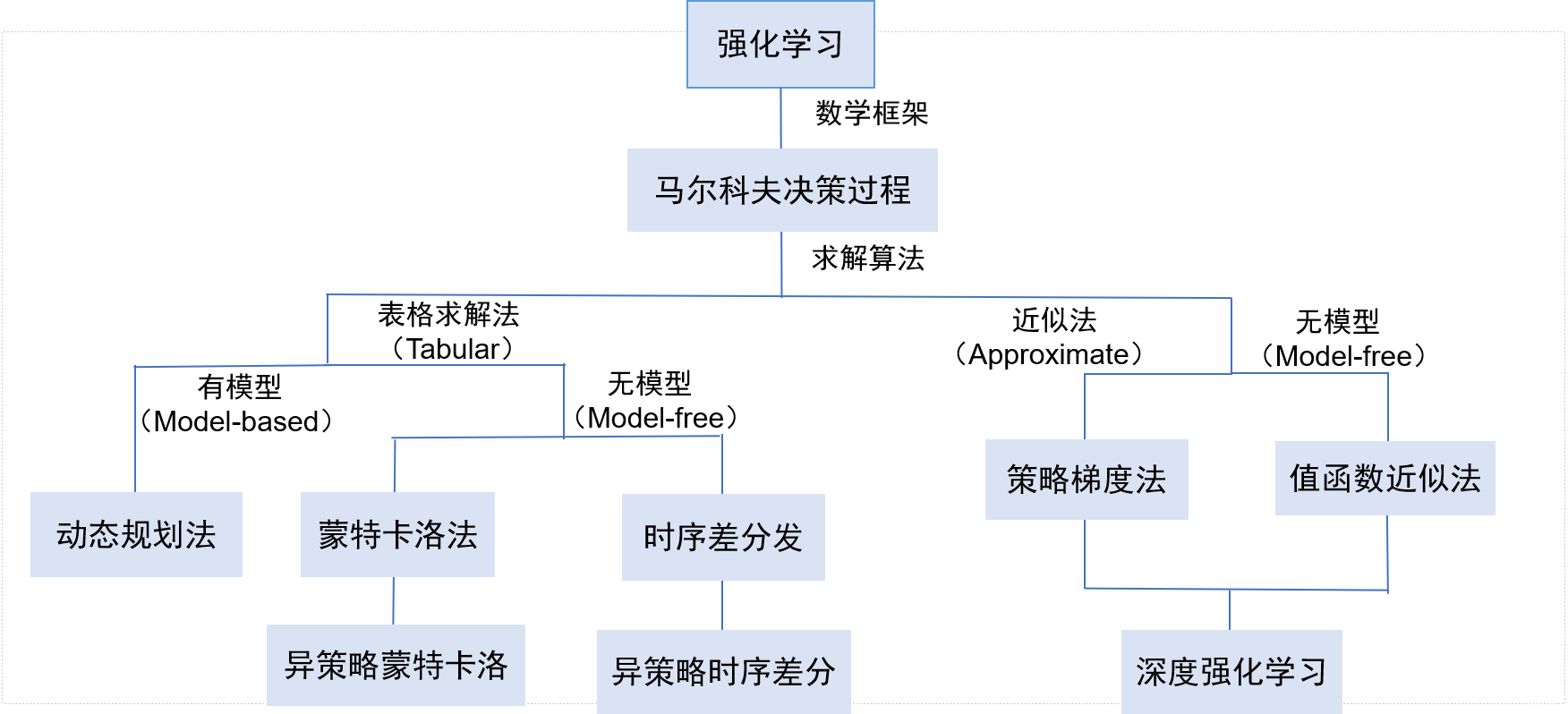
强化学习
2024/4/11 18:02:45
文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback 1. 文章简介2. 方法介绍 1. 整体方法说明 3. 实验结果 1. RLHF vs RLAIF2. Prompt的影响3. Self-Consistency4. Labeler Size的影响5. 标注数据的影响 4. 总结 & 思考 文…

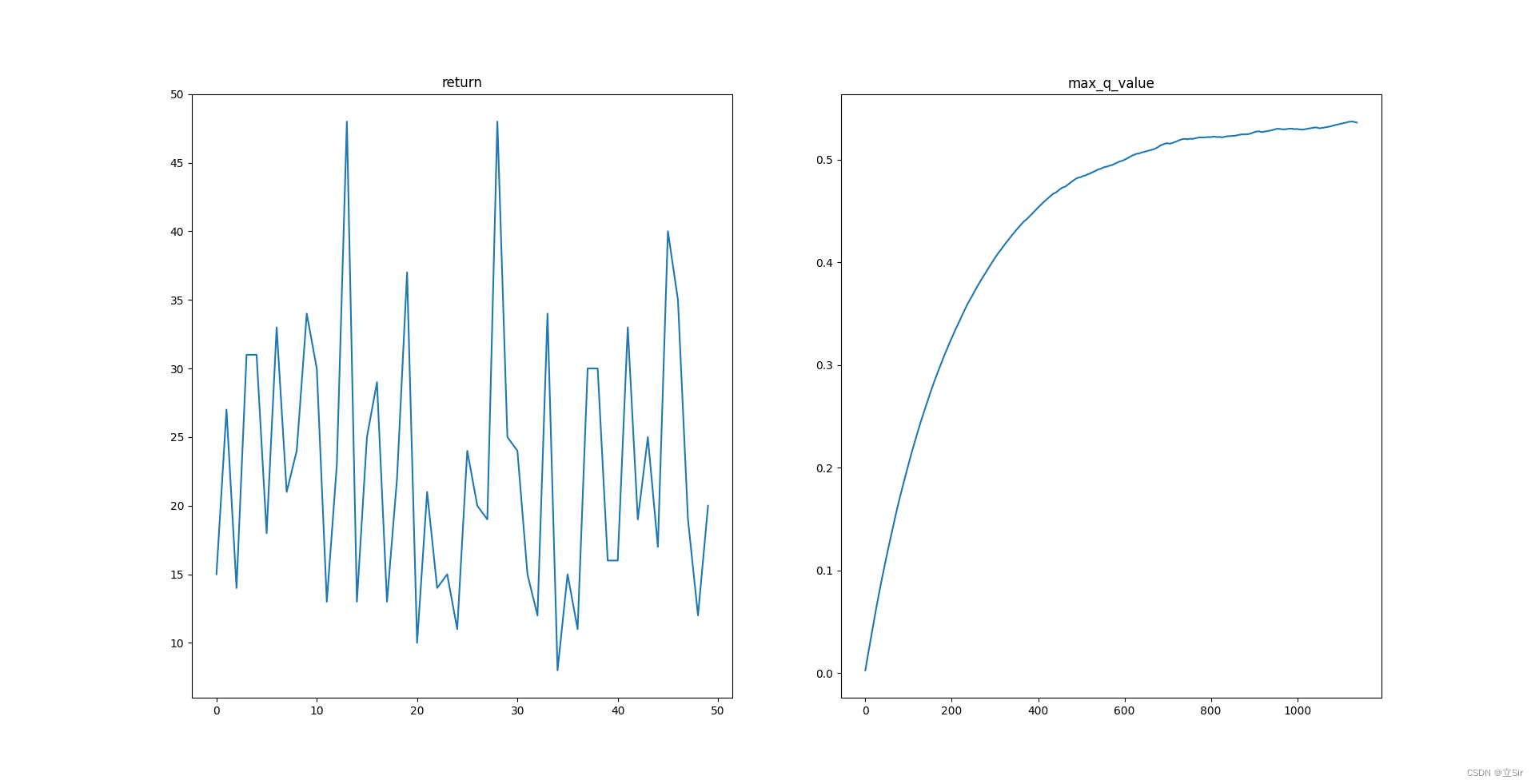
【深入浅出强化学习-编程实战】 7 基于策略梯度的强化学习-Cartpole(小车倒立摆系统)
【深入浅出强化学习-编程实战】 7 基于策略梯度的强化学习-Cartpole小车倒立摆MDP模型代码代码解析小车倒立摆MDP模型
状态输入:s[x,x˙,θ,θ˙]s [x,\dot{x},\theta,\dot{\theta}]s[x,x˙,θ,θ˙],维数为4动作输出为a{[1,0],[0,1]}a \{[1,0],[0,1]…

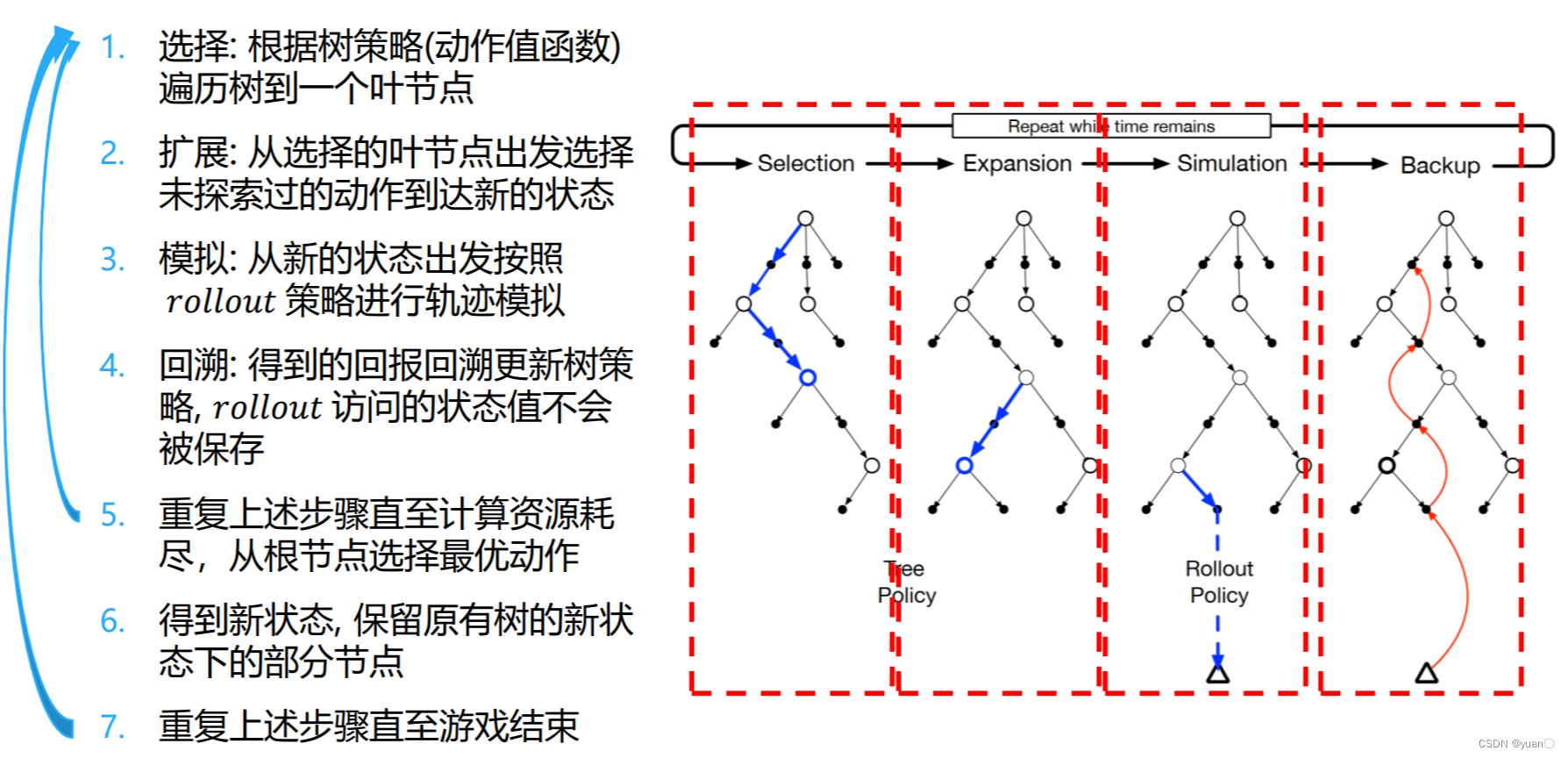
算法学习(三)——蒙特卡洛树搜索
四个阶段:
选择,展开,模拟,反传
关键公式:
信任度上限树(Upper Confidence bound applied to Trees(UCT))
参考文章:
https://zhuanlan.zhihu.com/p/25345778
参考代码:
https://github.…

【强化学习-医疗】用于临床决策支持的深度强化学习:简要综述
Article
作者:Siqi Liu, Kee Yuan Ngiam, Mengling Feng文献题目:用于临床决策支持的深度强化学习:简要综述文献时间:2019文献链接:https://arxiv.org/abs/1907.09475
摘要
由于人工智能尤其是深度学习的最新进展&a…

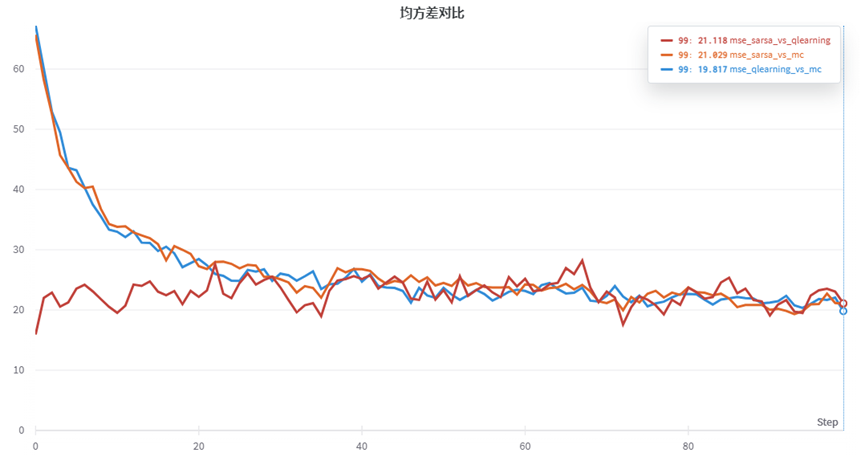
【深入浅出强化学习-编程实战】4 基于时间差分的方法-鸳鸯系统
【深入浅出强化学习-编程实战】4 基于时间差分的方法4.1 鸳鸯系统——基于时间差分的方法4.2 Sarsa结果4.3 Q-learning结果4.1 鸳鸯系统——基于时间差分的方法
左上为雄鸟,右上为雌鸟,中间有两道障碍物。目标:雄鸟找到雌鸟。 yuanyang_env_…

Ubuntu16.04 安装ROS Kinetic
参考网址:https://blog.csdn.net/qq_40936141/article/details/86241910
记录一下安装过程 Ubuntu16.04 安装ROS Kinetic一、 安装ROS1、添加ROS软件源2、添加密钥3、更新软件包4、安装ROS Kinetic5、初始化ROSrosdep init ROS安装问题解决方案6、安装rosinstall二…

AI玩Flappy Bird│基于DQN的机器学习实例【完结】
前言
Flappy Bird简介
《Flappy Bird》是一款由来自越南的独立游戏开发者Dong Nguyen所开发的作品,游戏于2013年5月24日上线,并在2014年2月突然暴红。2014年2月,《Flappy Bird》被开发者本人从苹果及谷歌应用商店撤下。2014年8月份正式回归…
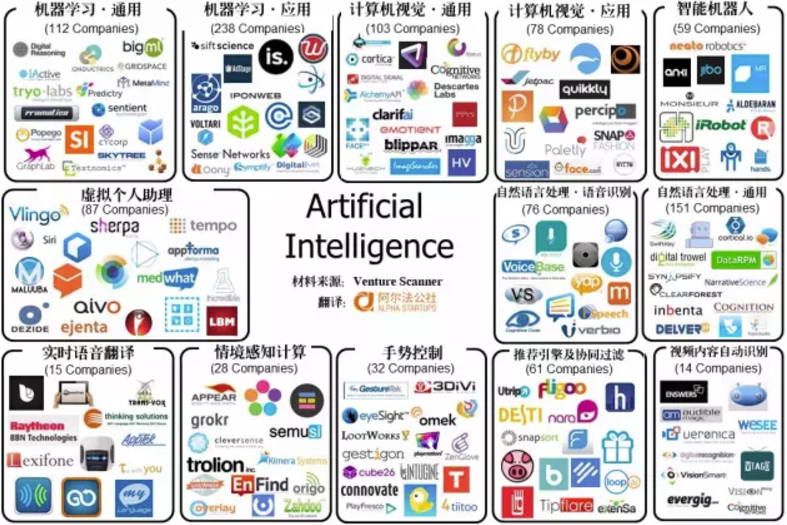
深度学习的研究方向和发展趋势
一. 人工智能应用领域1. 计算机视觉生物特征识别:人脸识别、步态识别、行人ReID、瞳孔识别;图像处理:分类标注、以图搜图、场景分割、车辆车牌、OCR、AR;视频分析:安防监控、智慧城市;2. 自然语言处理语音识…
q-learning强化学习使用基础
强化学习
通过策略的方式来学习,q-learing(马尔科夫链模型)
马尔科夫链:奖励*折扣因子,R(t)reward(1)yR(t1),马尔可夫链多次迭代后分布趋于稳定所以可以得到最优解
q-learning
构建qtable,二…
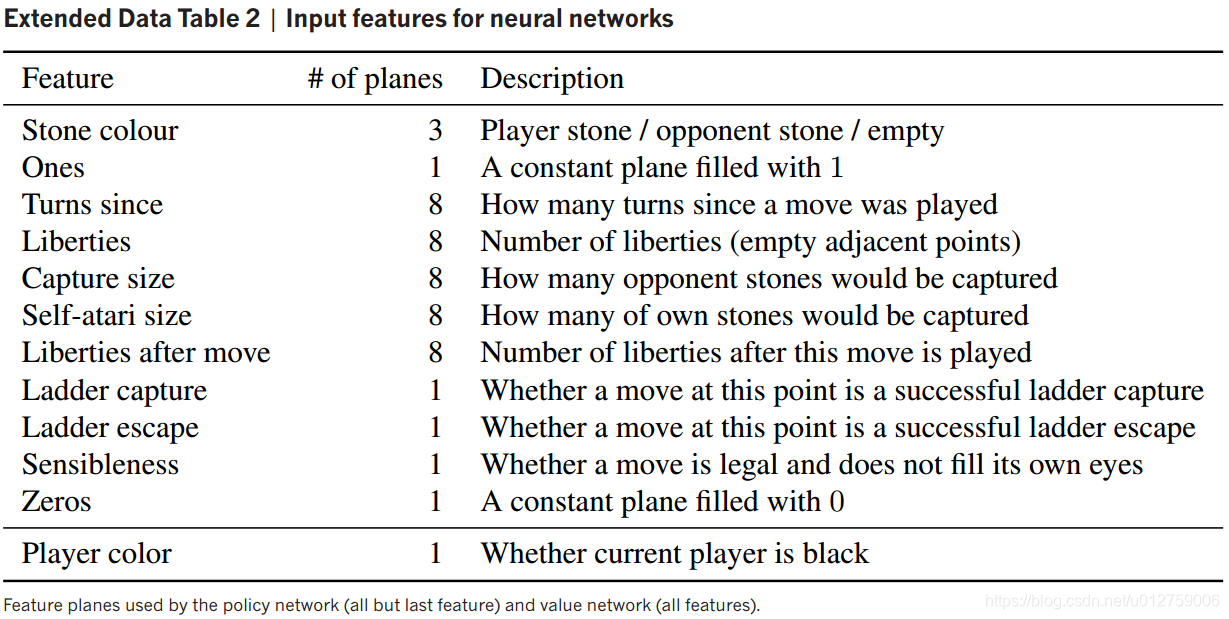
通过深度神经网络和树搜索掌握围棋游戏
Article
作者:David Silver*, Aja Huang*, Chris J. Maddison etc. 文献题目:通过深度神经网络和树搜索掌握围棋游戏 文献时间:2016 发表期刊:nature https://github.com/jmgilmer/GoCNN
摘要 由于其巨大的搜索空间和评估棋盘位…

【深入浅出强化学习-编程实战】6 基于函数逼近的方法-flappy bird
【深入浅出强化学习-编程实战】6 基于函数逼近的方法-flappy bird6.2.1 代码6.2.2 代码解析玩家通过控制小鸟上下运动躲避不断到来的柱子,有两个动作可选:一个是飞,一个是不进行任何操作。采用动作飞时,小鸟会向上飞;不…

【深入浅出强化学习-编程实战】3 基于蒙特卡洛的方法的鸳鸯系统
【深入浅出强化学习-编程实战】3 基于蒙特卡洛的方法3.1 鸳鸯系统——基于蒙特卡洛的方法3.2 部分代码思考3.1 鸳鸯系统——基于蒙特卡洛的方法
左上为雄鸟,右上为雌鸟,中间有两道障碍物。目标:雄鸟找到雌鸟。
在模型已知的时候,…

【推荐系统论文阅读】基于强化学习的推荐模拟用户反馈
Article
作者:Xiangyu Zhao, Long Xia, Lixin Zou, Dawei Yin, Jiliang Tang文献题目:基于强化学习的推荐模拟用户反馈文献时间:2019文献链接:https://arxiv.org/abs/1906.11462
摘要
随着强化学习 (RL) 的最新进展,…
【知识图谱论文】DIVINE:用于知识图推理的生成对抗模仿学习框架
Article
文献题目:DIVINE: A Generative Adversarial Imitation Learning Framework for Knowledge Graph Reasoning 文献时间:2019 发表期刊:EMNLP
摘要
知识图谱(KGs)经常遭受稀疏和不完整的困扰。知识图谱推理为…

【深入浅出强化学习-编程实战】 7 基于策略梯度的强化学习-Pendulum(单摆系统)
【深入浅出强化学习-编程实战】 7 基于策略梯度的强化学习-PendulumPendulum单摆系统MDP模型代码代码学习Pendulum单摆系统MDP模型
该系统只包含一个摆杆,其中摆杆可以绕着一端的轴线摆动,在轴线施加力矩τ\tauτ来控制摆杆摆动。Pendulum目标是&#x…
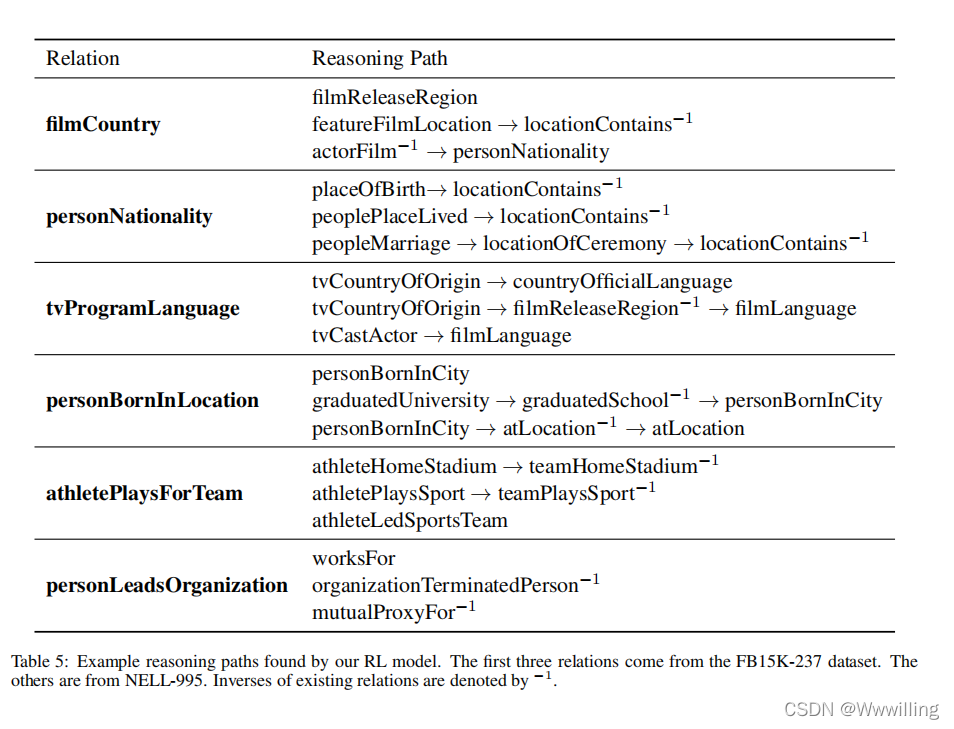
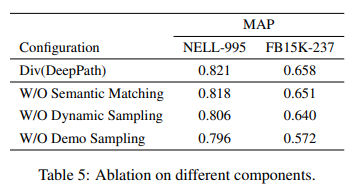
DeepPath:一种知识图推理的强化学习方法
Article
作者:Wenhan Xiong and Thien Hoang and William Yang Wang 文献题目:DeepPath:一种知识图推理的强化学习方法 文献时间:2017 https://github.com/xwhan/DeepPath.
摘要
研究了在大规模知识图中学习推理的问题。更具体…

【强化学习纲要】5 策略优化基础
【强化学习纲要】5 策略优化基础5.1 基于策略优化的强化学习5.1.1 Value-based RL versus Policy-based RL5.1.2 Two types of Policies5.1.3 优化策略的客观函数5.1.4 直接计算policy gradient5.2 Monte-Carlo policy gradient5.2.1 Policy Gradient for One-Step MDPs5.2.2 P…

【医疗人工智能】DKDR:一种用于疾病诊断的知识图谱和深度强化学习方法
Article
作者:Yuanyuan Jia, Zhiren Tan, Junxing Zhang文献题目:DKDR: An Approach of Knowledge Graph and Deep Reinforcement Learning for Disease Diagnosis文献时间:2019
摘要
使用人工智能解决医疗问题一直是一个有趣但具有挑战性…

【强化学习纲要】8 模仿学习
【强化学习纲要】8 模仿学习8.1 模仿学习概要8.2 Behavioral cloning and DAGGER8.3 Inverse RL and GAIL8.4 进一步改进模仿学习的模型8.5 模仿学习和强化学习结合8.6 Case studies周博磊《强化学习纲要》学习笔记课程资料参见:
https://github.com/zhoubolei/intr…

【强化学习】常用算法之一 “SAC”
作者主页:爱笑的男孩。的博客_CSDN博客-深度学习,活动,python领域博主爱笑的男孩。擅长深度学习,活动,python,等方面的知识,爱笑的男孩。关注算法,python,计算机视觉,图像处理,深度学习,pytorch,神经网络,opencv领域.https://blog.csdn.net/Code_and516?typeblog个…

5328笔记 Advanced ML Chapter10-Reinforcement Learning
最大化 Expected cumulative reward 期望累计奖励 Q(s0,a0)表示:当状态为s0,做a0的动作,期望累计奖励是Q。 如果我们有n个action,m个state,理论上我们将有nm的Q值。笛卡尔积。 这个表就是Q table。 Q就是在初始…
卧槽!AI,感受被『分手厨房』支配的恐惧...
鱼羊 发自 凹非寺 量子位 报道 | 公众号 QbitAI盆友,你感受过被分手厨房,啊不,《煮糊了》(Overcooked)支配的恐惧吗?其实,别说是你,就是AI们碰上需要多人配合,又得切菜&a…
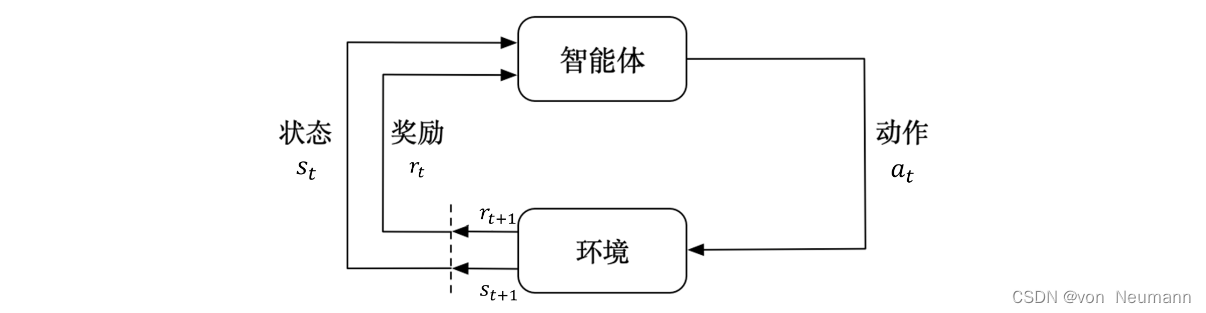
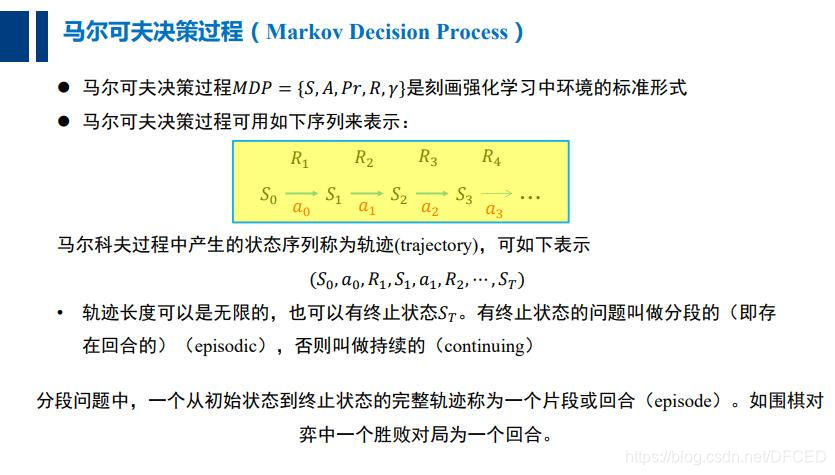
深入理解强化学习——马尔可夫决策过程:随机过程和马尔可夫性质
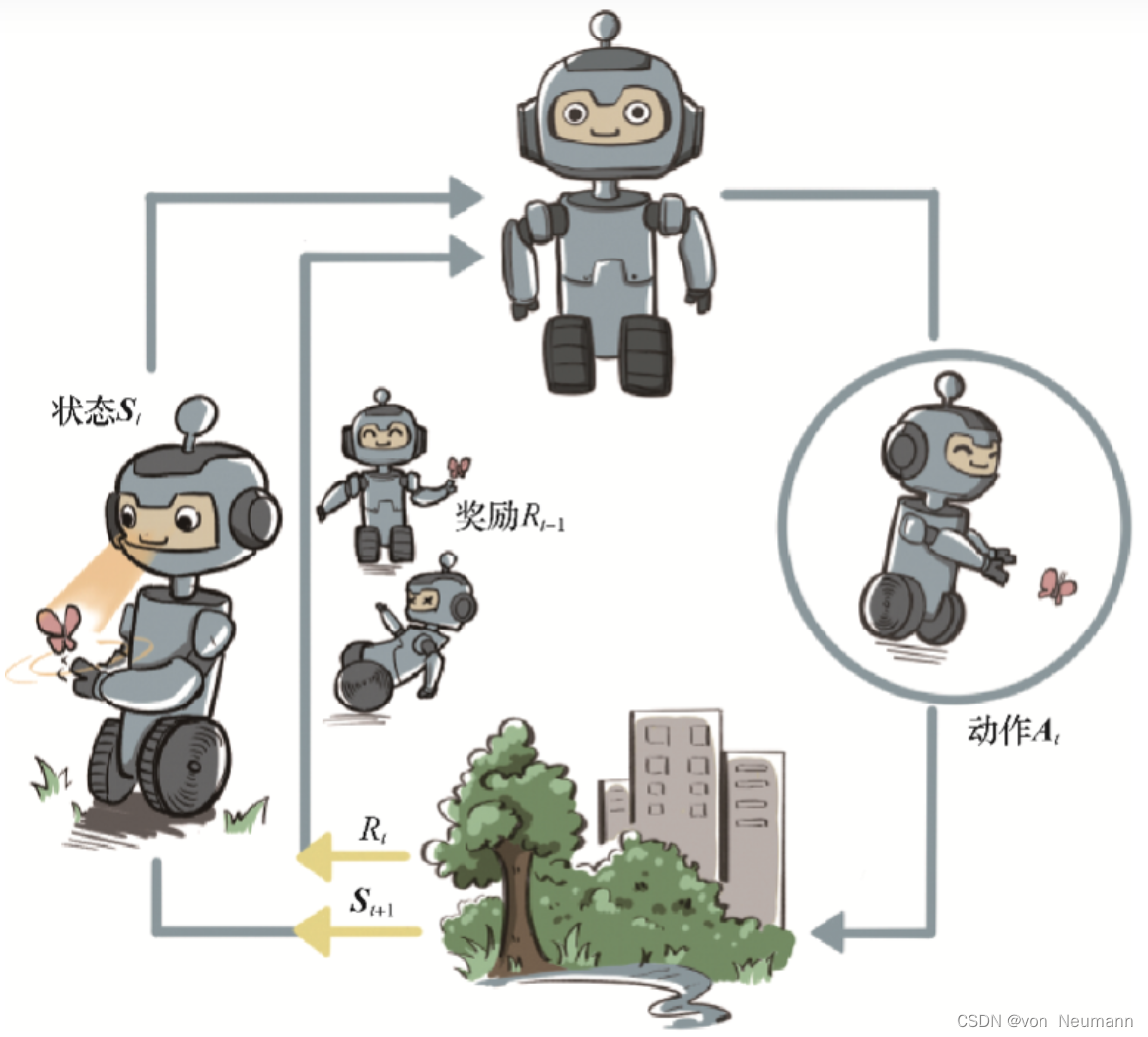
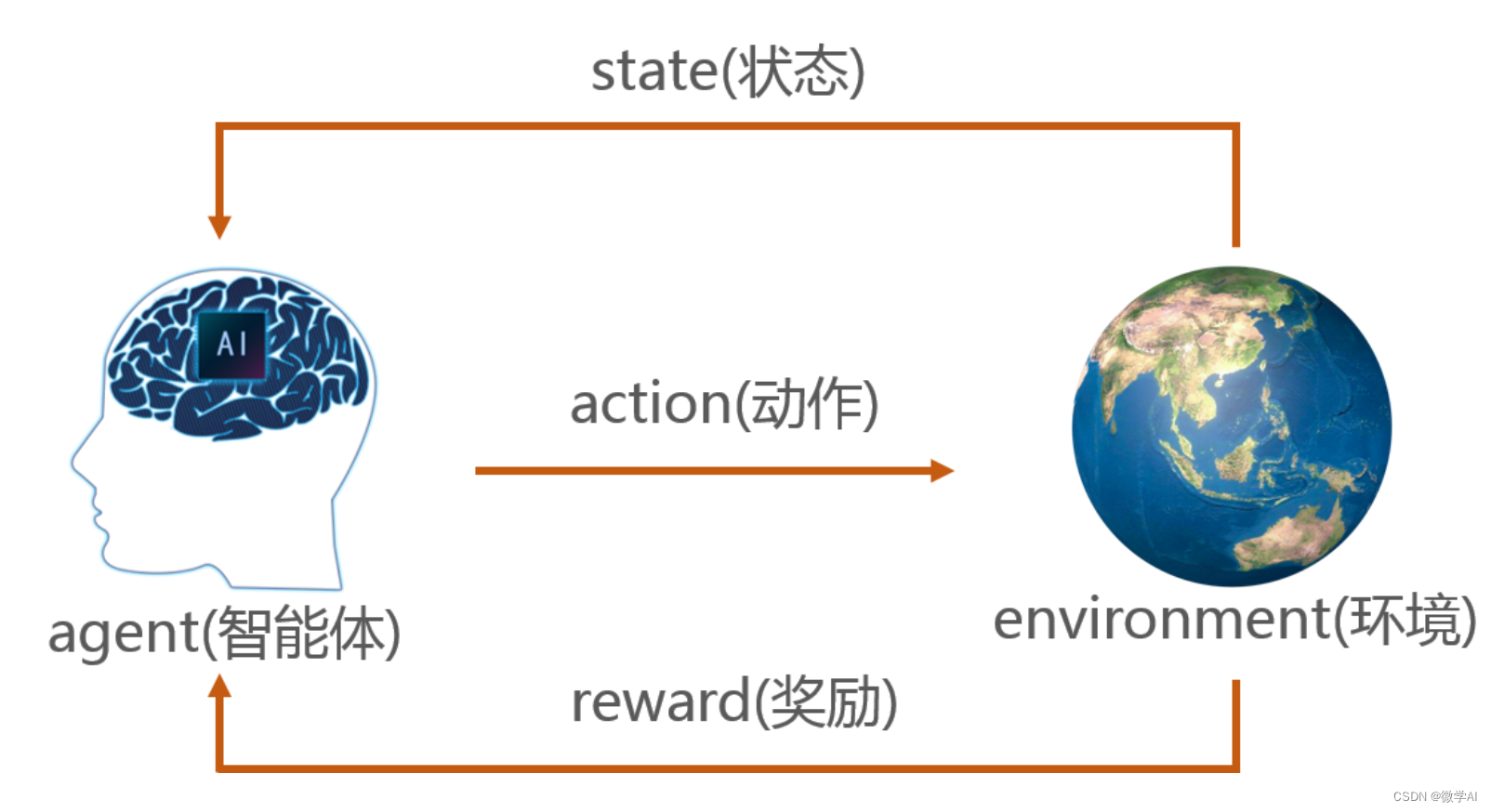
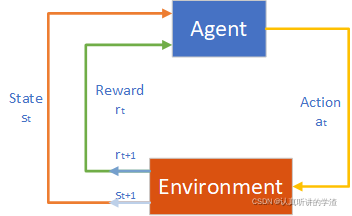
分类目录:《深入理解强化学习》总目录 下图介绍了强化学习里面智能体与环境之间的交互,智能体得到环境的状态后,它会采取动作,并把这个采取的动作返还给环境。环境得到智能体的动作后,它会进入下一个状态,把…

An Casual Overview of Reinforcement Learning
[update 20200712]
OpenAI的网站是很好的reference:spinningup Plan
看完李宏毅RL视频开始one by one implementation,based on openai tipsAt the mean time, master pytorch/tf and deep learning basics.When have time, keep an eye on the resear…
OpenAI Gym入门与实操(1)
本文参考:
OpenAI-Gym入门 - 知乎,
【强化学习】 OpenAI Gym入门:基础组件(Getting Started With OpenAI Gym: The Basic Building Blocks)_iioSnail的博客-CSDN博客
特此致谢。 1. 简介
OpenAI Gym是强化学习&…
深入理解强化学习——动作空间(Action Space)
分类目录:《深入理解强化学习》总目录 不同的环境允许不同种类的动作。在给定的环境中,有效动作的集合经常被称为动作空间(Action Space)。像雅达利游戏和围棋(Go)这样的环境有离散动作空间(Dis…

【强化学习】基础概念
1. Agent (智能体)
智能体是进行决策和学习的实体,它能感知环境的状态,并基于策略采取动作以影响环境。智能体的目标是通过与环境的交互获得最大化的累积奖励。
2. Environment (环境)
环境是智能体所处的外部系统,它与智能体交互。环境的…

【深入浅出强化学习-原理入门】1 基于gym的MDP(作业)
题目:基于gym构建如下迷宫世界: 全部代码:
maze_mdp.py
import logging #日志模块
import numpy
import random
from gym import spaces
import gymlogging logging.getLogger(__name__)# Set this in SOME subclasses
class MazeEnv(gym…

【强化学习纲要】7 基于环境模型的RL方法
【强化学习纲要】7 基于环境模型的RL方法7.1 基于环境模型强化学习概要7.2 基于环境模型的价值函数优化7.3 基于环境模型的策略函数优化7.4 在机器人领域的应用周博磊《强化学习纲要》学习笔记课程资料参见:
https://github.com/zhoubolei/introRL.教材:…
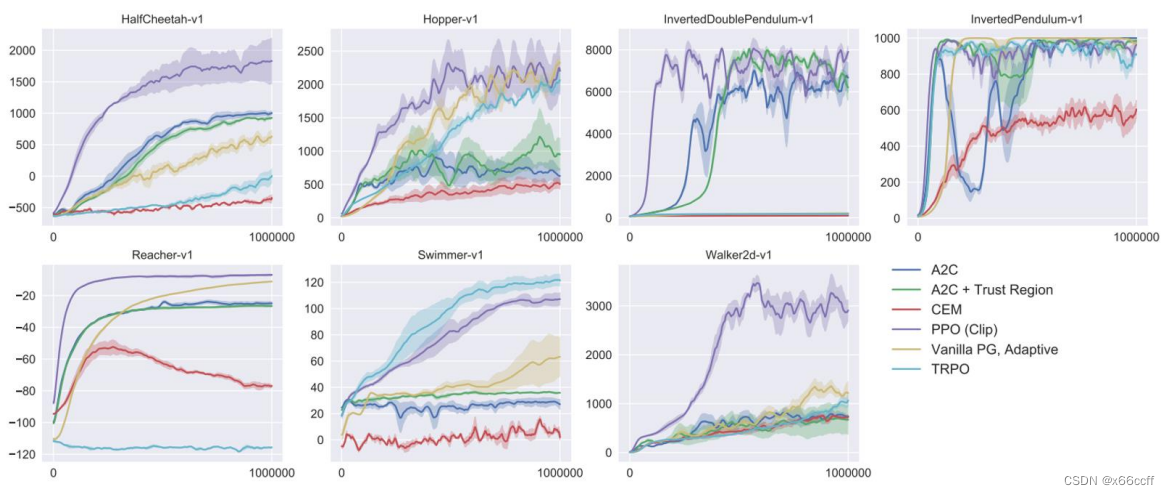
强化学习(9):TRPO、PPO以及DPPO算法
本文主要讲解有关 TRPO算法、PPO 算法、PPO2算法以及 DPPO 算法的相关内容。 一、PPO 算法
PPO(Proximal Policy Optimization) 是一种解决 PG 算法中学习率不好确定的问题的算法,因为如果学习率过大,则学出来的策略不易收敛&…
强化学习(7):深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)
本文主要讲解有关 DDPG 算法的有关内容。 一、DDPG 算法
DDPG 是 Deep Deterministic Policy Gradient 的缩写,其中深度 (Deep) 代表 DQN;确定性(Deterministic)是指不再先生成各个动作的概率然后再选择概…

死侍在新片中,扮演了一个 AI 驱动的 NPC
最近在北美和中国上映了一部以电子游戏为创作背景的电影《Free Guy》(中文片名译作《失控玩家》),由《死侍》的扮演者瑞安雷诺茨主演。 全片轻松搞笑,特效精致,暑期档里表现亮眼,全球收获了不错的票房成绩和…
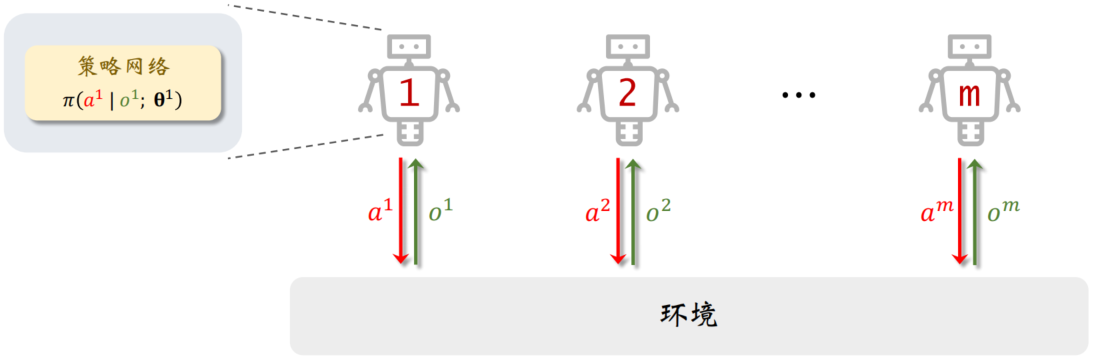
一文了解【完全合作关系】下的【多智能体强化学习】
处于完全合作关系的多智能体的利益一致,获得的奖励相同,有共同的目标。比如多个工业机器人协同装配汽车,他们的目标是相同的,都希望把汽车装好。
在多智能体系统中,一个智能体未必能观测到全局状态 S。设第 i 号智能体…

潘玲:读博是一场苦亦乐的旅程
By 超神经内容描述:在刚刚结束的 IJCAI-SAIA YES 上,我们邀请了几位青年学者与教师进行了采访,聊聊他们的学术历程。以下是对清华大学交叉信息研究院潘玲的采访整理。关键词:直博学神 强化学习 清华大学 在本届 IJCAI-SAIA YES 大…
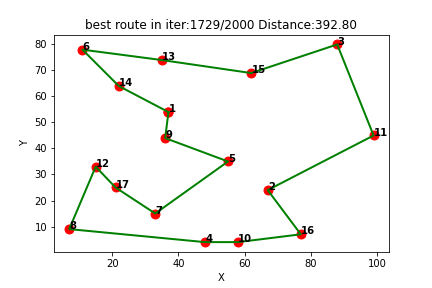
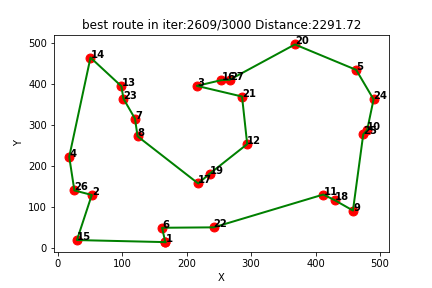
强化学习求解TSP(八):Qlearning求解旅行商问题TSP(提供Python代码)
一、Qlearning简介
Q-learning是一种强化学习算法,用于解决基于奖励的决策问题。它是一种无模型的学习方法,通过与环境的交互来学习最优策略。Q-learning的核心思想是通过学习一个Q值函数来指导决策,该函数表示在给定状态下采取某个动作所获…
ML-Agents与自己的强化学习算法通讯——PPO篇
在上一篇文章ML-Agents与python的Low Level API通信中,我简要介绍了Python与Unity端的ML-Agents插件的通讯代码,如何正确运行一个能够进行强化学习训练的Unity环境,并获取到响应的信息,接下来将介绍如何利用自己的强化学习算法进行…
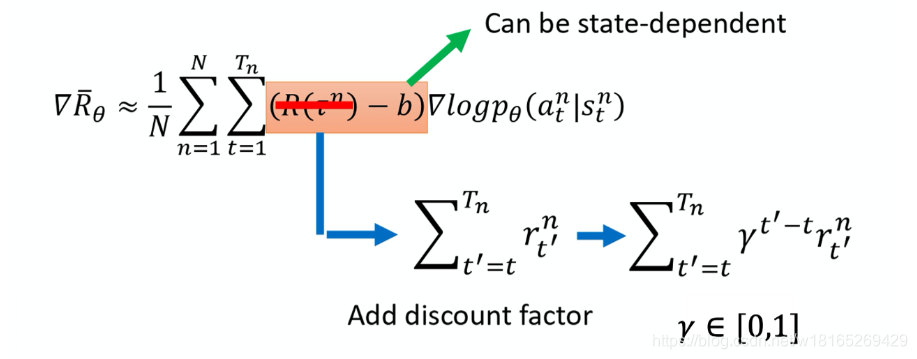
强化学习笔记------第四章----策略梯度(超详细)
Policy Gradient 在强化学习中有3个组成部分:演员(actor)、环境(environment)和奖励函数(reward function)
在强化学习中,环境跟奖励函数不是你可以控制的,环境跟奖励函数是在开始学习之前,就已经事先给定的。唯一能做的就是调整…
Python-L1和L2正则化
1.L1和L2正则化
L1 正则化和 L2 正则化是在神经网络中常用的两种正则化技术,用于对权重参数进行惩罚,以减小过拟合现象。它们有以下联系和区别:
联系:
①L1 正则化和 L2 正则化都是在训练神经网络时添加到损失函数中的额外项&a…
![强化学习从基础到进阶-常见问题和面试必知必答[5]::梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
强化学习从基础到进阶-常见问题和面试必知必答[5]::梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)
【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现 专栏详细介绍:【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧…
DQN(Deep Q Network )强化学习
DQN(Deep Q Network )强化学习
强化学习与神经网络
之前我们所谈论到的强化学习方法都是比较传统的方式, 而如今, 随着机器学习在日常生活中的各种应用, 各种机器学习方法也在融汇, 合并, 升级. 而我们今天所要探讨的强化学习则是这么一种融合了神经网…
OpenAI Gym入门与实操(2)
本文内容参考:
Getting Started With OpenAI Gym | Paperspace Blog,
【强化学习】 OpenAI Gym入门:基础组件(Getting Started With OpenAI Gym: The Basic Building Blocks)_iioSnail的博客-CSDN博客 3. 环境&#…
深入理解强化学习——多臂赌博机:动作一价值方法
分类目录:《深入理解强化学习》总目录 本文我们来详细分析估计动作的价值的算法。我们使用这些价值的估计来进行动作的选择,这一类方法被统称为“动作一价值方法"。如前文所述,动作的价值的真实值是选择这个动作时的期望收益。因此&…

强化学习note1导论
Textbook:Sutton and Barton reinforcement learning
周博磊老师中文课
coding
架构:Pytorch 与supervised learning 的区别:监督学习:1.假设数据之间无关联i.i.d. 2.有label 强化学习:不一定i.i.d;没有立刻feed back(delay reward)
exploration(采取新行为)&exploi…

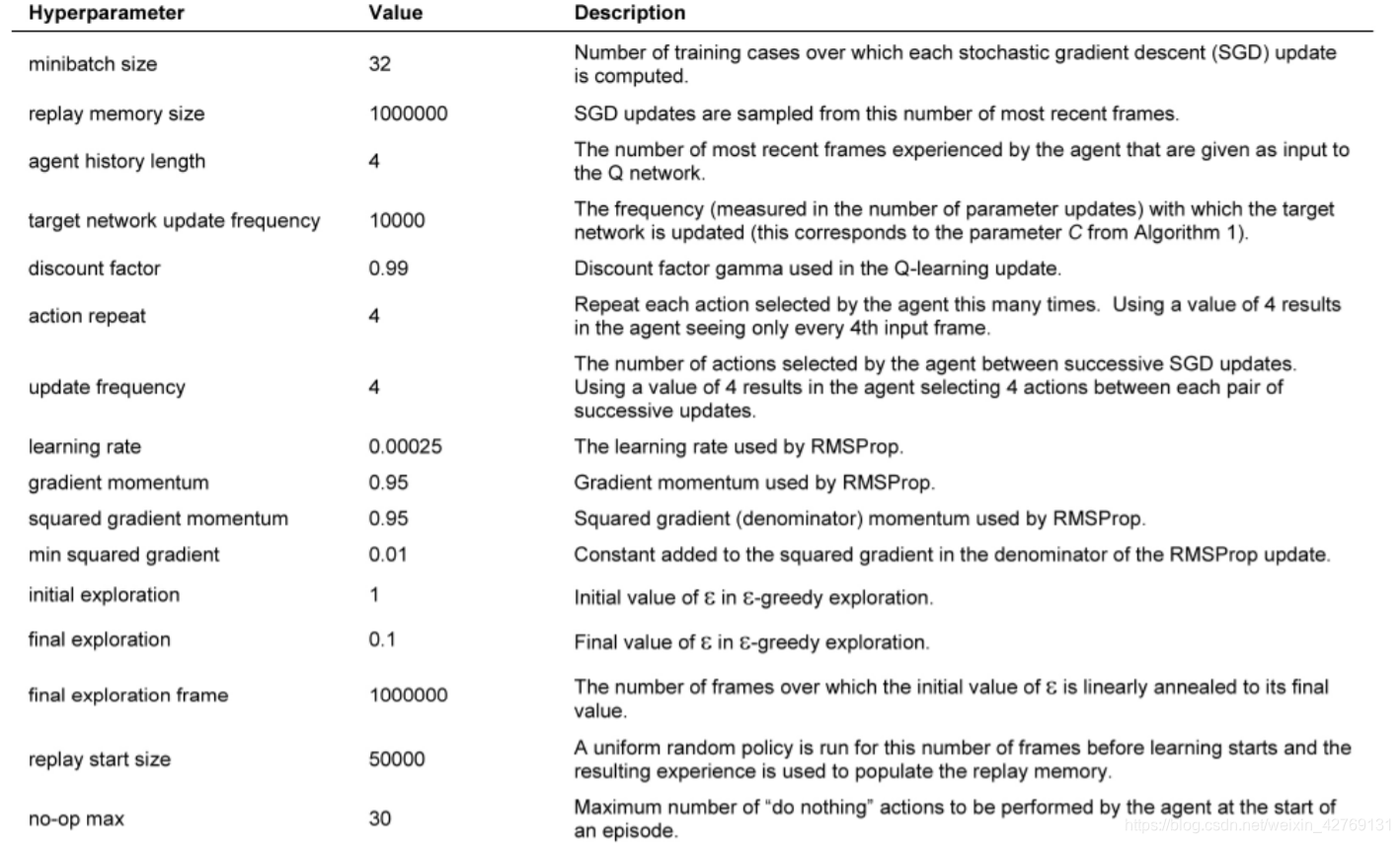
强化学习论文研读(二)——Playing Atari with Deep Reinforcement Learning
DQN系列算法的开山之作,这里的dqn通常称为NIPS-DQN,后来还有nature-DQN,更加好用。
论文的一些理解
Q-Learning的伪代码: NIPS-DQN的伪代码: 有以下几个关键点:
一是图像的处理: 将图像压缩成…
算法学习(十)——强化学习中的奖励设置(不完整)
强化学习中奖励函数的设置非常复杂,这里只是总结一下我的理解。
1.收益信号只能用来传达什么是你想要实现的目标,而不是如何实现現这个目标。所以不应该把奖励设置的过于细致。
2.使用惩罚项可能导致智能体一动不动,因为不动就不会有惩罚。…
【强化学习入门】深度强化学习DRL入门学习资料
文章目录1.顶会目录2.视频教程3.交流社区4.开源项目1.顶会目录 AAAI(AAAI Conference on Artificial Intelligence, AAAI),地址:http://dblp.uni-trier.de/db/conf/aaai/ IJCAI(International Joint Conference on Ar…
深度学习实战62-强化学习在简单游戏领域的应用,利用强化学习训练Agent程序的代码和步骤
大家好,我是微学AI,今天给大家介绍一下深度学习实战62-强化学习在简单游戏领域的应用,利用强化学习训练Agent程序的代码和步骤。本文介绍了如何利用强化学习构建智能体程序,而无需使用启发式算法。通过玩游戏并尝试最大化获胜率,我们可以逐渐完善Agent程序的策略。强化学习…
强化学习和torchrl
torchrl是一个基于pytorch的强化学习库,我发现根据torchrl的结构可以对强化学习知识点有更加深入的理解,下面将我的理解记录如下:
torchrl中将强化学习的过程分为了几个部分:
环境,需要实现reset, step两个方法repla…

深入理解强化学习——标准强化学习和深度强化学习
分类目录:《深入理解强化学习》总目录 强化学习的历史
早期的强化学习,我们称其为标准强化学习。最近业界把强化学习与深度学习结合起来,就形成了深度强化学习(Deep ReinforcemetLearning)。因此,深度强化…
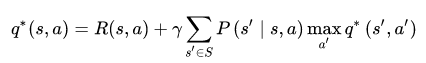
浅谈马尔可夫决策过程(一)
1.基本概念 Markov Chain/Markov process:具有马尔可夫性质的随机过程。 Markov Property用公式表示为: P(st1 | st, st-1, …) P(st1 | st)。简单说就是当前时刻的状态仅仅和上一个时刻的状态有关。这个性质感觉更多的是从工程上考虑问题得出的,因为这样可以极大的…
深入理解强化学习——强化学习智能体的四要素:价值函数(Value Function)
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习智能体的四要素:策略(Policy) 强化学习智能体的四要素:收益信号(Revenue Signal) 强化学习智能体的四要素:价…
强化学习-PolicyGradient相关推导和记录
首先定义强化学习的目标:maximizeJ(πθ)Eτ∼πθ[R(τ)]maximize J(\pi_\theta)E_{\tau \sim \pi_\theta}[R(\tau)]maximizeJ(πθ)Eτ∼πθ[R(τ)]也就是找到一个策略可以最大化累计奖励。其中是πθ\pi_\thetaπθ用θ\thetaθ参数化的策略。
那么策略梯度的目标…
算法学习(四)——alphago模型
模型推荐看原文:
https://xueshu.baidu.com/usercenter/paper/show?paperida7600bdc74f5a07ed65256035cd15c6b&sitexueshu_se
自己的理解:
MCTS解决的是算力分配的问题,alphago主要解决了五个问题:
一是把深度学习和蒙特…
wzx-jmw:NFL合理,但可能被颠覆。2023-2024
As well known by all, NFL is ...
没有免费的午餐理论 No Free Lunch Theorem_免费午餐理论-CSDN博客
However, if we...

【强化学习-医疗】医疗保健中的强化学习:综述
Article
作者:Chao Yu, Jiming Liu, Shamim Nemati文献题目:医疗保健中的强化学习:综述文献时间:2020文献链接:https://arxiv.org/abs/1908.08796
摘要
作为机器学习的一个子领域,强化学习 (RL) 旨在通过…

【强化学习文献阅读】DRN:新闻推荐的深度强化学习框架
Article
作者:Guanjie Zheng, Fuzheng Zhang, Zihan Zheng, Yang Xiang, Nicholas Jing Yuan, Xing Xie, Zhenhui Li文献题目:DRN:新闻推荐的深度强化学习框架文献时间:2018文献链接:http://www.personal.psu.edu/~gj…

【深入浅出强化学习-编程实战】6 基于函数逼近的方法-鸳鸯系统
【深入浅出强化学习-编程实战】6 基于函数逼近的方法-鸳鸯系统6.1 鸳鸯系统——基于函数逼近的方法基于表格表征表示基于固定稀疏表示代码困惑6.1 鸳鸯系统——基于函数逼近的方法
左上为雄鸟,右上为雌鸟,中间有两道障碍物。目标:雄鸟找到雌…

强化学习DQN 入门小游戏 最简单的Pytorch代码
本文目的是用最简单的代码,展示DQN玩游戏的效果,不涉及深度学习原理讲解。
毕竟,入门如此艰难,唯一的动力不过是看个效果,装个biu……
安装OpenAI的游戏库gym
pip install gym看一下运行效果
import gymenv gym.m…
深入理解强化学习——学习(Learning)、规划(Planning)、探索(Exploration)和利用(Exploitation)
分类目录:《深入理解强化学习》总目录 学习
学习(Learning)和规划(Planning)是序列决策的两个基本问题。 如下图所示,在强化学习中,环境初始时是未知的,智能体不知道环境如何工作&a…

【强化学习】Q-Learning 案例分析
前期知识可查看: 【强化学习】相关基本概念【强化学习】 Q-Learning案例介绍
寻路案例:(强烈建议学习上述前期知识里的【强化学习】 Q-Learning 尤其是看懂前面的小案例)
红色为可移动的寻路个体黑色为惩罚位置【奖励 -1】黄色为…

DQN原理及PyTorch实现【强化学习】
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 欢迎来到我们的强化学习系列的第三部分。 在上两篇博客中,我们介绍了强化学习中…

【强化学习】07——规划与学习(Dyna-Q)
文章目录 前置知识回顾策略值函数估计(Policy Evaluation)策略提升(Policy Improvement) 模型(Model)规划(Planning)规划与学习(Planning and Learning)Dyna (集成规划、决策和学习)Dyna的框架D…
强化学习求解TSP(三):Qlearning求解旅行商问题TSP(提供Python代码)
一、Qlearning简介
Q-learning是一种强化学习算法,用于解决基于奖励的决策问题。它是一种无模型的学习方法,通过与环境的交互来学习最优策略。Q-learning的核心思想是通过学习一个Q值函数来指导决策,该函数表示在给定状态下采取某个动作所获…

带有action mask动作掩码的PPO算法(附代码实现)
Actor神经网络输出的动作概率是全部动作的概率,而在应用PPO算法解决实际问题的时候,经常会遇到动作action受到限制的情形,也就是部分动作action是合理的,智能体动作采样select_action的时候也就只能从那些合理的动作action集合中采…
21.在线与离线MC强化学习简介
文章目录 1. 什么是在线MC强化学习2. 什么是离线MC强化学习3. 在线MC强化学习有何缺点 1. 什么是在线MC强化学习
在线强化学习(on-policy MC RL),是指:智能体在策略评估时为获取完整轨迹所采用的采样策略 π s a m p l e ( a ∣ …
Python-DQN和Dueling Network代码对比阅读(15)-model.py
1.文件修改
Dueling Network和DDQN都是三个文件,funcs.py、model.py和dueling.py或者ddpn.py。
对于funcs.py,其以前用于DDQN,所以再次使用。dueling.py代码也与ddpn.py相同(只是重命名)。因此,只需更改m…
![强化学习从基础到进阶-案例与实践[4]:深度Q网络-DQN、double DQN、经验回放、rainbow、分布式DQN](../img/ch8/8.3.png)
强化学习从基础到进阶-案例与实践[4]:深度Q网络-DQN、double DQN、经验回放、rainbow、分布式DQN
【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现 专栏详细介绍:【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧…
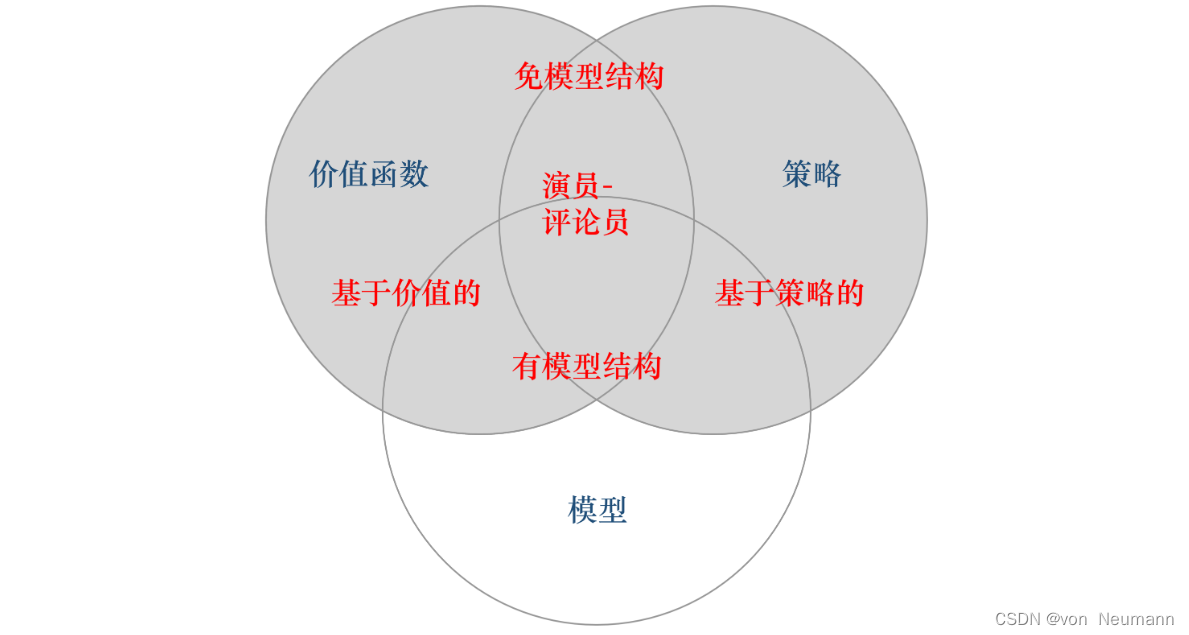
深入理解强化学习——智能体的类型:有模型强化学习智能体与免模型强化学习智能体
分类目录:《深入理解强化学习》总目录 根据智能体学习的事物不同,我们可以把智能体进行归类。基于价值的智能体(Value-based agent)显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。…
pycharm出现gym.error.DeprecatedEnv: Env Pendulum-v0 not found (valid versions include [‘Pendulum-v1‘])
问题
使用gym包的时候,遇到了下面这样的问题:找不到对应的版本。 for external in metadata.entry_points().get(self.group, []):
Traceback (most recent call last):File "E:\Soft\miniconda\envs\py\lib\site-packages\gym\envs\registration.…

PRCV 2023 - Day3
主会场——主旨报告 报告题目:变与不变:有关大模型的一些数理基础问题
讲者:徐宗本(中国科学院院士)
徐宗本院士的演讲首先通过一系列示例阐释了ChatGPT引领了人工智能研究的新浪潮,推动了人工智能从深度…
【ROS无人驾驶系列】1 软件环境基础(ROS CMake) 上
【ROS无人驾驶系列】1 软件环境基础(ROS CMake) 上01 创建ROS的工作空间1.1 创建catkin工作空间1.2 编译工作空间1.3 设置环境变量1.4 检查环境变量02 功能包的创建03 功能包的源代码编写3.1 编写发布器节点(july_say_node.cpp)03…

【强化学习纲要】1 概括与基础
【强化学习纲要】1 概括与基础1.1 课程简介1.2 强化学习介绍1.2.1 简介1.2.2 与监督学习的对比1.3 序列决策过程1.3.1 介绍1.3.2 RL agent组成成分1.3.3 马尔可夫决策过程(MDPs)1.3.4 示例:走迷宫1.3.5 分类1.3.6 探索与开发1.4 RL代码实现1.4.1 Python …

【强化学习纲要】2 马尔科夫决策过程
【强化学习纲要】2 马尔科夫决策过程2.1 MDP2.1.1 马尔科夫链(Markov Chain)2.1.2 马尔科夫奖励过程(MRP)2.1.3 马尔科夫决策过程(MDP)2.2 MDP中的价值函数2.2.1 Bellman expectation equation2.2.3 Backup Diagram for VπV^\piVπ2.2.4 Policy evaluation2.2.5 举…

【强化学习纲要】3 无模型的价值函数估计和控制
【强化学习纲要】3 无模型的价值函数估计和控制3.1 回顾MDP的控制3.2 Model-free prediction3.2.1 Monte Carlo policy evaluation3.2.2 Temporal Difference (TD) learning3.3 Model-free control3.3.1 Sarsa: On-Policy TD Control3.3.2 On-policy Learning vs. Off-policy L…
强化学习(3):Deep Q Network(DQN)算法
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解有关 Deep Q Network(DQN)算法的相关内容。 1. DQN 的基本思想
传统的 Q-Learning 算法当 Q 表过大时不仅…

【强化学习纲要】4 价值函数近似
【强化学习纲要】4 价值函数近似4.1 价值函数近似基本原理4.1.1 Introduction: Scaling up RL4.1.2 梯度下降法4.1.3 线性价值函数近似4.2 价值函数近似for prediction4.2.1 Incremental VFA(价值函数近似) Prediction Algorithms4.2.2 Monte-Carlo Prediction with VFA4.2.3 T…


【深入浅出强化学习-原理入门】2 基于模型的动态规划方法
【深入浅出强化学习-原理入门】2 基于模型的动态规划方法2.1 基于gym的机器人找金币游戏2.1.1 基于策略迭代算法找金币游戏2.1.2 基于值迭代算法找金币游戏2.2 基于gym的迷宫游戏2.2.1 基于策略迭代算法的迷宫游戏2.2.2 基于值迭代算法的迷宫游戏2.1 基于gym的机器人找金币游戏…

【深入浅出强化学习-编程实战】1 多臂赌博机
多臂赌博机: 假设玩家共有N次摇动摇臂的机会,每次怎么选择可以使得最后得到的金币最多? ϵ\epsilonϵ-greedy玻尔兹曼策略UCB策略
# 多臂赌博机
import numpy as np
import matplotlib.pyplot as pltclass KB_Game:def __init__(self,*args,…

【深入浅出强化学习-编程实战】2 马尔可夫决策过程-鸳鸯系统
【深入浅出强化学习-编程实战】2 马尔可夫决策过程2.1 鸳鸯系统马尔可夫决策过程2.1.1 代码展示2.1.2 部分代码解析2.1 鸳鸯系统马尔可夫决策过程
左上为雄鸟,右上为雌鸟,中间有两道障碍物。目标:雄鸟找到雌鸟。
2.1.1 代码展示
main.py
…
强化学习用 Sarsa 算法与 Q-learning 算法实现FrozenLake-v0
基础知识
关于Q-learning 和 Sarsa 算法, 详情参见博客 强化学习(Q-Learning,Sarsa) Sarsa 算法框架为 Q-learning 算法框架为
关于FrozenLake-v0环境介绍, 请参见https://copyfuture.com/blogs-details/20200320113725944awqrghbojzsr9ce…
深入理解强化学习——强化学习的定义
分类目录:《深入理解强化学习》总目录 在机器学习领域,有一类任务和人的选择很相似,即序列决策(Sequential Decision Making)任务。决策和预测任务不同,决策往往会带来“后果”,因此决策者需要为…

【强化学习】15 —— TRPO(Trust Region Policy Optimization)
文章目录 前言TRPO特点策略梯度的优化目标使用重要性采样忽略状态分布的差异约束策略的变化近似求解线性搜索算法伪代码广义优势估计代码实践离散动作空间连续动作空间 参考 前言
之前介绍的基于策略的方法包括策略梯度算法和 Actor-Critic 算法。这些方法虽然简单、直观&…

Q-learning如何与ABC等一些元启发式算法能够结合在一起?
1、出现的问题
Q-learning能和元启发式算法(如ABC、PSO、GA、SSA等)结合在一起,实现工作流调度问题? Q-learning和ABC (Artificial Bee Colony) 等元启发式算法可以结合在一起以解决特定类型的问题。Q-learning是一种强化学习算法…
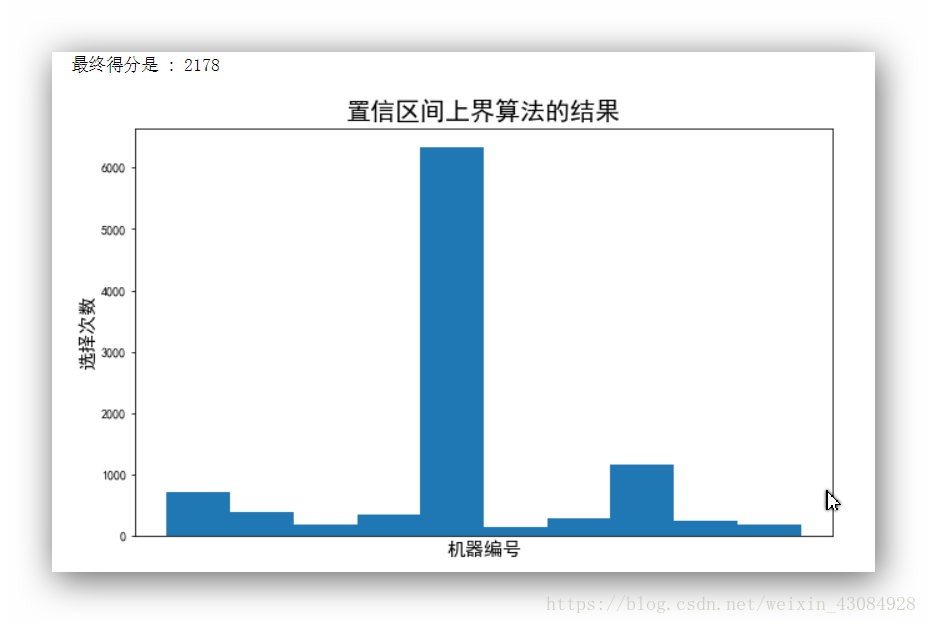
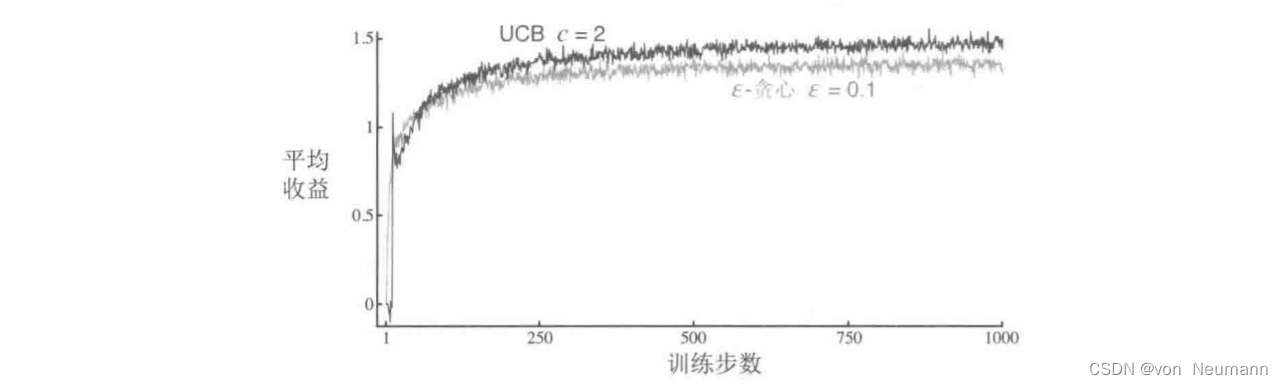
初探强化学习:置信区上界解决多臂老虎机问题
强化学习(英语:Reinforcement learning,简称RL)是机器学习中的一个领域,**强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励…
强化学习专题:回合更新算法
21点(Blackjack) 游戏开始 玩家收到两张明牌,荷官发给自己一张明牌和一张暗牌 根据自己手中的牌和荷官的明牌,玩家需要决定是否要牌(Hit)或停牌(Stand) 选择要牌,荷官发一…

强化学习DQN之俄罗斯方块
强化学习DQN之俄罗斯方块强化学习DQN之俄罗斯方块算法流程文件目录结构模型结构游戏环境训练代码测试代码结果展示强化学习DQN之俄罗斯方块
算法流程
本项目目的是训练一个基于深度强化学习的俄罗斯方块。具体来说,这个代码通过以下步骤实现训练:
首先…

《Reinforcement Learning: An Introduction》第8章笔记
文章目录 Chapter 8 Planning and Learning with Tabular Methods8.1 Models and Planning8.2 Dyna: Integrated Planning, Acting, and Learning8.3 When the Models Is Wrong8.4 Prioritized Sweeping8.5 Expected vs. Sample Updates8.6 Trajectory Sampling8.7 Real-time D…

【强化学习】11 —— Double DQN算法与Dueling DQN算法
文章目录 Q-learning中的过高估计Double DQNDouble DQN代码实践Pendulum环境代码结果 Dueling DQNDueling DQN网络结构Dueling DQN优点Dueling DQN 代码实践结果 参考 Q-learning中的过高估计
普通的 DQN 算法通常会导致对值的过高估计(overestimation)…
深度强化学习-DDPG代码阅读-ddpg.py(1)
目录
1.编写ddpg.py
1.1 导入需要的包和其他的python文件
1.2 定义训练函数train()
1.2.1 代码总括
1.2.2 代码分解
1.3 定义测试函数test()
1.3.1 代码总括
1.3.2 代码分解
1.4 定义主函数
1.4.1 代码总括
1.4.2 代码分解
1.5 根据需要调用训练函数或者测试函数
…
强化学习开篇-那些问123
1、强化学习的基本结构是什么? 智能体和环境。智能体基于当前状态,采取动作,环境给出反馈也就是奖励,再去更新当前的状态。
2、强化学习相对于监督学习为什么训练过程会更加困难?
监督学习的样本一般是相互独立的&am…

【深入浅出强化学习-编程实战】3 基于动态规划的方法-鸳鸯系统
【深入浅出强化学习-编程实战】3 基于动态规划的方法2.1 鸳鸯系统——基于动态规划的方法2.1.1 基于策略迭代代码展示2.1.2 基于值函数迭代代码展示2.1.3 部分代码解析2.1 鸳鸯系统——基于动态规划的方法
左上为雄鸟,右上为雌鸟,中间有两道障碍物。目标…

【深入浅出强化学习-编程实战】 8 Actor-Critic-Pendulum(单摆系统)
【深入浅出强化学习-编程实战】 8 Actor-Critic-PendulumPendulum单摆系统MDP模型TD-AC算法TD-AC算法代码解析Minibatch-MC-AC算法Minibatch-MC-AC算法代码解析Pendulum单摆系统MDP模型
该系统只包含一个摆杆,其中摆杆可以绕着一端的轴线摆动,在轴线施加…
DDPG自动驾驶横向控制项目调参过程
DDPG自动驾驶横向控制项目调参过程actor和critic网络的学习率OU噪声参数设置整体参数设置结果我做的一个DDPG的自动驾驶横向控制的项目,用的模拟器是Torcs。在调参过程中遇到了很多问题,在这里记录一下。actor和critic网络的学习率
一开始我按照大部分资…

【星际争霸2中的强化学习-1】使用 PySC2 构建虫族机器人
中文网站上关于星际争霸2中AI模型的训练资料非常少,这里找到一篇比较好的pysc2使用的文章,翻译一下,方便阅读。
代码:GitHub - skjb/pysc2-tutorial: Tutorials for building a PySC2 botTutorials for building a PySC2 bot. Co…

【知识图谱论文】R2D2:基于辩论动态的知识图推理
Article
文献题目:Reasoning on Knowledge Graphs with Debate Dynamics 文献时间:2020 发表期刊:AAAI https://github.com/m-hildebrandt/R2D2
摘要
我们提出了一种基于辩论动力学的知识边图自动推理新方法。主要思想是将三元组分类的任务…

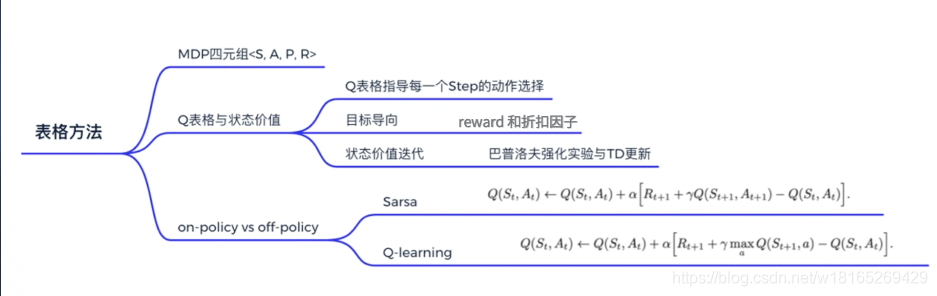
强化学习笔记------第三章----tabular methods(超详细)
Tabular Methods 本章通过最简单的表格型的方法(tabular methods)来讲解如何使用value_based方法求解强化学习。
Model-based 如上图所示。去跟环境交互时,只能走完完整的一条路。这里面产生了一系列的一个决策过程,这就是跟环境…
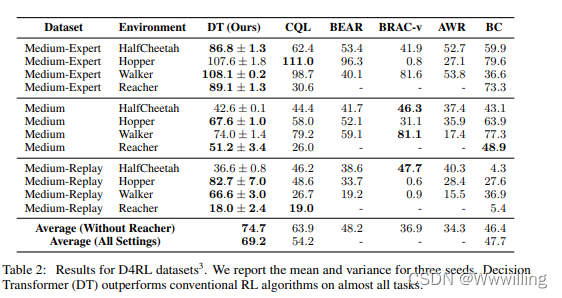
【强化学习论文】Decision Transformer:通过序列建模进行强化学习
Article
文献题目:Decision Transformer: Reinforcement Learning via Sequence Modeling 文献时间:2021
摘要
我们引入了一个将强化学习(RL)抽象为序列建模问题的框架。 这使我们能够利用 Transformer 架构的简单性和可扩展性…
【推荐系统论文】推荐系统的监督优势 Actor-Critic
文章标题:Supervised Advantage Actor-Critic for Recommender Systems发表时间:2022
摘要
通过奖励信号将基于会话或顺序的推荐作为强化学习 (RL) 是朝着最大化累积利润的推荐系统 (RS) 的一个有前途的研究方向。 然而,由于策略外训练、巨…
强化学习笔记(1)——概述
强化学习笔记(1)——概述1. 强化学习2. 序列决策过程简介3. Agents的类型1. 强化学习 强化学习的两大主体:agent和environment强化学习讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment)里面去极大化它能获得的奖励。当…

百度强化学习训练营总结
百度强化学习训练营总结
PARL是百度公司开发的一个强化学习框架。作为一个机器学习小白,也是因为身边的同学推荐,才知道这个课程, 在这个课程上面了解到paddlepaddle 和 PARL 。作为一个不是计算机专业方向的学生,了解到机器学习…
【论文笔记】基于组合优化的订单分配模型
本文是论文《A Taxi Order Dispatch Model based On Combinatorial Optimization》的阅读笔记。 一、摘要
传统的订单分配系统都是最大化每个订单的司机接受率,通常会对于每个订单寻找一个最近的司机,这导致了较低的全局成功率,并且订单分配…
强化学习环境gymnasium的搭建
强化学习环境gymnasium的搭建 0. 前言1. 环境搭建1.1 虚拟环境配置1.2 安装gymnasium2. 代码测试3. 版本变化3.1 reset和step方法3.2 wrappers.Monitor 参考链接 0. 前言
gym是目前强化学习最常用的工具之一,一直在迭代升级。2021年gym库不再更新,推出了…
ChatGPT 拓展资料: 强化学习-Gym环境
ChatGPT 拓展资料: 强化学习-Gym环境
Gym是一个广泛使用的开源软件库,它是针对强化学习任务的仿真环境和算法的工具包。它提供了一个标准的界面,使得研究人员可以轻松地使用各种强化学习算法进行模拟和测试。
Gym中包含了各种各样的环境,这些环境模拟了现实世界中的各种问…
强化学习中状态价值函数和动作价值函数的理解
考虑这样的一个选路径问题 从s点出发,有0.6的概率到a点,0.4的概率到b点,sa路径的回报是1,sb路径的回报是2,后面同理,箭头下面的选择这条路的概率,上面的数字是这条路的回报。目的地是g点。
从s…

sfn缺点_SFN 2016演示文稿
sfn缺点I recently presented at the annual meeting of the society for neuroscience, so I wanted to do a quick post describing my findings. 我最近在神经科学学会年会上作了演讲,所以我想做一篇简短的文章来描述我的发现。 The reinforcement learning lit…

围棋AI作弊第一人,切忌误入歧途
原文地址
还记得电影《天才枪手》中的经典桥段,凭借超强记忆男女主高智商犯罪,试图挑战法律底线,在国际考试中夹带手机藏于厕所作弊,最终法网恢恢疏而不漏,事情败露全员被抓捕。
如今随着人工智能的发展,…

强化学习(RL)初印象
学习百度AI Studio的笔记,供自己复习和记录学习过程中的思路使用,如想了解详情请移步百度AI Studio 强化学习(RL)初印象前言 什么是智能/人工智能Part1 什么是强化学习Part2 强化学习的分类Part3 强化学习能做什么Part4 强化学习与…

深度强化学习(王树森)笔记02
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…
【论文笔记】基于DQN和知识迁移的订单分配模型
本文是论文《Deep Reinforcement Learning with Knowledge Transfer for Online Rides Order Dispatching》的阅读笔记。 一、介绍
文章把订单分配问题建模成一个 MDP,并且提出了基于 DQN 的解决策略,为了增强的模型的适应性和效率,文章还提…
强化学习笔记------第二章----马尔可夫决策过程(MDP)(超详细)
在介绍马尔可夫决策过程之前,先介绍它的简化版本:马尔可夫链以及马尔可夫奖励过程,通过跟这两种过程的比较,我们可以更容易理解马尔可夫决策过程。
Markov Process(MP) Markov Property 如果一个状态转移是符合马尔可夫的&#x…

通用人工智能之路:什么是强化学习?如何结合深度学习?
目录 1 ChatGPT中的强化学习2 环境与智能体的交互3 强化学习特征四元组4 深度强化学习的引入5 教程大纲加入我们 1 ChatGPT中的强化学习
2015年,OpenAI由马斯克、美国创业孵化器Y Combinator总裁阿尔特曼、全球在线支付平台PayPal联合创始人彼得蒂尔等硅谷科技大亨…
Pytorch深度强化学习1-2:详解K摇臂赌博机模型和ϵ-贪心算法
目录 0 专栏介绍1 K-摇臂赌博机2 ϵ \epsilon ϵ-贪心算法3 softmax算法4 Python实现与分析 0 专栏介绍
本专栏重点介绍强化学习技术的数学原理,并且采用Pytorch框架对常见的强化学习算法、案例进行实现,帮助读者理解并快速上手开发。同时,…

经典ABR算法介绍:Pensieve (SIGCOMM ‘17) 原理及训练指南
文章目录 前言Pensieve原理*Pensieve重训练参考Oboe [SIGCOMM 18]Comyco [MM 19]Fugu [NSDI 20] A3C熵权重衰减思路实现 前言
Pensieve是DASH点播视频中最经典的ABR算法之一,也是机器学习类(Learning-based)ABR算法的代表性工作。Pensieve基…
强化学习(1):Q-Learning 算法
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解有关 Q-Learning 算法的内容,主要包括 on-policy 和 off-policy 的概念、Q-Learning 算法的基本思想和算法流程&#x…

【深度强化学习】4. Policy Gradient
【Datawhale打卡】十一的时候自己看过一遍,李宏毅老师讲的很好,对数学小白也很友好,但是由于没有做笔记(敲代码),看完以后脑袋里空落落的。趁着这次打卡活动,重新看一遍,果然好多细节…
强化学习(4):Double DQN、Prioritized Experience Replay DQN和Dueling DQN
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解有关Double DQN算法、Prioritized Experience Replay DQN 算法和 Dueling DQN 算法的相关内容。 对于 DQN 算法的改进主要有三种—…
强化学习(0):强化学习的基本概念与马尔科夫决策过程
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解有关强化学习的基本概念以及马尔科夫决策过程的相关内容。 关于强化学习的教程,我见过多种版本,每个老师所…

【强化学习】 Q-Learning
【强化学习】相关基本概念【强化学习】 Q-Learning【强化学习】 Q-Learning 案例分析【强化学习】 Sarsa【强化学习】 Sarsa(lambda)Q-Learning
强化学习的过程是智能体从与环境的交互中不断学习以完成特定目标
Q-Learning是强化学习的主要算法之一&am…
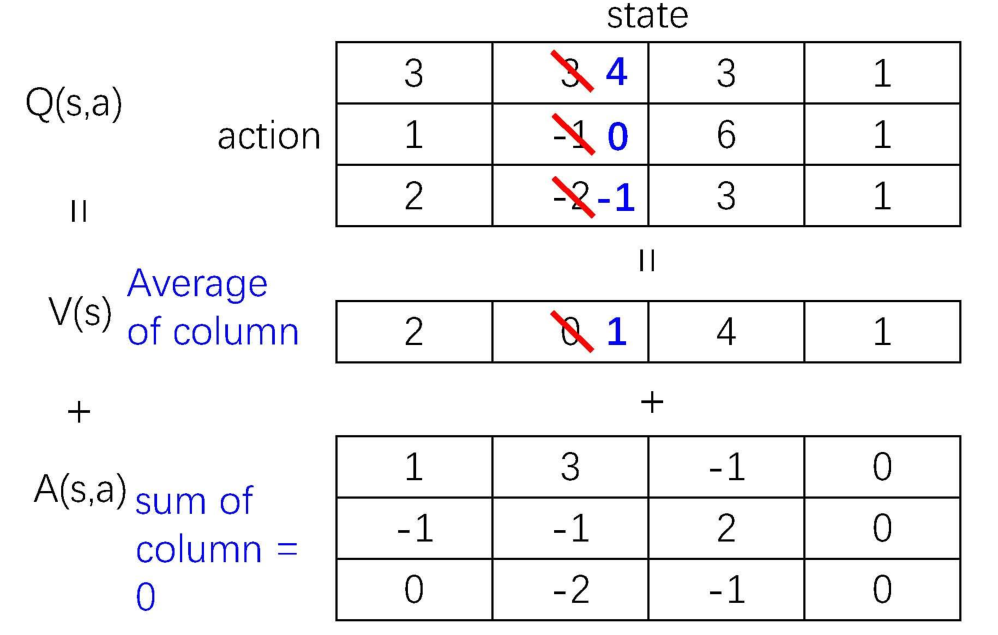
强化学习 - DQN及进化过程(Double DQN,Dueling DQN)
1.DQN 1.1概念 DQN相对于Q-Learning进行了三处改进:
1.引入神经网络:如下图所示希望能从状态S中提取Q(s,a) 2.经验回放机制:连续动作空间采样时,前后数据具有强关联性,而神经网络训练时要求数据之间具有独立同分布特性…
【AI视野·今日Robot 机器人论文速览 第六十五期】Mon, 30 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Mon, 30 Oct 2023 Totally 18 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers
Gen2Sim: Scaling up Robot Learning in Simulation with Generative Models Authors Pushkal Katara, Zhou Xian, Katerina F…
【强化学习】day1 强化学习基础、马尔可夫决策过程、表格型方法
写在最前:参加DataWhale十一月组队学习记录
【教程地址】 https://github.com/datawhalechina/joyrl-book https://datawhalechina.github.io/easy-rl/ https://linklearner.com/learn/detail/91 强化学习
强化学习是一种重要的机器学习方法,它使得智能…
强化学习应用(四):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
![深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM](https://img-blog.csdnimg.cn/img_convert/15018d18feed637b43df97129133bd62.png)
深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…
深入理解强化学习——强化学习的历史:试错学习
分类目录:《深入理解强化学习》总目录 让我们现在回到另一条通向现代强化学习领域的主线上,它的核心则是试错学习思想。我们在这里只对要点做概述,《深入理解强化学习》系列后面的文章会更详细地讨论这个主题。根据美国心理学家R.S.woodworth…

【论文笔记】Throwing Objects into A Moving Basket While Avoiding Obstacles
文章目录【论文笔记】Throwing Objects into A Moving Basket While Avoiding ObstaclesAbstractI. INTRODUCTIONII. RELATED WORKA. Analytical ApproachesB. Learning ApproachesC. Other WorksIII. METHODA. PreliminariesMarkov Decision Process (MDP)Off-policy RLB. Pro…

【强化学习】10 —— DQN算法
文章目录 深度强化学习价值和策略近似RL与DL结合产生的问题深度强化学习的分类 Q-learning回顾深度Q网络(DQN)经验回放优先经验回放 目标网络算法流程 代码实践CartPole环境代码结果 参考 深度强化学习
价值和策略近似 我们可以利用深度神经网络建立这些…
深度学习技巧应用28-强化学习的原理介绍与运用技巧实践
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用28-强化学习的原理介绍与运用技巧实践, 强化学习是一种机器学习的子领域,它使得一个智能体在与环境的交互中学习如何行动以最大化某种数值奖励信号。强化学习模型的关键特性是它的试错搜索和延迟奖励。
一、强化学习…
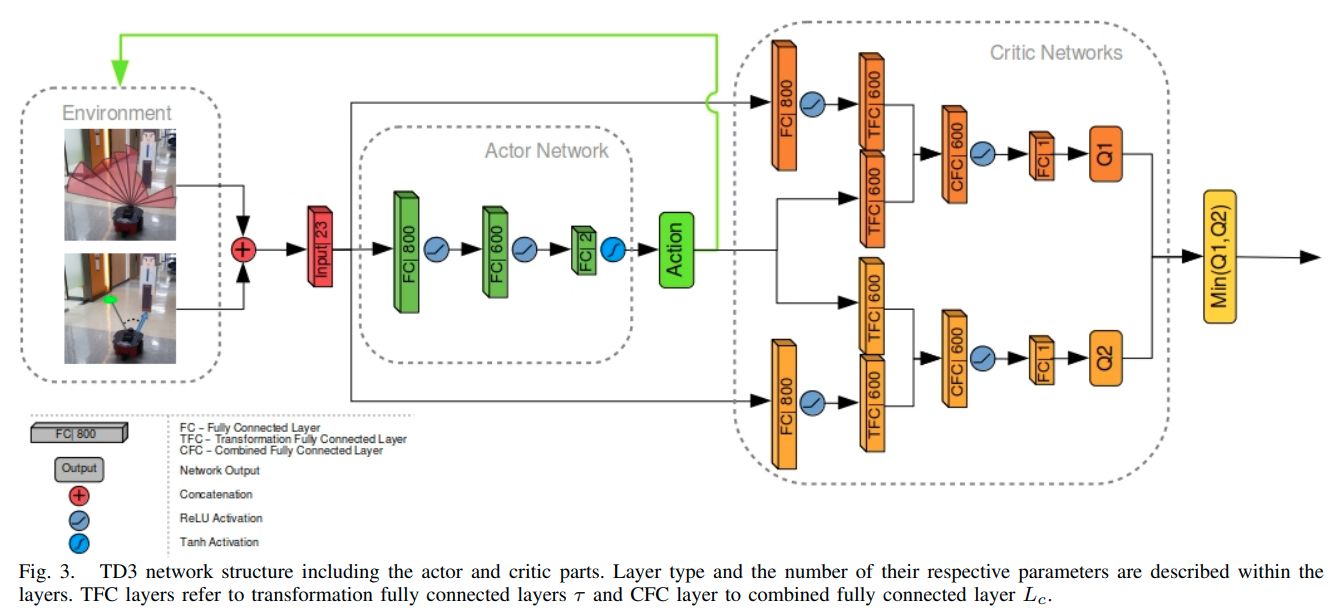
Gazebo仿真环境下的强化学习实现
Gazebo仿真环境下的强化学习实现
主体源码参照《Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning》 文章目录 Gazebo仿真环境下的强化学习实现1. 源码拉取2. 强化学习实现2.1 环境2.2 动作空间2.3 状态空间2.4 奖励空间2.5 TD3训练 3. 总结 1. 源码…

强化学习应用(八):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…

A thorough understanding of on-policy and off-policy in Reinforcement learning
一句话区分on-policy and off-policy: 看behaviour policy和current policy是不是同一个就OK了!
我这篇文章主要想借着理解on-policy和off-policy的过程来加深对其他RL算法的认识。因为万事万物总是相互联系的,所以在自己探究,琢…
强化学习(6):Actor-Critic(演员评论家)算法
本文主要讲解有关 Actor-Critic 算法的有关知识。 一、Actor Critic 算法
Actor-Critic 算法合并了以策略为基础的 Policy Gradient和以值为基础的 Q-Learning 两类强化学习算法,该算法中将前者当作 Actor,用来基于概率选择行为。将后者当作 Critic&…
强化学习之Grid World的Monte Carlo算法解析【MiniWorld】SYSU_2023SpringRL
强化学习之Grid World的Monte Carlo算法解析【MiniWorld】SYSU_2023SpringRL 题目以及思路代码结果算法解析代码算法流程题目以及思路
环境在这篇博客强化学习原理及应用作业之动态规划算法【SYSU_2023SpringRL】里面介绍了,不再赘述。
看看提示:蒙特卡洛方式在每次 episod…
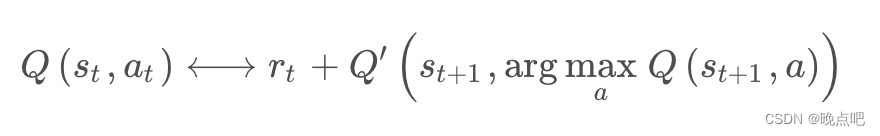
强化学习(一)——基本概念及DQN
1 基本概念 智能体 agent ,做动作的主体,(大模型中的AI agent) 环境 environment:与智能体交互的对象 状态 state ;当前所处状态,如围棋棋局 动作 action:执行的动作,…

【AI机器学习入门与实战】机器学习算法都有哪些分类?
👍【AI机器学习入门与实战】目录 🍭基础篇 🔥 第一篇:【AI机器学习入门与实战】AI 人工智能介绍 🔥 第二篇:【AI机器学习入门与实战】机器学习核心概念理解 🔥 第三篇:【AI机器学习入…
用深度学习预测股市涨跌之学习记录
从开始学习深度学习就想用深度学习尝试实现对股市涨跌对预测,虽然不抱很大期望,权当练习了。
硬件 I5 RTX 2060 16G内存 数据 首先,不管用什么模型都需要数据。我的数据来源一开始使用的是XTP的测试接口,后来陆续使用了sina的和…

深入理解强化学习——强化学习智能体的四要素:模型(Model)
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习智能体的四要素:策略(Policy) 强化学习智能体的四要素:收益信号(Revenue Signal) 强化学习智能体的四要素:价…
ChatGPT技术解构
ChatGPT的训练主要分为三个步骤,如图所示: Step1:
使用有监督学习方式,基于GPT3.5微调训练一个初始模型;训练数据约为2w~3w量级(根据InstructGPT的训练数据量级估算,参照https://arxiv.org/pdf…
Policy Evaluation收敛性、炼丹与数学家
完美的学习算法
昨天和同学在群里讨论DRL里bad case的问题。突然有同学提出观点:“bad case其实并不存在,因为一些算法已经理论证明了具有唯一极值点,再加上一些平滑技巧指导优化器,就必然可以收敛。”
当听到这个观点时&#x…

强化学习论文研读(四)——Deep Reinforcement Learning with Double Q-Learning
double Q learning DQN的合成算法。
论文主要有5点贡献:
一是DQN会对动作的价值过估计。
二是过估计是有害的。
三是double Q learning 可以减少过估计。通过评估网络和动作选择网络解耦实现的。
四是提出了三层卷积FC的Double DQN 算法结构和参数更新公式。 …

【深度强化学习】3. 表格型方法
【DataWhale打卡】百度的强化学习课程,通俗易懂,主要讲了Q-Learning,例子很多,生动形象。
1. Q-table概念
Q-table类似生活手册,在遇到一种特定的状态,会提供不同的动作,并且可以知道对应的价…
![深入理解强化学习——马尔可夫决策过程:占用度量-[基础知识]](https://img-blog.csdnimg.cn/direct/c2cba3d315284b52a5b67830ab89b722.png)
深入理解强化学习——马尔可夫决策过程:占用度量-[基础知识]
分类目录:《深入理解强化学习》总目录 文章《深入理解强化学习——马尔可夫决策过程:贝尔曼期望方程-[基础知识]》中提到,不同策略的价值函数是不一样的。这是因为对于同一个马尔可夫决策过程,不同策略会访问到的状态的概率分布是…
gym注册customer env 报错:Attempted to register malformed environment ID:My_env
跟随着gym的教程,准备把自己写的环境注册在gym的envs上面, 过程如下:
第⼀步,将我们⾃⼰的环境⽂件(笔者创建的⽂件名为 Myenv.py,类名为ReEnv ) 拷⻉到你的gym安装⽬录/gym/envs/classic_control⽂件夹中…
针对多轮推理分类问题的软标签构造方法
Motivation
在非对称博弈中,我们常常要对对手的状态(如持有的手牌类型)进行推理。此类推理问题有两个特点:(1) 虽然存在正确结果,但正确结果往往无法经过一次推理得到。因为随着游戏的进行,才能获得足够的…

大规模语言模型人类反馈对齐--RLHF
大规模语言模型在进行监督微调后, 模型具备了遵循指令和多轮对话的能力, 具备了初步与用户进行对话 的能力。然而, 大规模语言模由于庞大的参数量和训练语料, 其复杂性往往难以理解和预测。当这些模型被部署 时, 它们可…
强化学习算法---Q-learning
Q-learning 算法的步骤: <1> 给定参数lamda和奖励矩阵R <2>令Q[]为0 <3> for each episode 3.1 随机选择初始的状态s 3.2 未达到目标状态,则执行以下几步: (1)在当前状态s的所有可能行为中选取一个行…
机器学习笔记 - 基于强化学习的贪吃蛇玩游戏
一、关于深度强化学习 如果不了解深度强化学习的一般流程的可以考虑看一下下面的链接。因为这里的示例因为在PyTorch 之上实现深度强化学习算法。
机器学习笔记 - Deep Q-Learning算法概览深度Q学习是一种强化学习算法,它使用深度神经网络来逼近Q函数,用于确定在给定状态下采…

粒子群优化算法(Particle Swarm Optimization,PSO)求解基于移动边缘计算的任务卸载与资源调度优化(提供MATLAB代码)
一、优化模型介绍
移动边缘计算的任务卸载与资源调度优化原理是通过利用配备计算资源的移动无人机来为本地资源有限的移动用户提供计算卸载机会,以减轻用户设备的计算负担并提高计算性能。具体原理如下: 任务卸载:移动边缘计算系统将用户的计…
移动机器人路径优化:基于Q-learning算法的移动机器人路径优化(提供MATLAB代码)
一、Q-learning算法
Q-learning算法是强化学习算法中的一种,该算法主要包含:Agent、状态、动作、环境、回报和惩罚。Q-learning算法通过机器人与环境不断地交换信息,来实现自我学习。Q-learning算法中的Q表是机器人与环境交互后的结果&#…
强化学习笔记---入门简介
机器学习可以分为3类:有监督学习,无监督学习,强化学习;
强化学习可以解决什么问题?
概括来说,强化学习所能解决的问题为连续决策问题,就是需要连续不断做出决策才能实现最终的目标的问题。
强…

3D人体模型自动生成算法,连肌肉颤动都清晰可见!一作来自北大图灵班
子豪 发自 凹非寺量子位 报道 | 公众号 QbitAI我们在打游戏、看动漫的时候,遇到过不少这样的情况:感觉哪里不太对……现在,这些3D人体模型可以得到改进了~体态更逼真、褶皱更自然、肌肉更饱满:连情绪都显得更投入了……甚至肌肉颤…

【强化学习算法】Q-learning原理及实现
实现代码github仓库:RL-BaselineCode 代码库将持续更新,希望得到您的支持⭐,让我们一起进步! 文章目录 1. 原理讲解1.1 Q值更新公式1.2 ε-greedy随机方法 2. 算法实现2.1 算法简要流程2.2 游戏场景2.3 算法实现 3. 参考文章 1. 原…
Python爬虫实战—2345影视获取经典电影信息
爬虫提前准备包 1)安装解析库lxml lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。 命令行进行安装:pip install lxml 2)requests库,安装:pi…
Robotics+LLM系列具身智能视觉表征大模型
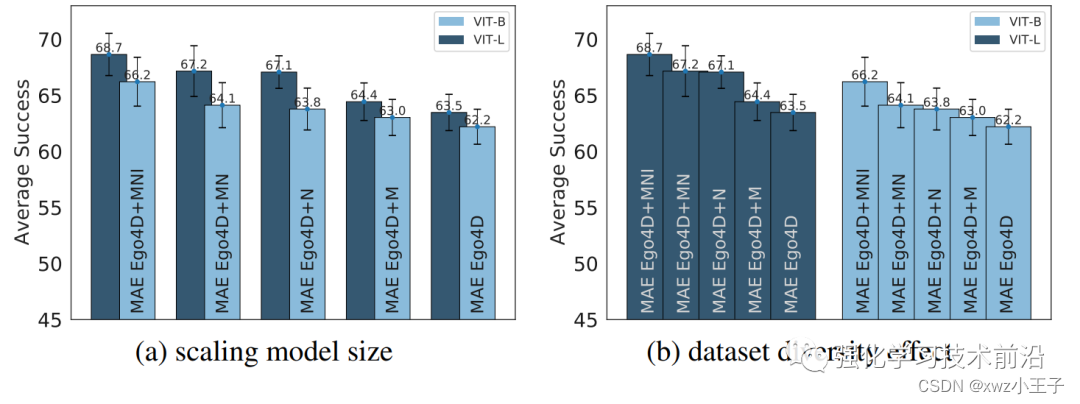
对于具身智能来说,视觉肯定是一个不可缺少的信息来源。那么是否有针适用于具身智能的预训练视觉表征(Pre-trained Visual Representations, PVRs)大模型是一个值得研究的点。这篇文章就从多种具身智能任务,构建了CortexBench&…
全球首个 AI 发球机器人诞生,国球练出新高度
By 超神经场景描述:近日,全球首台智能乒乓球发球机器人诞生,这款机器人将进行乒乓球的辅助教学工作。除了发球外,它还具备运动轨迹与动作分析能力,让训练数据化、智能化。关键词:乒乓球 发球机器人 运动轨迹…
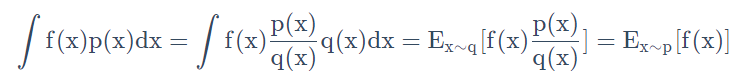
强化学习笔记------第五章----近端优化策略(PPO)(超详细)
本章数学问题太过复杂,建议去看看李宏毅老师这部分的内容,在此只贴出部分关于PPO的知识总结。
基于on-policy的policy gradient有什么可改进之处?或者说其效率较低的原因在于? 经典policy gradient的大部分时间花在sample data处…
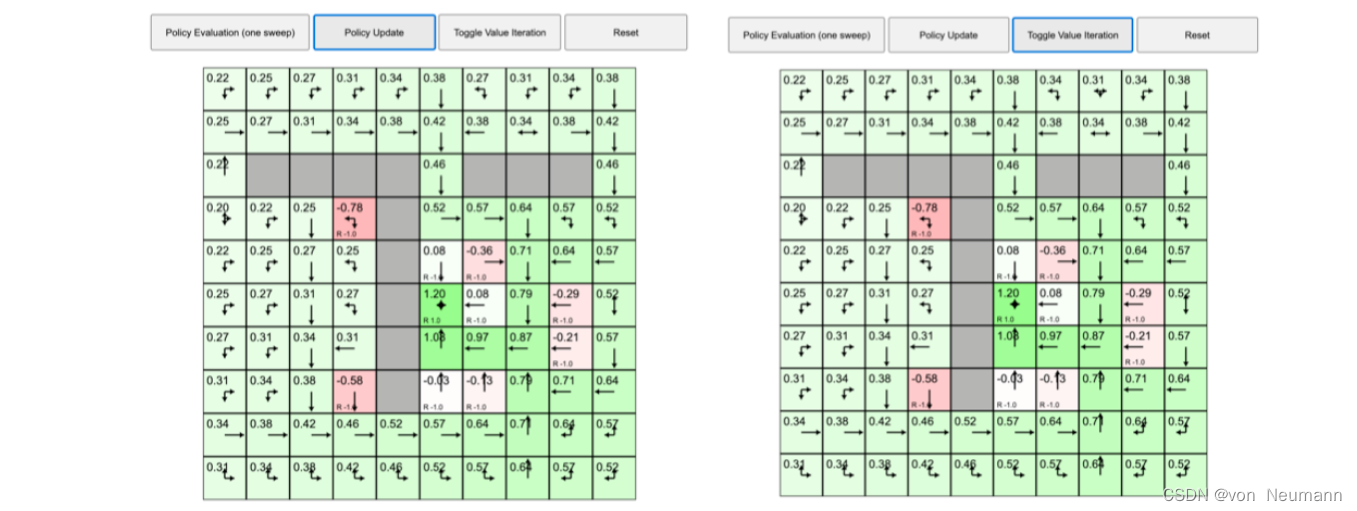
深入理解强化学习——马尔可夫决策过程:策略迭代与价值迭代的区别
分类目录:《深入理解强化学习》总目录 我们来看一个马尔可夫决策过程控制的动态演示,下图所示为网格世界的初始化界面: 首先我们来看看策略迭代,之前的例子在每个状态都采取固定的随机策略,每个状态都以0.25的概率往上…
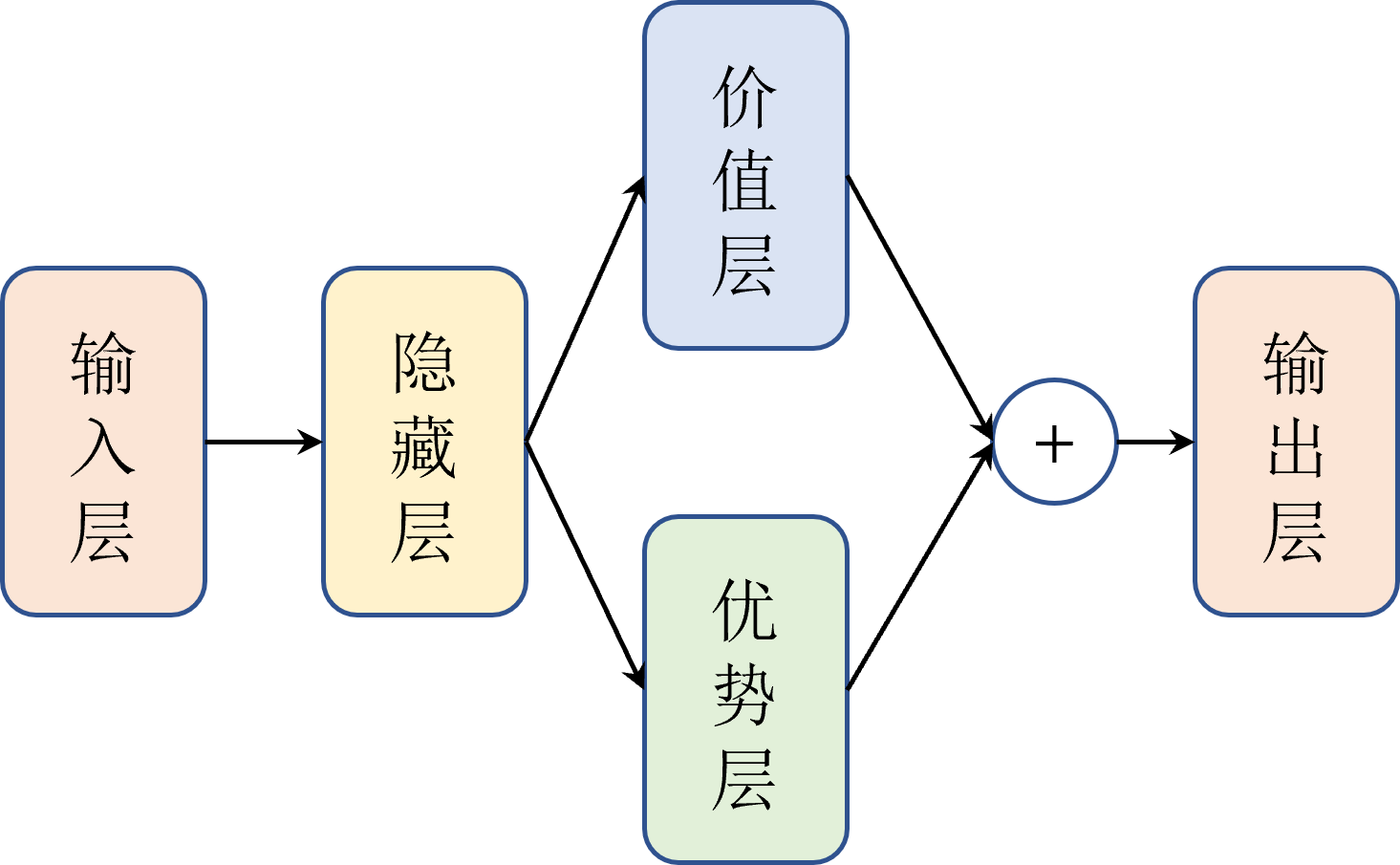
DQN、Double DQN、Dueling DQN、Per DQN、NoisyDQN 学习笔记
文章目录 DQN (Deep Q-Network)说明伪代码应用范围 Double DQN说明伪代码应用范围 Dueling DQN实现原理应用范围伪代码 Per DQN (Prioritized Experience Replay DQN)应用范围伪代码 NoisyDQN伪代码应用范围 部分内容与图片摘自:JoyRL 、 EasyRL DQN (Deep Q-Networ…
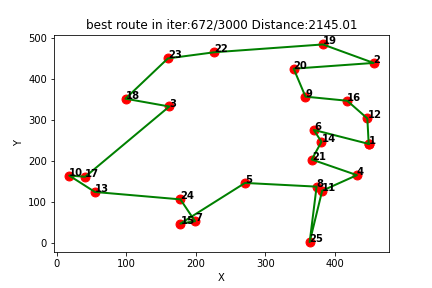
强化学习应用(二):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…

零基础强化学习教程(持续更新)
强化学习的过程记录一.强化学习最基础的概念定义1.1 通俗非正式讲解1.2 强化学习的两个特点和一个核心1.3 强化学习的三层架构1.4通俗说明强化学习的小故事一.强化学习最基础的概念定义
1.1 通俗非正式讲解
在本人初步的学习看来,强化学习更像是一个学会某种新东西…
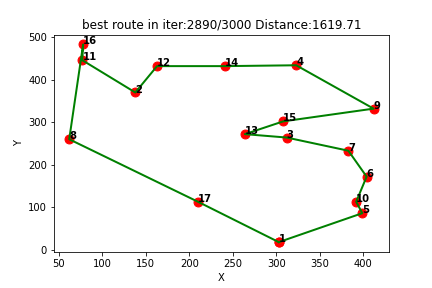
微电网优化MATLAB:遗传算法(Genetic Algorithm,GA)求解微电网优化(提供MATLAB代码)
一、微网系统运行优化模型
微电网优化是指通过对微电网系统中各个组件的运行状态进行监测和调节,以实现微电网系统的高效运行和能源利用的最大化。微电网是由多种能源资源(如太阳能、风能、储能等)和负载(如建筑、工业设备等&…
强化学习应用(一):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
Pytorch训练深度强化学习时CPU内存占用一直在快速增加
最近在用MATD3算法解决多机器人任务,但是在训练过程中,CPU内存一直在增加(注意,不是GPU显存)。我很头疼,以为是算法代码出了问题,导致了内存泄漏,折腾了1天也没解决。后来用memory_p…
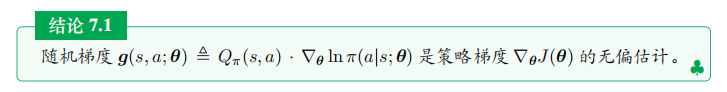
深度强化学习(王树森)笔记03
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…
强化学习论文研读(三)——Human-level control through deep reinforcement learning
提出nature-DQN算法的论文,主要改进:
使用bata-buffer的方式随机储存状态回放,消除数据的相关性,平滑数据的分布。使用定期(T1)更新Q的方式,使减少与当前目标的相关性,也就是所谓的…

My Roadmap in Reinforcement Learning
一、前言
前段时间接受导师的建议,学习了一些强化学习和GANs的内容,第一周先看的强化学习,二三周看的GANs。强化学习(RL)是一个很有趣的领域,一直以来也是我很喜欢的一个AI的分支,被誉为是AI皇…

【深度强化学习】2. 马尔科夫决策过程
【DataWhale打卡】周博磊博士-第二节马尔科夫决策过程,主要内容:
马尔科夫链、马尔科夫奖励过程、马尔科夫决策过程Policy evaluation in MDPControl in MDP: policy iteration & value iteration
这部分主要讲的除了MDP问题本身,主要是…
【深度学习】强化学习(三)强化学习的目标函数
文章目录 一、强化学习问题1、交互的对象2、强化学习的基本要素3、策略(Policy)4、马尔可夫决策过程5、强化学习的目标函数1. 总回报(Return)2. 折扣回报(Discounted Return)a. 折扣率b. 折扣回报的定义 3.…

【RLChina2023】CCF 苏州 记录
目录 RLChina介绍主旨报告专题报告智能体学习理论(专题一)智能体决策与规划(专题二)智能体框架、体系结构与训练系统(专题六)基于大语言模型的具身智能体与机器人研究 (专题八)教学报告——强化学习入门特别论坛——智能体和多智能体艺术的探索会议照片RLChina介绍 RLC…

强化学习 | 强化学习基础知识(图解)
强化学习是机器学习的一个领域。它是关于在特定情况下采取适当的行动来最大化奖励。它被各种软件和机器用来找到在特定情况下应该采取的最佳行为或路径。强化学习与监督学习的不同之处在于,在监督学习中,训练数据具有答案键,因此模型本身使用…

强化学习的数学原理学习笔记 - 时序差分学习(Temporal Difference)
文章目录 概览:RL方法分类时序差分学习(Temporal Difference,TD)TD for state values🟦Basic TD🟡TD vs. MC 🟦Sarsa (TD for action values)Basic Sarsa变体1:Expected Sarsa变体2&…

精进语言模型:探索LLM Training微调与奖励模型技术的新途径
大语言模型训练(LLM Training)
LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。
有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。
使用仓库之…
pycharm出现MemoryError
跑强化学习的时候,在训练集里面有用到append这个功能,看到内存就一直在增加,如果训练轮次过高,就会导致MemoryError的错误,你电脑有再大的内存也不行。 所以,赶快把append的功能删掉。

【rl-agents代码学习】01——总体框架
文章目录 rl-agent Get startInstallationUsageMonitoring 具体代码 学习一下rl-agents的项目结构以及代码实现思路。
source: https://github.com/eleurent/rl-agents
rl-agent Get start
Installation
pip install --user githttps://github.com/eleurent/rl-agentsUsage…
强化学习中on_plicy和off_policy最大的区别
策略更新方法可以分为两类:On-policy(在线策略)和Off-policy(离线策略)。它们之间的主要区别在于如何使用经验(状态、动作、奖励和下一个状态)来更新智能体的策略。以下是它们之间的主要区别&am…
深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[价值函数]
分类目录:《深入理解强化学习》总目录 在马尔可夫过程的基础上加入奖励函数和折扣因子,就可以得到马尔可夫奖励过程(Markov Reward Process)。一个马尔可夫奖励过程由 ( S , P , r , γ ) (S, P, r, \gamma) (S,P,r,γ)构成&#…
目标检测:深度学习引领视觉智能的未来
目标检测:深度学习引领视觉智能的未来
目标检测是计算机视觉领域中的一项重要任务,旨在从图像或视频中确定和定位特定物体的存在。这一领域的发展在很大程度上得益于深度学习技术的崛起,为机器在理解和处理视觉信息上带来了质的飞跃。本文将…
深入理解强化学习——序列决策(Sequential Decision Making)
分类目录:《深入理解联邦学习》总目录 在本文中我们将介绍序列决策(Sequential Decision Making)过程中的各个过程。
智能体与环境
强化学习研究的问题是智能体与环境交互的问题,下图左边的智能体一直在与下图右边的环境进行交互…

强化学习_06_pytorch-TD3实践(CarRacing-v2)
0、TD3算法原理简介
详见笔者前一篇实践强化学习_06_pytorch-TD3实践(BipedalWalkerHardcore-v3)
1、CarRacing环境观察及调整
Action SpaceBox([-1. 0. 0.], 1.0, (3,), float32)Observation SpaceBox(0, 255, (96, 96, 3), uint8)
动作空间是[-1~1, 0~1, 0~1],…
Python-DQN代码阅读-初始化经验回放记忆(replay memory)(4)
1.代码
def populate_replay_mem(sess, env, state_processor, replay_memory_init_size, policy, epsilon_start, epsilon_end, epsilon_decay_steps, VALID_ACTIONS, Transition):# 重置环境并获取初始状态state env.reset()# 使用状态处理器对初始状态进行预处理state st…

论文阅读:四足机器人对抗运动先验学习稳健和敏捷的行走
论文:Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors
进一步学习:AMP,baseline方法,TO
摘要:
介绍了一种新颖的系统,通过使用对抗性运动先验 (AMP) 使四足机器人在复杂地…

研究了一堆Q-learning资料后,写了这份指南
先来个名言,日本著名设计师山本耀司曾说:“我从来不相信什么懒洋洋的自由,我向往的自由是通过勤奋和努力实现的更广阔的人生,那样的自由才是珍贵的、有价值的;我相信一万小时定律,我从来不相信天上掉馅饼的…
深入理解强化学习——强化学习的例子
分类目录:《深入理解强化学习》总目录 为什么我们关注强化学习,其中非常重要的一个原因就是强化学习得到的模型可以有超人类的表现。 有监督学习获取的监督数据,其实是人来标注的,比如ImageNet的图片的标签都是人类标注的。因此我…
MATLAB - 比较 DDPG Agent 和 LQR 控制器
系列文章目录 前言
本示例展示了如何训练深度确定性策略梯度(DDPG)Agent,以控制 MATLAB 中建模的二阶线性动态系统。该示例还将 DDPG Agent 与 LQR 控制器进行了比较。
有关 DDPG 代理的更多信息,请参阅深度确定性策略梯度 (DDP…
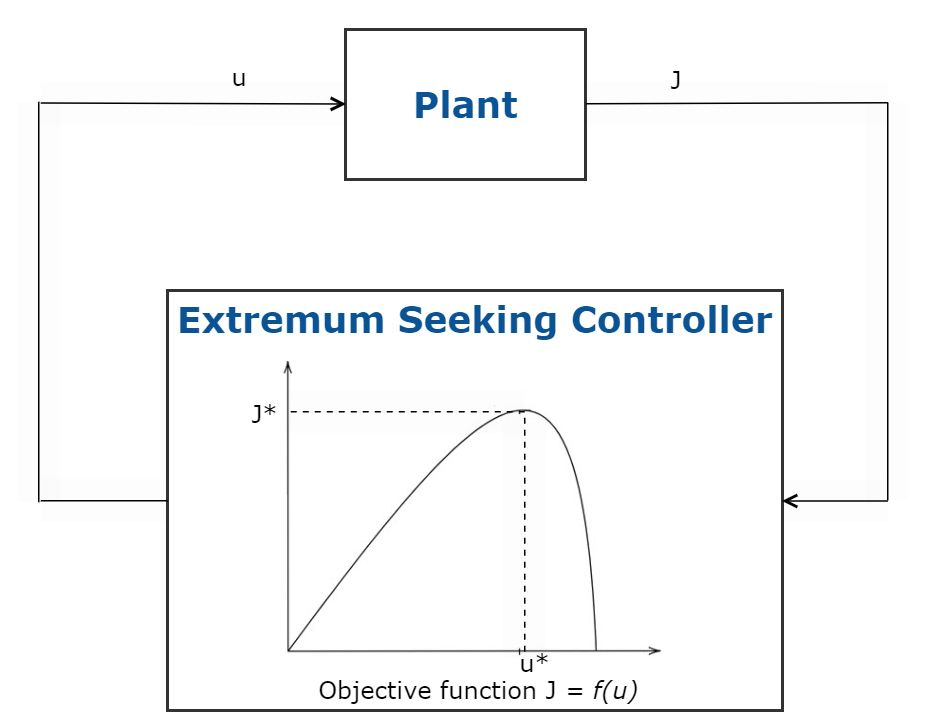
MATLAB - 最优控制(Optimal Control)
系列文章目录 前言 - 什么是最优控制? 最优控制是动态系统满足设计目标的条件。最优控制是通过执行以下定义的最优性标准的控制律来实现的。一些广泛使用的最优控制方法有: 线性二次调节器 (LQR)/线性二次高斯 (LQG) 控制 模型预测控制 强化学习 极值…
David Silver强化学习课程(2-9)思维导图整理
文档是根据David Silver 强化学习课件和视频整理的思维导图,包含了第二到第九讲的内容,不是很全面,请大家见谅。在整理过程中参考了 https://blog.csdn.net/xyk_hust 和 https://me.csdn.net/dukuku5038 的学习心得。思维导图软件是用的Xmind…
Reinforcement Learning | 强化学习十种应用场景及新手学习入门教程
文章目录 1.在自动驾驶汽车中的应用2.强化学习的行业自动化3.强化学习在贸易和金融中的应用4.NLP(自然语言处理)中的强化学习5.强化学习在医疗保健中的应用6.强化学习在工程中的应用7.新闻推荐中的强化学习8.游戏中的强化学习9.实时出价——强化学习在营…
【深度强化学习】9. Policy Gradient实现中核心部分torch.distributions
【导语】:在深度强化学习第四篇中,讲了Policy Gradient的理论。通过最终推导得到的公式,本文用PyTorch简单实现以下,并且尽可能搞清楚torch.distribution的使用方法。代码参考了LeeDeepRl-Notes中的实现。
1. 复习 θ←θη∇Rθ…

强化学习(五)-Deterministic Policy Gradient (DPG) 算法及公式推导
针对连续动作空间,策略函数没法预测出每个动作选择的概率。因此使用确定性策略梯度方法。
0 概览
1 actor输出确定动作2 模型目标: actor目标:使critic值最大 critic目标: 使TD error最大3 改进: 使用两个target 网络…

【深度强化学习】8. DDPG算法及部分代码解析
【DataWhale打卡】DDPG算法 Deep Deterministric Policy Gradient
视频参考自:https://www.bilibili.com/video/BV1yv411i7xd?p19
1、思维导图 2. 详解
DDPG是解决连续性控制问题的一个算法,但是和PPO不同,PPO输出是一个策略,…

【EAI 019】Eureka: Human-Level Reward Design via Coding LLM
论文标题:Eureka: Human-Level Reward Design via Coding Large Language Models 论文作者:Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar 作者单位ÿ…

【深度强化学习】1. 基础部分
文章目录强化学习纲要-基础部分强化学习应用案例强化学习在做什么?基本要素分类1. 按照Agent有没有对环境建模来分类2. 按照Agent的决策方式来分类时序决策过程动作空间智能体主要组成部分1. Policy2. Value Function3. ModelExploration and Exploitation知识点补充…

《Learning Combinatorial Optimization Algorithms over Graphs》阅读笔记
一.文章概述
本文提出将强化学习和图嵌入的组合以端到端地自动为图上组合优化问题设计贪心启发式算法,以避免设计传统算法所需要的大量专业知识和试错。学得的贪心策略行为类似增量构造解决方案的元算法,动作由解决方案当前状态上的图嵌入网络确定。作者…
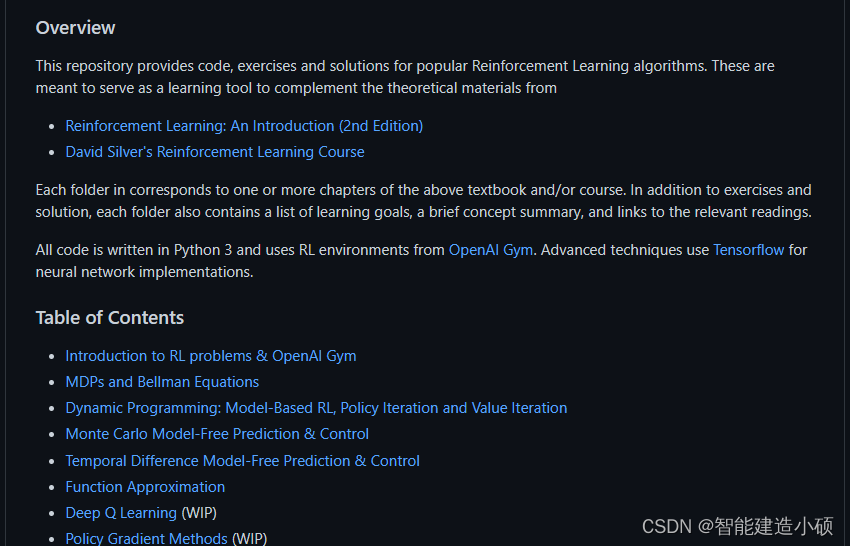
【论文阅读】基于鲁棒强化学习的无人机能量采集可重构智能表面
只做学习记录,侵删原文链接 article{peng2023energy, title{Energy Harvesting Reconfigurable Intelligent Surface for UAV Based on Robust Deep Reinforcement Learning}, author{Peng, Haoran and Wang, Li-Chun}, journal{IEEE Transactions on Wireless Comm…
Python-DQN-L1、L2和Huber损失
1.L1损失
L1损失,也称为平均绝对误差(Mean Absolute Error,MAE),是一种在回归问题中使用的损失函数,用于衡量预测值与实际值之间的绝对差异。
L1损失的数学定义如下: L1损失 |预测值 - 实际值…
深度学习实战19(进阶版)-SpeakGPT的本地实现部署测试,基于ChatGPT在自己的平台实现SpeakGPT功能
大家好,我是微学AI,今天给大家带来SpeakGPT的本地实现,在自己的网页部署,可随时随地通过语音进行问答,本项目项目是基于ChatGPT的语音版,我称之为SpeakGPT。
ChatGPT最近大火,其实在去年12月份…

【深度强化学习】确定性策略梯度算法 DDPG
前面讲到如 REINFORCE,Actor-Critic,TRPO,PPO 等算法,它们都是随机性策略梯度算法(Stochastic policy),在广泛的任务上表现良好,因为这类方法鼓励了算法探索,给出的策略是…
Python-代码阅读-将一个神经网络模型的参数复制到另一个模型中(2)
1.代码
def copy_model_parameters(sess, qnet1, qnet2):# 获取qnet1和qnet2中的可训练变量(参数)q1_params [t for t in tf.trainable_variables() if t.name.startswith(qnet1.scope)]q1_params sorted(q1_params, keylambda v: v.name)q2_params …
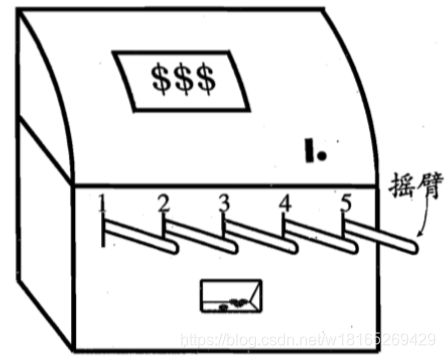
强化学习笔记------第一章----强化学习概述(超详细)
强化学习讨论的问题是一个智能体(agent)怎么在一个复杂不确定的环境(environment)里面去极大化他能获得的奖励。
首先,我们可以把强化学习和监督学习做一个对比。 例如图片分类,监督学习(super…

【强化学习】12 —— 策略梯度(REINFORCE )
文章目录 前言策略梯度基于策略的强化学习的优缺点Example:Aliased Gridworld策略目标函数策略优化策略梯度利用有限差分计算策略梯度得分函数和似然比策略梯度定理蒙特卡洛策略梯度(Monte-Carlo Policy Gradient)Puck World Example Softmax随机策略 代…
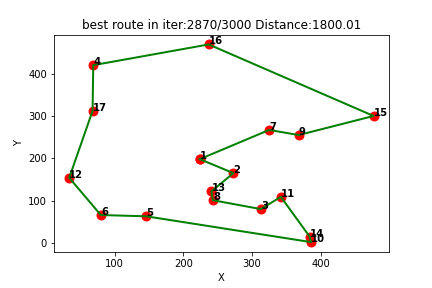
强化学习应用(五):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…

【学习之路】Multi Agent Reinforcement Learning框架与代码
【学习之路】Multi Agent Reiforcement Learning框架与代码
Introduction
国庆期间,有个客户找我写个代码,是强化学习相关的,但我没学过,心里那是一个慌,不过好在经过详细的调研以及自身的实力,最后还是解…

《Reinforcement Learning: An Introduction》第5章笔记
Chapter 5 Monte Carlo Methods
Monte Carlo 方法不假设拥有完备的环境知识,它仅仅需要经验–从与环境的实际或模拟交互中得到的一系列的状态、动作、和奖励的样本序列。
Monte Carlo方法是基于平均采样回报的来解决强化学习问题的方法。
5.1 Monte Carlo Predic…

【强化学习】16 ——PPO(Proximal Policy Optimization)
文章目录 前言TRPO的不足PPO特点 PPO-惩罚PPO-截断优势函数估计算法伪代码PPO 代码实践参考 前言
TRPO 算法在很多场景上的应用都很成功,但是我们也发现它的计算过程非常复杂,每一步更新的运算量非常大。于是,TRPO 算法的改进版——PPO 算法…
强化学习论文研读(一)——Where Do Rewards Come From?
在强化学习领域,传统的要素为环境,观察表述,奖励,动作,这里的奖励完全由环境给出,论文提出一种内部驱动的奖励系统,如下图所示: 本文将奖励分为内部驱动的奖励和外部驱动的奖励&…
强化学习(2):Sarsa 算法及 Sarsa(lambda) 算法
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解 Sarsa 算法以及 Sarsa(λ\lambdaλ) 算法的相关内容,同时还会分别附上一个莫烦大神写的例子。 一、Sarsa 算法
Sarsa…
Unity-ML-Agents注意事项及报错、警告等解决方式
1.注意事项
1.1 ml-agents 0.28.0找不到Scripts/Brain组件?
在 ml-agents 0.16.0 版本中,Unity 中的 ML-Agents 插件中包含了名为 Brain 的组件,用于控制智能体的决策过程。然而,在 ml-agents 0.28.0 版本中,该组件已…

什么是强化学习?强化学习有哪些框架、算法、应用?
什么是强化学习?
强化学习是人工智能领域中的一种学习方式,其核心思想是通过一系列的试错过程,让智能体逐步学习如何在一个复杂的环境中进行最优的决策。这种学习方式的特点在于,智能体需要通过与环境的交互来获取奖励信号&#…

深入理解强化学习——强化学习的历史:时序差分学习
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习的历史:最优控制 强化学习的历史:试错学习 强化学习的历史:试错学习的发展 强化学习的历史:K臂赌博机、统计学习理论和自适应系统 强化学习的…

Actor-critic
Actor-criticReview-Policy GradientReview-Q-learningActor-CriticAdvantage Actor-Critic(A2C)Asynchronous Advantage Actor-Critic(A3C)Pathwise Derivative Policy Gradient李宏毅深度强化学习 学习笔记 学习资料:http://speech.ee.ntu.edu.tw/~tlkagk/courses…
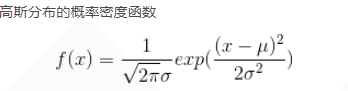
【深入浅出强化学习-编程实战】 8 DDPG(单摆系统)
【深入浅出强化学习-编程实战】 10 DDPGPendulum单摆系统MDP模型代码训练效果代码学习Pendulum单摆系统MDP模型
该系统只包含一个摆杆,其中摆杆可以绕着一端的轴线摆动,在轴线施加力矩τ\tauτ来控制摆杆摆动。Pendulum目标是:从任意状态出发…

【深入浅出强化学习-原理入门】1 基于gym的MDP
【深入浅出强化学习-原理入门】1 基于gym的MDPwindows版本强化学习gym找金币游戏
第一步:grid_mdp.py代码展示
import logging #日志模块
import numpy
import random
from gym import spaces
import gymlogging logging.getLogger(__name__)# Set this in SOME …

【深度强化学习】6. Q-Learning技巧及其改进方案
【DataWhale打卡】第四次任务,主要是重新学习一下李宏毅的Q-learning部分的知识,推导很多。之前看的时候就是简单过了一遍,很多细节没有清楚。这篇笔记包括了李宏毅深度强化学习三个视频长度的内容。 文章目录1. 概念/解释2. Value Function3…

强化学习14——DDPG算法
在线策略算法的样本效率比较低,而在DNQ算法中,做到了离线策略学习,但是只能处理动作空间有限的环境。如果动作空间无限,可将动作空间离散化,但比较粗糙,无法惊喜控制。深度确定性策略梯度DDPG(d…
强化学习的数学原理学习笔记 - Actor-Critic
文章目录 概览:RL方法分类Actor-CriticBasic actor-critic / QAC🟦A2C (Advantage actor-critic)Off-policy AC🟡重要性采样(Importance Sampling)Off-policy PGOff-policy AC 🟦DPG (Deterministic AC) 本…
如何让自己像打游戏一样发了疯、拼了命、石乐志的学习或者工作?
阶段性反馈机制(如何持之以恒、让自己发疯) 反馈机制是王者荣耀的核心武器,击杀野怪获得金币,击杀敌人之后的画面、音效刺激大脑,不断地努力,获得奖励是我们不断的玩这个游戏的主要原因,也是人的…
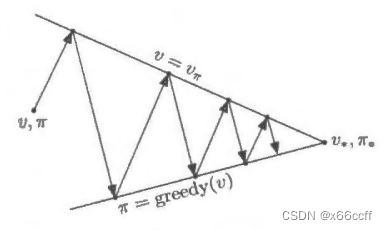
【强化学习-读书笔记】动态规划(策略评估、价值迭代、策略迭代算法)
参考
Reinforcement Learning, Second Edition
An Introduction
By Richard S. Sutton and Andrew G. Barto动态规划 (Dynamic Programming, DP) 是一类优化方法,在给定一个用马尔可夫决策过程 (MDP) 描述的完备环境模型的情况下,其可以计算最优的策…

《Reinforcement Learning: An Introduction》第3章笔记
Chapter 3 Finite Markov Decision
本章正式介绍有限马尔科夫决策过程(finite Markov decision processes, finite MDP), 它包括第二章介绍的评估性反馈和关联(associative)—在不同情景下选择不同的状态。
MDP是序贯决策问题的经典形式化表达,它的动作…
![强化学习从基础到进阶-案例与实践[4.2]:深度Q网络DQN-Cart pole游戏展示](https://img-blog.csdnimg.cn/img_convert/3dd60368e487ce90474df69f539d333f.png)
强化学习从基础到进阶-案例与实践[4.2]:深度Q网络DQN-Cart pole游戏展示
【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现 专栏详细介绍:【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧…
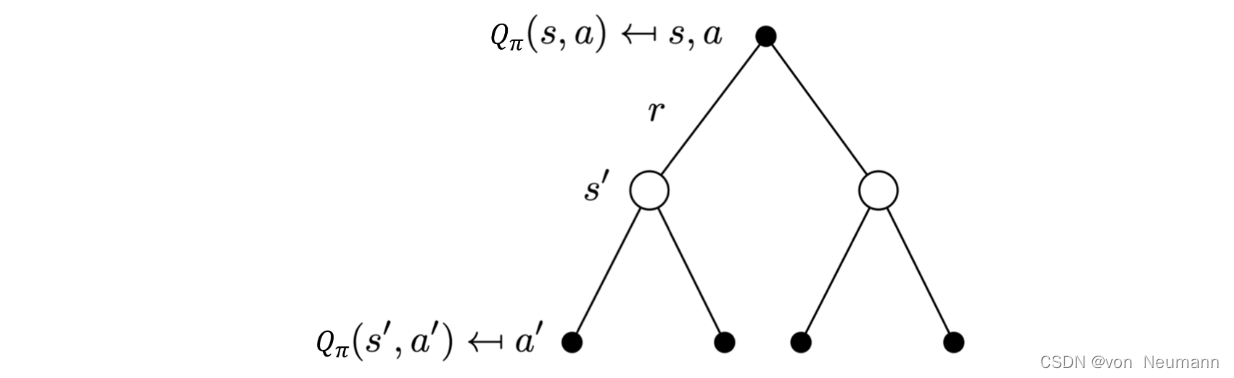
深入理解强化学习——马尔可夫决策过程:备份图(Backup Diagram)
分类目录:《深入理解强化学习》总目录 在本文中,我们将介绍备份(Backup)的概念。备份类似于自举之间的迭代关系,对于某一个状态,它的当前价值是与它的未来价值线性相关的。 我们将与下图类似的图称为备份图…
深入理解强化学习——马尔可夫决策过程:价值迭代-[确认性价值迭代]
分类目录:《深入理解强化学习》总目录 如果我们知道子问题 V ∗ ( s ′ ) V^*(s) V∗(s′)的最优解,就可以通过价值迭代来得到最优的 V ∗ ( s ) V^*(s) V∗(s)的解。价值迭代就是把贝尔曼最优方程当成一个更新规则来进行,即: V …
【深度强化学习】(8) iPPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下多智能体深度强化学习算法 ippo,并基于 gym 环境完成一个小案例。完整代码可以从我的 GitHub 中获得:https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model 1. 算法原理
多智能体的情形相比于单智…

【深度学习】强化学习(五)深度强化学习
文章目录 一、强化学习问题1、交互的对象2、强化学习的基本要素3、策略(Policy)4、马尔可夫决策过程5、强化学习的目标函数6、值函数7、深度强化学习1. 背景与动机2. 关键要素3. 成功案例4. 挑战和未来展望5. 核心概念和方法总结 一、强化学习问题 强化学…
【python机器学习】学习笔记1
【python机器学习】学习笔记11.1 数字运算1.2 while1.3 文件1.4 class1.5 input1.6 tuple list1.7 字典1.8 import1.9 while break continue1.10 错误处理 try1.11 map zip lambda1.12 copy1.13 set1.14 regulate expression正则表达式1.15 numpy1.16 pandas1.17 matplotlib(1)…

【强化学习纲要】6 策略优化进阶
【强化学习纲要】6 策略优化进阶6.1 policy gradient的变种6.2 First lines of works on SOTA policy optimization6.2.1 Policy Gradient6.2.2 Natural policy gradient/TRPO6.2.3 ACKTR6.2.4 PPO6.3 Second lines of works on SOTA policy optimization6.3.1 DDPG6.3.2 TD36.…
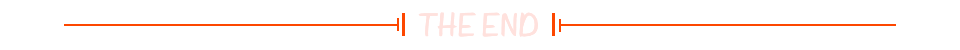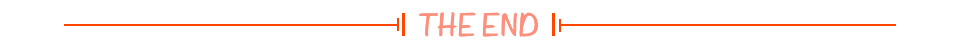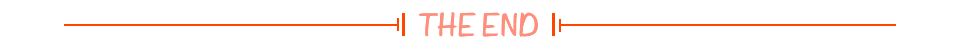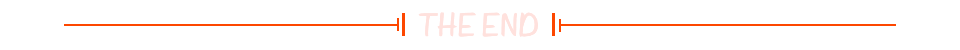
强化学习第1天:强化学习概述
☁️主页 Nowl
🔥专栏《机器学习实战》 《机器学习》
📑君子坐而论道,少年起而行之
文章目录
介绍
强化学习要素
强化学习任务示例
环境搭建:gym
基本用法
环境信息查看
创建智能体
过程可视化
完整代码
结语…


Alphago Zero的原理及实现:Mastering the game of Go without human knowledge
近年来强化学习算法广泛应用于游戏对抗上,通用的强化学习模型一般包含了Actor模型和Critic模型,其中Actor模型根据状态生成下一步动作,而Critic模型估计状态的价值,这两个模型通过相互迭代训练(该过程称为Generalized …
强化学习代码实战入门 | 井字棋Tic-Tac-Toe代码详解
这是一个易理解的 demo,300行左右,可以作为RL的入门代码,辅助基础公式的理解 这个是我自己的学习笔记。三连留下邮箱,可以直接发送完整的代码标注文件~ 如有错误,麻烦指出!我已经蛮久没写博了,上…
深度强化学习算法的参数更新时机
深度强化学习算法的参数更新时机
深度强化学习中往往涉及到多个神经网络来拟合策略函数、值函数等,什么时候更新参数因算法而异,与具体算法架构/算法思想紧密相关。
算法参数更新时机架构DQN先收集一定经验,然后每步更新Off Policy Value-B…

【强化学习】18 —— SAC( Soft Actor-Critic)
文章目录 前言最大熵强化学习不同动作空间下的最大熵强化学习基于能量的模型软价值函数最大熵策略 Soft Q-learningSoft Q-IterationSoft Q-Learning近似采样与SVGD伪代码 Soft Actor-Critic伪代码代码实践连续动作空间离散动作空间 参考与推荐 前言
之前的章节提到过在线策略…

大规模语言模型人类反馈对齐--强化学习
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮, 它面对多种多样的问题对答如流, 似乎已经打破了 机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Le…
安装tianshou
安装tianshou
上https://github.com/thu-ml/tianshou,下面有安装的教程。
pip install tianshou或者
conda install tianshou -c conda-forge运行例程,可能会出现缺少cv2的错误 就继续安装,就行
pip install opencv-python然后继续运行代…
机器学习笔记 - Deep Q-Learning算法概览
一、Q-Learning 强化学习大致可以分为两类:无模型强化学习算法和基于模型的强化学习算法。无模型强化学习算法不会学习环境转换函数的模型来预测未来状态和奖励。Q 学习、深度 Q 网络和策略梯度方法是无模型算法,因为它们不创建环境转换函数的模型。
1、Q-学习算法 Q-学习算…
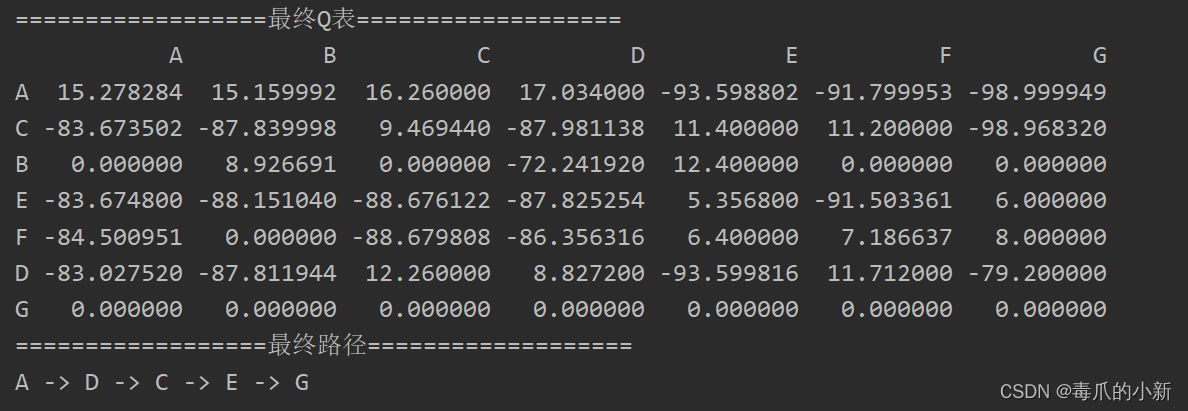
Q-Learning 单路径吃宝箱问题--棋盘格吃宝箱问题--拓扑节点较优路径问题
Q-Learning项目实战 一. 概述 上一篇概念文章讲解了算法的概念和原理:Q-Learning 原理干货讲解 本文将进行项目实战讲解,分别为:
单路径吃宝箱问题棋盘格吃宝箱问题拓扑节点较优路径问题
Q-Learning算法的本质还是下面这个公式,…

【AI视野·今日Robot 机器人论文速览 第五十三期】Thu, 12 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Thu, 12 Oct 2023 Totally 25 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers
Pixel State Value Network for Combined Prediction and Planning in Interactive Environments Authors Sascha Rosbach, St…

便宜又大碗!AI将画廊轻松搬到自家墙壁;用隐写术在图像中存储文件;免费书·算法高维鲁棒统计;关节式手部模型数据集;前沿论文 | ShowMeAI资讯日报
👀日报合辑 | 📆电子月刊 | 🔔公众号下载资料 | 🍩韩信子 📢 Mixtiles:将画廊搬到自家墙壁,“便宜又大碗”的艺术平替
https://www.mixtiles.com/
Mixtiles 是一家快速发展的照片创业公司&…

【深度强化学习】5. Proximal Policy Optimization
【DataWhale导读】李宏毅老师的深度强化学习之PPO(近端策略优化)部分内容。 文章目录1. 概念/关键词2. from on-policy to off-policy3. PPO/TRPO3.1 PPO-Penalty3.2 PPO-Clip4. 参考1. 概念/关键词
名称解释On-Policy学习的agent和与环境互动的agent是…
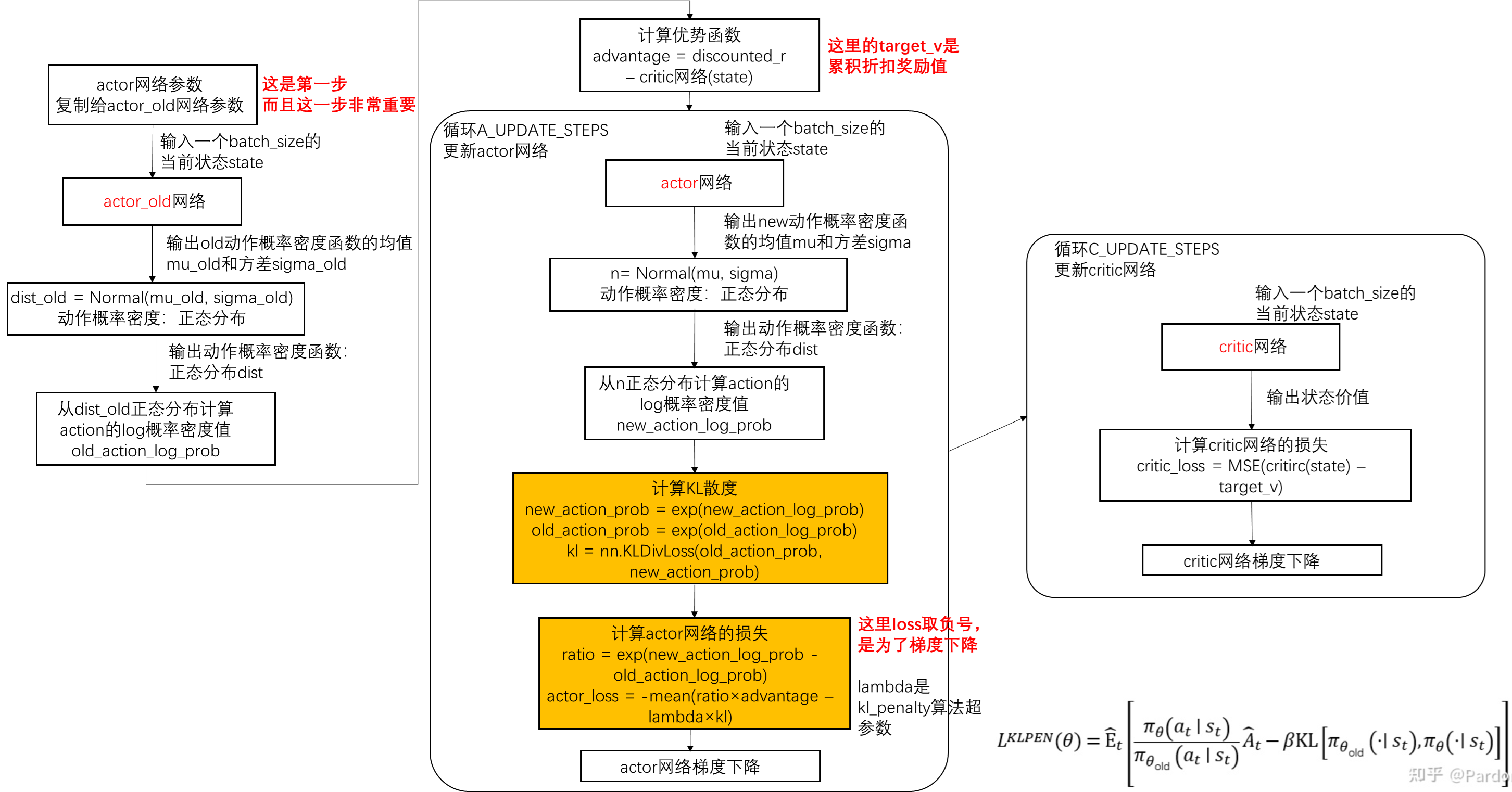
PPO算法基本原理及流程图(KL penalty和Clip两种方法)
PPO算法基本原理
PPO(Proximal Policy Optimization)近端策略优化算法,是一种基于策略(policy-based)的强化学习算法,是一种off-policy算法。
详细的数学推导过程、为什么是off-policy算法、advantage函数…

【强化学习论文合集】AAAI-2022 强化学习论文 | 2022年合集(四)
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。 本专栏整理了近几年国际顶级会议中,涉及强化学习(Rein…
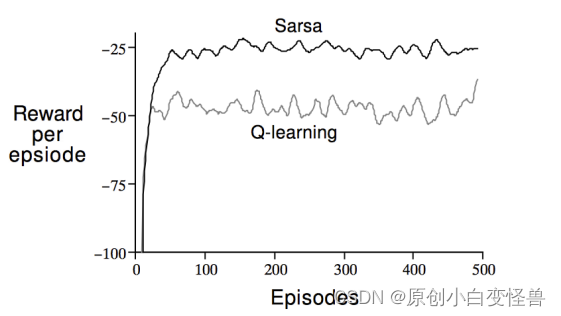
强化学习的Sarsa与Q-Learning的Cliff-Walking对比实验
强化学习的Sarsa与Q-Learning的Cliff-Walking对比实验Cliff-Walking问题的描述Sarsa和Q-Learning算法对比代码分享需要改进的地方引用和写在最后Cliff-Walking问题的描述 悬崖行走:从S走到G,其中灰色部分是悬崖不可到达,求可行方案 建模中&am…
RL笔记:动态规划(2): 策略迭代
目录
0. 前言
(4.3) 策略迭代
Example 4.2: Jack’s Car Rental
Exercise 4.4
Exercise 4.5
Exercise 4.6
Exercise 4.7 0. 前言 Sutton-book第4章(动态规划)学习笔记。本文是关于其中4.2节(策略迭代)。 (4.3) 策略迭代 基…
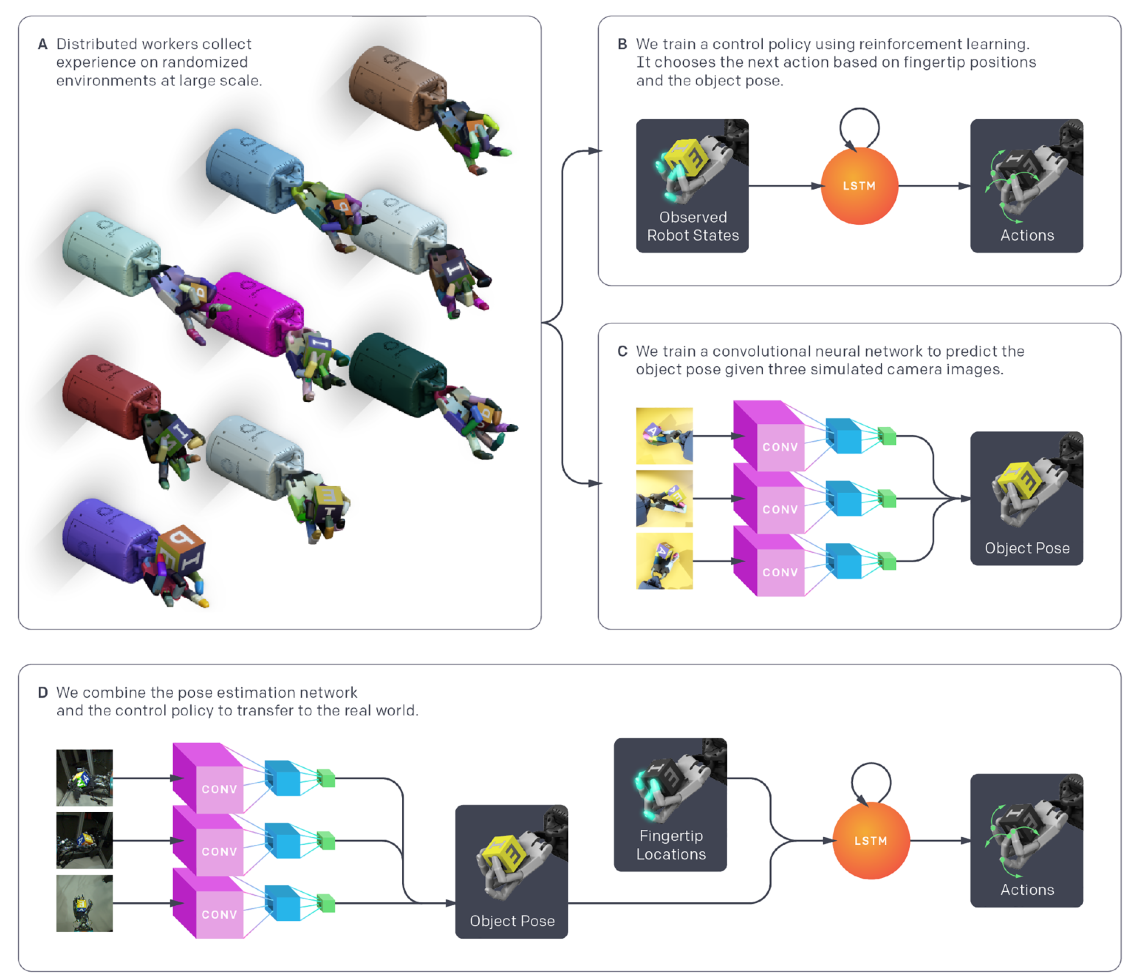
【强化学习与机器人控制论文 2】基于强化学习的五指灵巧手操作
基于强化学习的五指灵巧手操作1. 引言2. 论文解读2.1 背景2.2 论文中所用到的强化学习方法2.3 实验任务和系统2.4 仿真到实物的迁移2.5 分布式RL训练——从状态中学到控制策略2.6 ResNet——从视觉中得到状态估计2.7 实验结果3. 总结1. 引言
本文介绍一篇OpenAI团队出品&#…
Python-DQN和DDQN代码对比阅读(14)-ddpn.py
DQN和DDQN都是三个文件,funcs.py、model.py和DQN.py或者DDQN.py。
两种算法的funcs.py、model.py文件完全一样,区别在第三个文件。
目录 1.代码区别
1.1 定义ALGO变量来选择算法
1.2 使用if语句对两种算法做出选择
1.2.1 DQN
1.2.2 DDQN
2.问题 1…
Python-代码阅读(1)-funcs.py
1.图像处理的类 ImageProcess
import numpy as np
import sys
import tensorflow as tf # 导入 TensorFlow 库,用于实现深度学习模型# convert raw Atari RGB image of size 210x160x3 into 84x84 grayscale image
class ImageProcess():def __init__(self):with …
Python-pop()和popleft()方法
1. pop()和popleft()方法
pop() 和 popleft() 是 Python 标准库 collections 模块中 deque(双端队列)对象的方法,用于从队列中删除元素。
pop() 方法用于从队列的右侧(末尾)删除元素,并返回被删除的元素。…
![强化学习从基础到进阶-案例与实践[3]:表格型方法:Sarsa、Qlearning;蒙特卡洛策略、时序差分等以及Qlearning项目实战](https://img-blog.csdnimg.cn/img_convert/66cf991d2b104a17642d74e15af55706.png)
强化学习从基础到进阶-案例与实践[3]:表格型方法:Sarsa、Qlearning;蒙特卡洛策略、时序差分等以及Qlearning项目实战
【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现 专栏详细介绍:【强化学习原理项目专栏】必看系列:单智能体、多智能体算法原理项目实战、相关技巧…
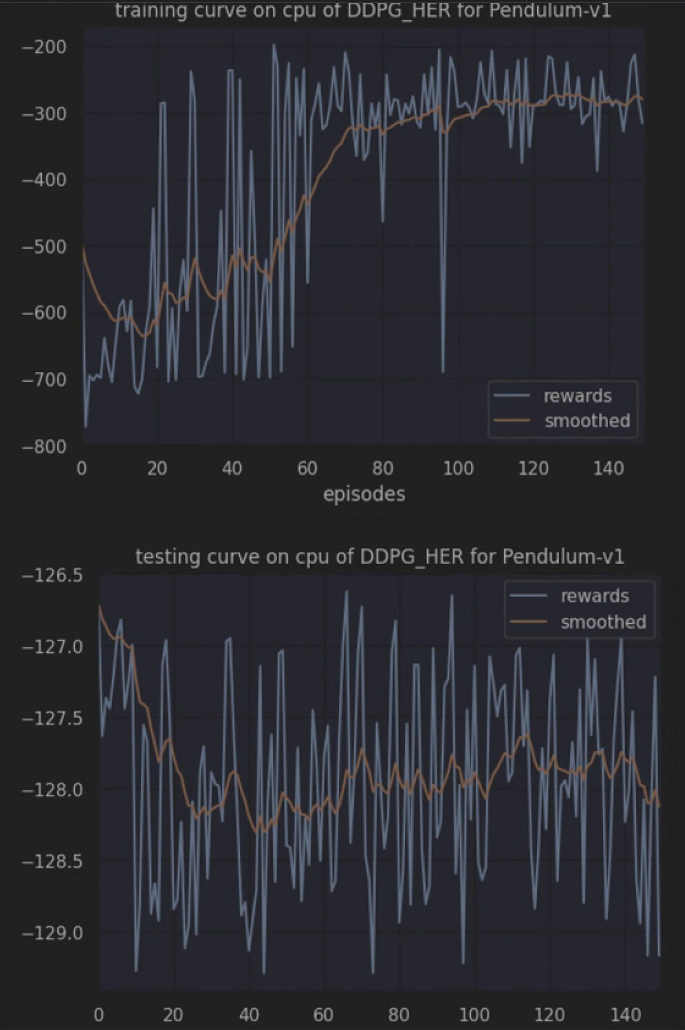
Task04:DDPG、TD3算法
本篇博客是本人参加Datawhale组队学习第四次任务的笔记 【教程地址】https://github.com/datawhalechina/joyrl-book 【强化学习库JoyRL】https://github.com/datawhalechina/joyrl/tree/main 【JoyRL开发周报】 https://datawhale.feishu.cn/docx/OM8fdsNl0o5omoxB5nXcyzsInGe…

人工智能AIGC培训讲师叶梓介绍及AI强化学习培训提纲
叶梓,上海交通大学计算机专业博士毕业,高级工程师。主研方向:数据挖掘、机器学习、人工智能。历任国内知名上市IT企业的AI技术总监、资深技术专家,市级行业大数据平台技术负责人。个人主页:大数据人工智能AI培训讲师叶…

Pytorch深度强化学习1-6:详解时序差分强化学习(SARSA、Q-Learning算法)
目录 0 专栏介绍1 时序差分强化学习2 策略评估原理3 策略改进原理3.1 SARSA算法3.2 Q-Learning算法 0 专栏介绍
本专栏重点介绍强化学习技术的数学原理,并且采用Pytorch框架对常见的强化学习算法、案例进行实现,帮助读者理解并快速上手开发。同时&#…

【深度学习】强化学习(四)强化学习的值函数
文章目录 一、强化学习问题1、交互的对象2、强化学习的基本要素3、策略(Policy)4、马尔可夫决策过程5、强化学习的目标函数6、值函数1. 状态值函数(State Value Function)a. 状态值函数的定义b. 贝尔曼方程(Bellman Eq…
强化学习中训练阶段和测试阶段的区别,在代码上是怎么体现的
强化学习中训练阶段和测试阶段的区别,在代码上是怎么体现的
在强化学习中,训练阶段和测试阶段有一些关键的区别。这主要涉及到探索与利用的平衡、环境交互、以及模型参数更新等方面。以下是训练阶段和测试阶段的主要区别以及在代码中可能如何体现&#…

深度强化学习Task3:A2C、A3C算法
本篇博客是本人参加Datawhale组队学习第三次任务的笔记 【教程地址】 文章目录 Actor-Critic 算法提出的动机Q Actor-Critic 算法A2C 与 A3C 算法广义优势估计A3C实现建立Actor和Critic网络定义智能体定义环境训练利用JoyRL实现多进程 练习总结 Actor-Critic 算法提出的动机
蒙…
深度强化学习(王树森)笔记07
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…
基于强化学习(Reinforcement learning,RL)的机器人路径规划MATLAB
一、Q-learning算法
Q-learning算法是强化学习算法中的一种,该算法主要包含:Agent、状态、动作、环境、回报和惩罚。Q-learning算法通过机器人与环境不断地交换信息,来实现自我学习。Q-learning算法中的Q表是机器人与环境交互后的结果&#…
强化学习的数学原理学习笔记 - 值函数近似(Value Function Approximation)
文章目录 概览:RL方法分类值函数近似(Value function approximation)Basic idea目标函数(objective function)优化算法(optimization algorithm) Sarsa / Q-learning with function approximati…
强化学习的数学原理学习笔记 - 基于模型(Model-based)
文章目录 概览:RL方法分类基于模型(Model-Based)值迭代(Value Iteration)🟦策略迭代(Policy Iteration)🟡截断策略迭代(Truncated Policy Iterationÿ…
机器学习、深度学习与强化学习区别
机器学习:Maching Learning,是实现人工智能的一种手段,也是目前被认为比较有效的实现人工智能的手段。目前在业界使用机器学习比较突出的领域很多,例如计算机视觉、自然语言处理、推荐系统、文本分类等,大家生活中经常…
机器学习笔记 - 通过人工干预实现安全强化学习的思路
1、人类干预强化学习 深度强化学习在一些棋类游戏、视频游戏以及现实3D环境中的导航和控制任务方面取得了惊人的进展。这些成就是在模拟环境中实现的。深度强化学习能否将这一成功转化为现实世界的任务? 这里面临两个主要问题。第一个是深度强化学习需要大量的观察(在现实世界…
网络结构搜索之强化学习
NVIDIA CEO Jen-Hsun Huang shows off the company’s latest and most advanced GPU yet.
深度学习模型性能的提升仰赖手工精细的调整。然而炼丹工作近似黑箱问题,可参照的纲领不多。显然,这不是程序员所期望的。算力和需求的增长使得神经架构搜索&…
深度学习进阶之路 - 从迁移学习到强化学习
一. 深度学习及其适用范围 大数据造就了深度学习,通过大量的数据训练,我们能够轻易的发现数据的规律,从而实现基于监督学习的数据预测。 没错,这里要强调的是基于监督学习的,也是迄今为止我在讲完深度学习基础所给出的…
强化学习(8):Asynchronous Advantage Actor-Critic(A3C)算法
本文主要讲解有关 A3C 算法的相关内容。 一、A3C 算法
直接引用莫烦老师的话来介绍 A3C 算法:Google DeepMind 提出的一种解决 Actor-Critic 不收敛问题的算法。它会创建多个并行的环境,让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参…
强化学习番外篇之 OpenAI-gym 环境的介绍和使用
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解有关 OpenAI gym 中怎么查看每个环境是做什么的,以及状态和动作有哪些可取的值,奖励值是什么样的。然后给出…
使用Panda-Gym的机器臂模拟进行Deep Q-learning强化学习
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体因采取行动导致预期结果而获得奖励,因采取行动导致预期结果而受到惩罚。随着时间的推移,代理学会采取行动,使其预期回报最大化。 RL代理通常使…

深度强化学习【1】-强化学习入门必备基础(含Python迷宫游戏求解实例)
强化学习入门必备基础 文章目录强化学习入门必备基础1. 强化学习与机器学习1.1 有监督学习1.2 半监督学习1.3 无监督学习1.4 强化学习1.5 深度学习2. 强化学习中的一些概念2.1 智能体、动作、状态2.2 策略函数、奖励2.3 状态转移2.4 智能体与环境的交互过程2.5 折扣奖励2.6 动作…
【强化学习】基于蒙特卡洛MC与时序差分TD的简易21点游戏应用
1. 本文将强化学习方法(MC、Sarsa、Q learning)应用于“S21点的简单纸牌游戏”。 类似于Sutton和Barto的21点游戏示例,但请注意,纸牌游戏的规则是不同且非标准的。 2. 为方便描述,过程使用代码截图,文末附链…
2. 分享三篇早期的FPGA 布局布线论文
1. PathFinder:一种基于协商和性能驱动的FPGA布线器
Larry MCMURCHIE, Carl EBELING. PathFinder: A Negotiation-Based Performance-Driven Router for FPGAs, February 1996[J/OL]. February 1996
针对FPGA布线中存在的布线性能与可布通性之间的矛盾,该文提出了…
强化学习(5):策略梯度(Policy Gradient, PG)算法
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解有关 Policy Gradient(PG)算法的相关内容。 之前提到的 Sarsa、Q-Learning 和 DQN 算法都是基于价值的方法…
【强化学习】循序渐进讲解Deep Q-Networks(DQN)
文章目录 1 Q-learning与Deep Q-learning2 DQN的结构组成3 DQN创新技术(重点)3.1 Experience Replay(经验回放)3.2 Fixed Q-Target(固定Q目标)3.3 Double Deep Q-Learning(双重深度Q学习方法&am…

【强化学习】Sarsa
【强化学习】相关基本概念【强化学习】 Q-Learning【强化学习】 Q-Learning 案例分析【强化学习】 Sarsa【强化学习】 Sarsa(lambda)Sarsa概述
首先可以回顾一下之前说的Q-Learning算法,Sarsa算法与Q-Learning算法很相似, Q-Lear…
深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[贝尔曼方程]
分类目录:《深入理解强化学习》总目录 在文章《深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[价值函数]》中,我们知道即时奖励的期望正是奖励函数的输出,即: E [ R t ∣ S s ] r ( s ) E[R_t|Ss]r(s) E[…
深入理解强化学习——多臂赌博机:10臂测试平台
分类目录:《深入理解强化学习》总目录 为了大致评估贪心方法和 ϵ − \epsilon- ϵ−贪心方法相对的有效性,我们将它们在一系列测试问题上进行了定量比较。这组问题是2000个随机生成的 k k k臂赌博机问题,且 k 10 k10 k10。在每一个赌博机问…
深入理解强化学习——多臂赌博机:基础知识
分类目录:《深入理解强化学习》总目录 强化学习与其他机器学习方法最大的不同,就在于前者的训练信号是用来评估给定动作的好坏的,而不是通过给出正确动作范例来进行直接的指导。这使得主动地反复试验以试探出好的动作变得很有必要。单纯的“评…

强化学习 - 策略梯度(Policy Gradient)
引言 强化学习常见的方法为基于值函数或者基于策略梯度。
值函数:值函数最优时得到最优策略,即状态s下,最大行为值函数maxQ(s,a)对应的动作。 但对于机器人连续动作空间,动作连续时,基于值函数,存在以下问…
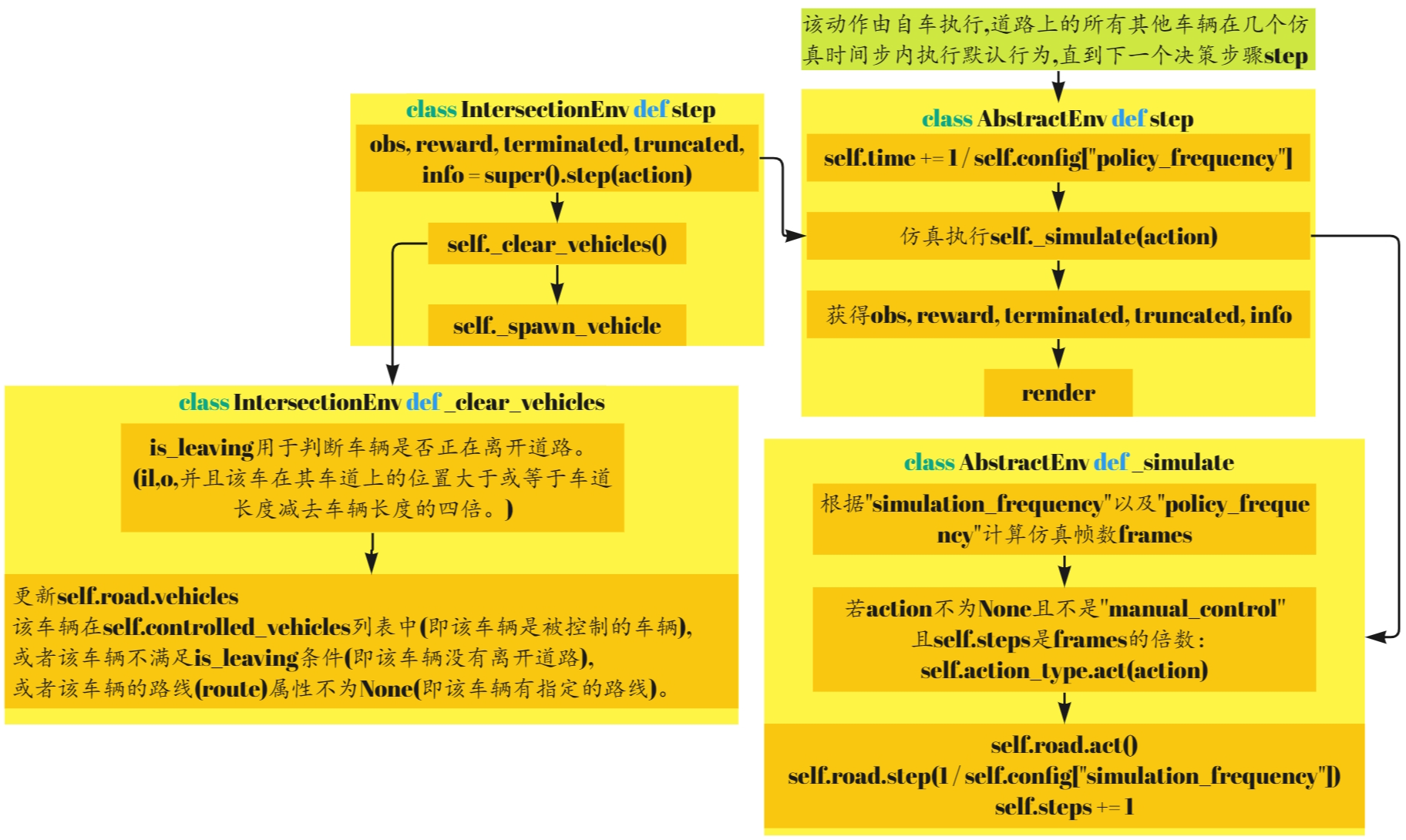
【Highway-env】IntersectionEnv代码阅读
文章目录 主要完成任务代码结构1.action space2.default_config3.reward_agent_rewards_agent_reward_reward_rewards小结 4.terminated & truncated5.reset_make_road_make_vehicles_spawn_vehicle 6.step 主要完成任务
IntersectionEnv继承自AbstractEnv,主要完成以下4个…
深入理解强化学习——多臂赌博机:基于置信度上界的动作选择
分类目录:《深入理解强化学习》总目录 因为对动作—价值的估计总会存在不确定性,所以试探是必须的。贪心动作虽然在当前时刻看起来最好,但实际上其他一些动作可能从长远看更好。 ϵ − \epsilon- ϵ−贪心算法会尝试选择非贪心的动作…
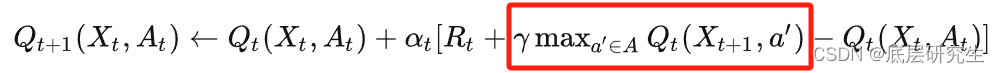
Reinforcement Learning(二)--on-policy和off-policy
1.前言
强化学习(Reinforcement learning,RL)是机器学习的一个分析,特点是概念多、公式多、入门门槛高🥲(别问我怎么知道的)。本篇文章着重讲解RL最重要的概念之一,即on-policy和of…

用强化学习神包trl轻松实现GPT2可控文本生成
来源:投稿 作者:Sally can wait 编辑:学姐 模型github: lvwerra/trl: Train transformer language models with reinforcement learning. (github.com)https://github.com/lvwerra/trl
这个项目是复现 ”Fine-Tuning Language Models from H…
深度强化学习(一)常识性普及
文章目录 机器学习、强化学习、深度学习的侧重点强化学习的简介强化学习的主要特征强化学习和机器学习的关系强化学习的发展历史 深度强化学习 一些参考的资料: 蘑菇书:https://datawhalechina.github.io/easy-rl/#/chapter1/chapter1 源代码:…
SAC代码 pytorch框架,2023年了还在用假的SAC?
呀他温,博主这次真要红温了,中路一个红温兰博请求对线!!!!!!
莫烦老师的强化学习视频不出SAC,我只能去看看别的程序员讲解SAC算法。结果。。。。
唉,&#…
![【强化学习】解决gym安装Atari2600环境gym[atari,accept-rom-license] RuntimeError 无法下载Roms的问题](https://img-blog.csdnimg.cn/18cea2fc087a455aa8bccdd1bd2996e8.png)
【强化学习】解决gym安装Atari2600环境gym[atari,accept-rom-license] RuntimeError 无法下载Roms的问题
先上Roms.tar.gz安装地址:Roms.tar.gz 以下内容是解决问题的思路,如果已经完全知道问题原因可以直接跳过 安装gym[accept-rom-license]时会出现安装失败的情况: 先是卡在:Building wheel for AutoROM.accept-rom-license 然后是显示安装失败…

Flappy Bird QDN PyTorch博客 - 代码解读
Flappy Bird QDN PyTorch博客 - 代码解读 介绍环境配置项目目录结构QDN算法重要函数解读preprocess(observation)DeepNetWork(nn.Module)BirdDQN类主程序部分 介绍
在本博客中,我们将介绍如何使用QDN(Quantile Dueling Network)算法…
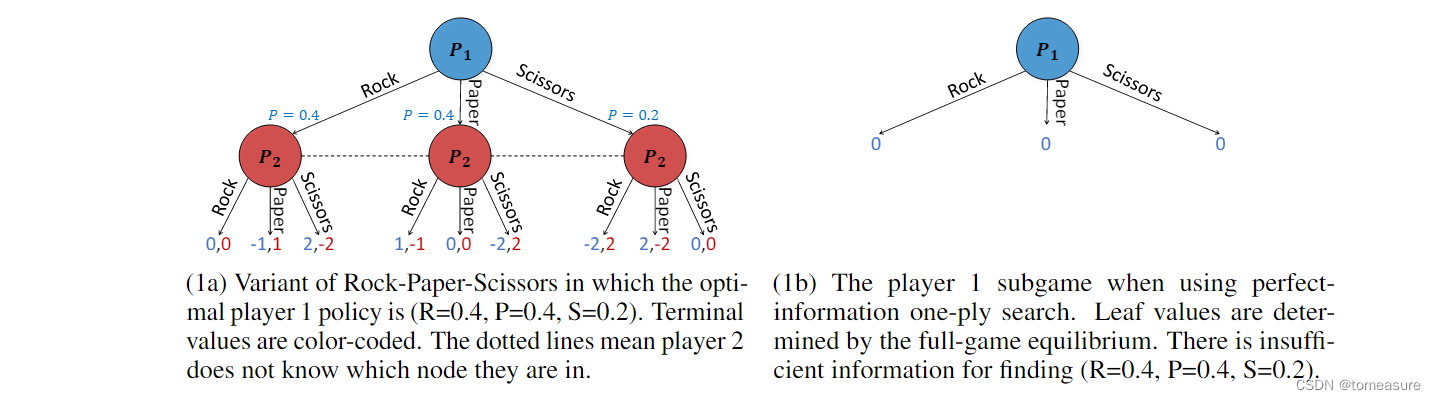
ReBel 论文学习笔记
论文:《Combining Deep Reinforcement Learning and Search for Imperfect-Information Games》 地址:https://arxiv.org/abs/2007.13544v2 代码:https://github.com/facebookresearch/rebel 材料:
BV1gt4y1k77C(1小时…
Python-DQN代码阅读(10)
目录 1.代码
1.1 代码阅读
1.2 代码分解
1.2.1 f open("experiments/" str(env.spec.id) "/performance.txt", "a")
1.2.2 f.write(str(ep) " " str(time_steps) " " str(episode_rewards) " " str(…

《强化学习:原理与Python实战》——可曾听闻RLHF
前言: RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)是一种基于强化学习的算法,通过结合人类专家的知识和经验来优化智能体的学习效果。它不仅考虑智能体的行为奖励,还融合了人类专家…

【百度PARL】强化学习笔记
文章目录 强化学习基本知识一些框架Value-based的方法Q表格举个例子 强化的概念TD更新 Sarsa算法SampleSarsa Agent类 On_policy vs off_policy函数逼近与神经网络DQN算法DQN创新点DQN代码实现model.pyalgorithm.pyagent.py总结:举个例子 实战 视频:世界…
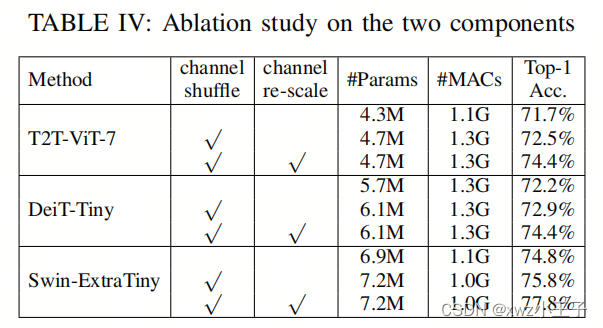
轻量化Backbone | ShuffleNet+ViT结合让ViT也能有ShuffleNet轻量化的优秀能力
视觉Transformer(ViTs)在各种计算机视觉任务中表现出卓越的性能。然而,高计算复杂性阻碍了ViTs在内存和计算资源有限的设备上的适用性。尽管某些研究已经深入探讨了卷积层与自注意力机制的融合,以增强ViTs的效率,但在纯…
深入理解强化学习——多臂赌博机:上下文相关的赌博机(关联搜索任务)
分类目录:《深入理解强化学习》总目录 《深入理解强化学习——多臂赌博机》系列文章到此为止,只考虑了非关联的任务,对它们来说,没有必要将不同的动作与不同的情境联系起来。在这些任务中,当任务是平稳的时候ÿ…

Lecture1 Welcome Stanford CS229 Machine Learning|2018 Autumn|吴恩达机器学习
1:15:20目录机器学习类比跳棋游戏,理解机器学习的概念:很多人坐在电脑旁玩游戏或跳棋好几天,这就是经验E;任务T是指下跳棋的任务;性能度量P可能是指在与下一个对手下棋时/在下一场跳棋中获胜的机会是多少?监…
[论文笔记]DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
引言
今天带来21年一篇关于用强化学习玩斗地主的论文:DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning。
斗地主是一个具有竞争、合作、信息不完全、状态空间庞大以及大量可能动作的极具挑战性的领域,尤其是合法动作在每一轮中变化显著。在这项工…
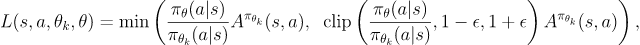
RL的体悟以及简单的算法介绍
本文将围绕着本人在接触rl后的各种问题,简单解答,顺便介绍各种算法。主要是给自己用做笔记,所以写得比较乱。
0、 可以参考的资料
openai的教程 这个讲得很棒,最好可以按照顺序读一遍
1、off policy / on policy?
off polic…
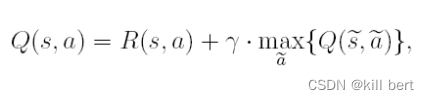
Sarsa VS Q-Learning
前言
1.如何计算价值函数?
为了使模型训练的最好,学习到更多有用的知识即完成任务的最好策略。对策略好坏的评价标准自然是得到最多最好的奖励,那么如何找到最好的最好的奖励,即如何得到最好的价值函数? 首先对于在状…

【机器学习并行计算】2 parameter server参数服务器
使用ps实现异步梯度下降。 14年提出的。 异步 vs 同步 可以看出异步运行效率非常高。
异步梯度下降的流程 ps架构流程 worker: 首先从参数服务器拉取最新的参数;然后用自己节点上的数据计算梯度;最后把梯度推给参数服务器参数服务器…
图解强化学习 原理 超详解 (一)
强化学习
一.背景
机器学习是人工智能的一个分支,在近30多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等的学科。强化学习(RL)作为机器学习的一个子领域,其灵感来源于心理学中的行为主义理论&#x…

【强化学习】常用算法之一 “SARSA”
作者主页:爱笑的男孩。的博客_CSDN博客-深度学习,活动,python领域博主爱笑的男孩。擅长深度学习,活动,python,等方面的知识,爱笑的男孩。关注算法,python,计算机视觉,图像处理,深度学习,pytorch,神经网络,opencv领域.https://blog.csdn.net/Code_and516?typeblog个…

莫烦强化学习-Q Learning
参考链接: https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/intro-q-learning/ 第2章 Q-learning
强化学习中有名的算法,Q-learning。由第一章可知,Q-learning的分类是model-free,基于价值,单…

图解强化学习 原理 超详解 (二)
上一篇博客中,我们讲解了 强化学习的 概念定义,以及详细全面的讲述了马尔可夫过程,这一篇我们将讲述马尔可夫决策过程所涉及到的策略优化及相关概念。
四.策略优化
马尔可夫决策过程对环境进行了描述,那么智能主体如何完成与环境…
策略梯度算法简明教程
为什么需要策略梯度
基于值的强化学习方法一般是确定性的,给定一个状态就能计算出每种可能动作的奖励(确定值),但这种确定性的方法无法处理一些现实的问题,比如玩100把石头剪刀布的游戏,最好的解法是随机的…
深入理解强化学习——强化学习的目标和数据
分类目录:《深入理解强化学习》总目录 强化学习的目标
在动态环境下,智能体和环境每次进行交互时,环境会产生相应的奖励信号,其往往由实数标量来表示。这个奖励信号一般是诠释当前状态或动作的好坏的及时反馈信号,好比…
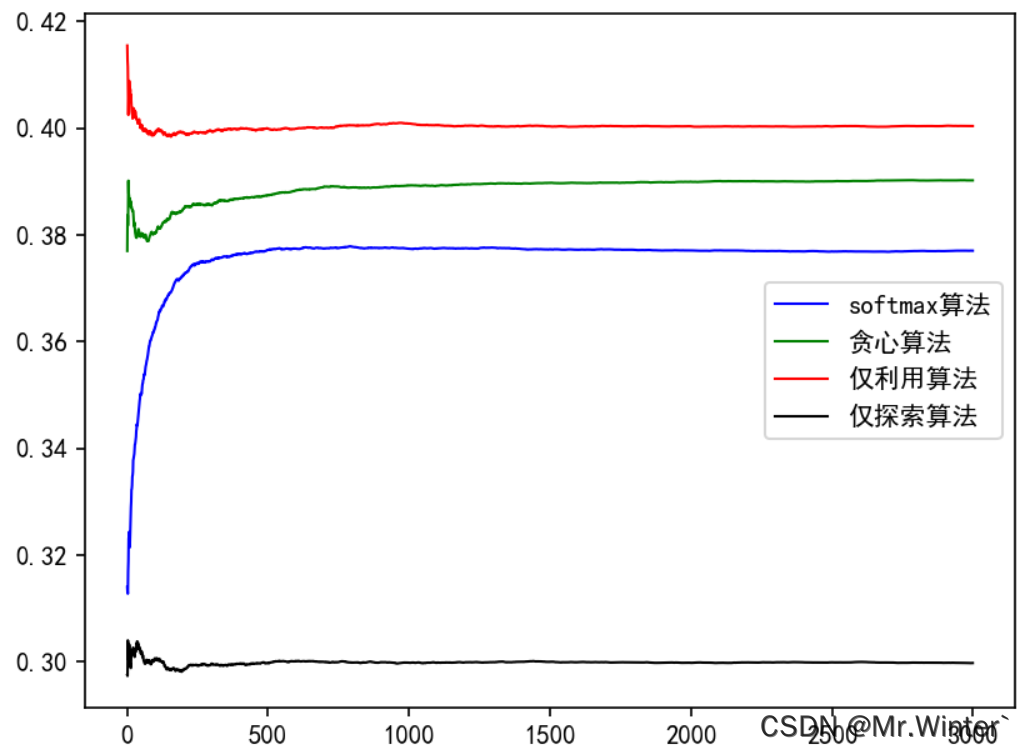
Pytorch深度强化学习(3):详解K摇臂赌博机模型和ϵ-贪心算法
目录 1 K-摇臂赌博机2 ϵ \epsilon ϵ-贪心算法3 softmax算法4 Python实现与分析 1 K-摇臂赌博机
单步强化学习是最简单的强化学习模型,其以贪心策略为核心最大化单步奖赏
如图所示,单步强化学习的理论模型是 K K K-摇臂赌博机( K K K-armed bandit)&…

使用强化学习快速让AI学会玩贪食蛇游戏(轻量级二十分钟训练+代码)
如何让AI玩会贪食蛇,甚至比你厉害概述构建问题(强化学习求解的一般步骤)环境动作定义状态定义奖励设计训练奖励值收敛图采用第4种状态定义方法初步训练效果最终训练效果模型泛化迁移能力代码概述
所用技术:强化学习(Deep Reinforcement Learning)&#…
强化学习MATLAB代码实现
强化学习MATLAB代码实现 目录倒立摆代码实现倒立摆代码实现
代码如下(MATLAB):
mdl rlSimplePendulumModel;
open_system(mdl)
env rlPredefinedEnv(SimplePendulumModel-Discrete);
env.ResetFcn (in)setVariable(in,theta0,pi,Workspa…
深入理解强化学习——强化学习和有监督学习
分类目录:《深入理解强化学习》总目录 通过前文的介绍,我们现在应该已经对强化学习的基本数学概念有了一定的了解。这里我们回过头来再看看一般的有监督学习和强化学习的区别。以图片分类为例,有监督学习(Supervised Learning&…
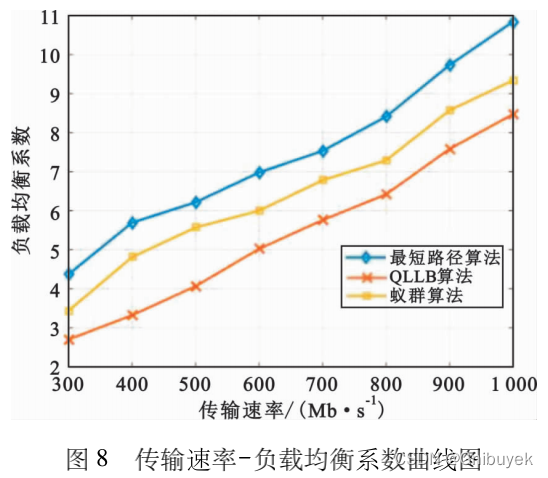
论文阅读六:软件定义网络中基于Q-学习的负载均衡算法
名词解释:
Q-learning Load Balance, QLLB:基于Q-学习的负载均衡算法
Link Layer Discovery Protocol, LLDP:链路层发现协议
摘要:针对SDN的负载均衡问题,为使网络的资源分配更加合理,防止网络拥塞&…

深入理解强化学习——强化学习智能体的四要素:策略(Policy)
分类目录:《深入理解强化学习》总目录 相关文章: 强化学习智能体的四要素:策略(Policy) 强化学习智能体的四要素:收益信号(Revenue Signal) 强化学习智能体的四要素:价…
强化学习 V.S. 自然语言处理,计算机保研er应该选哪个?
写在前面
人工智能是21世纪对人类影响最大的技术之一。人工智能,就是像人一样的智能,而人的智能包括感知、决策和认知(从直觉到推理、规划、意识等)。
其中,感知解决what,在机器学习和深度学习技术的推动下,各行各业的AI应用得到…
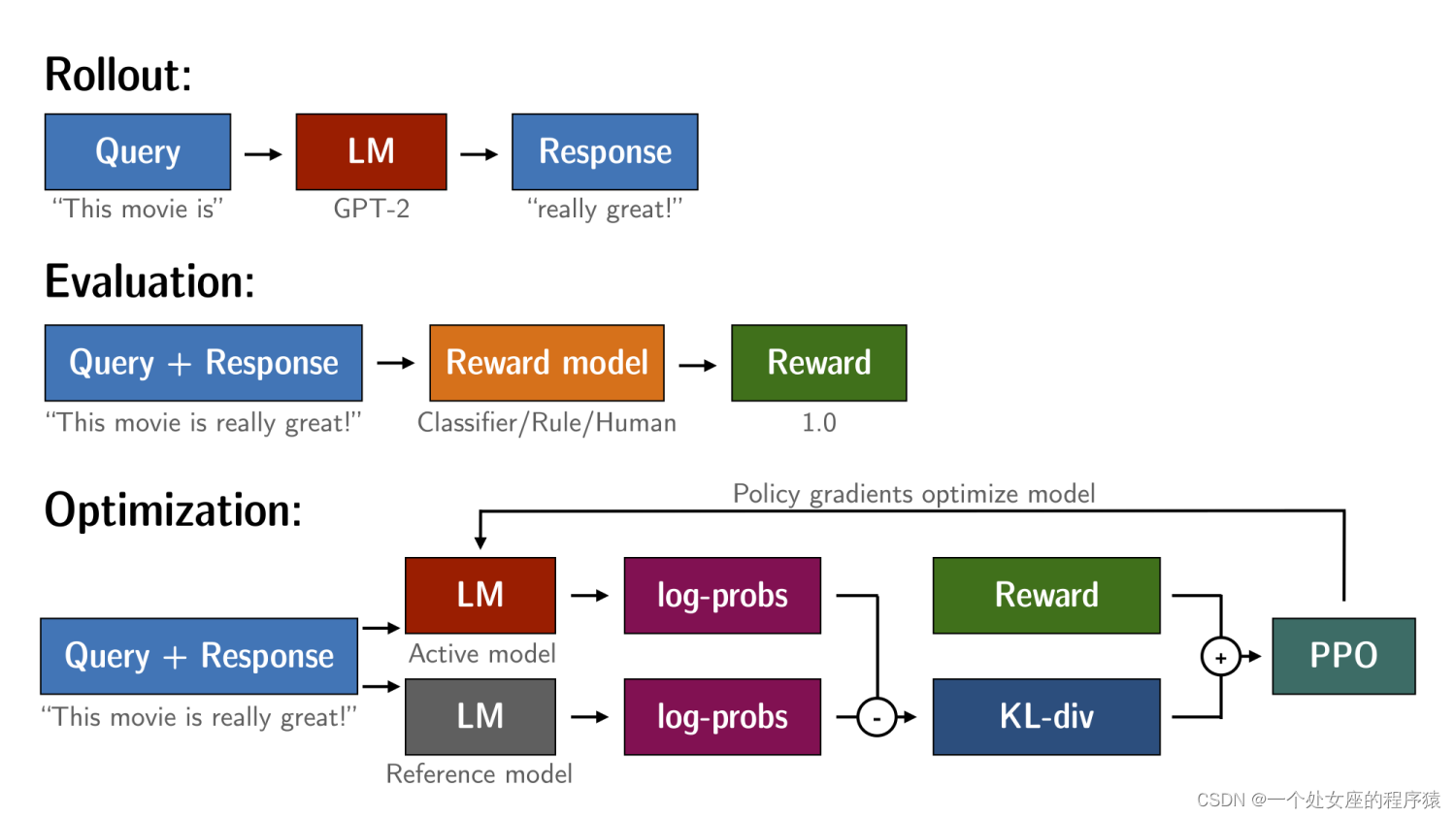
Py之trl:trl(一款采用强化学习训练Transformer语言模型和稳定扩散模型的全栈库)的简介、安装、使用方法之详细攻略
Py之trl:trl(一款采用强化学习训练Transformer语言模型和稳定扩散模型的全栈库)的简介、安装、使用方法之详细攻略 目录
trl的简介
1、亮点
2、PPO是如何工作的:PPO对语言模型微调三步骤,Rollout→Evaluation→Optimization
trl的安装
t…
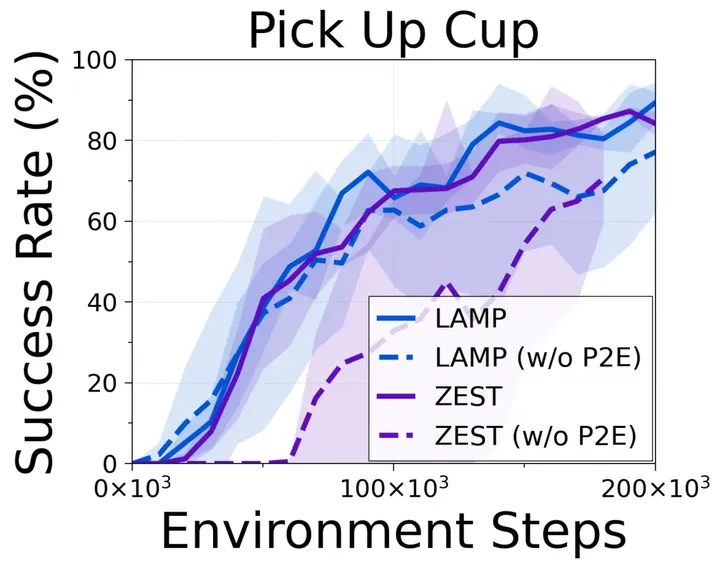
强化学习与视觉语言模型之间的碰撞,UC伯克利提出语言奖励调节LAMP框架
文章链接: https://arxiv.org/abs/2308.12270 代码仓库: https://github.com/ademiadeniji/lamp 在强化学习(RL)领域,一个重要的研究方向是如何巧妙的设计模型的奖励机制,传统的方式是设计手工奖励函数&…
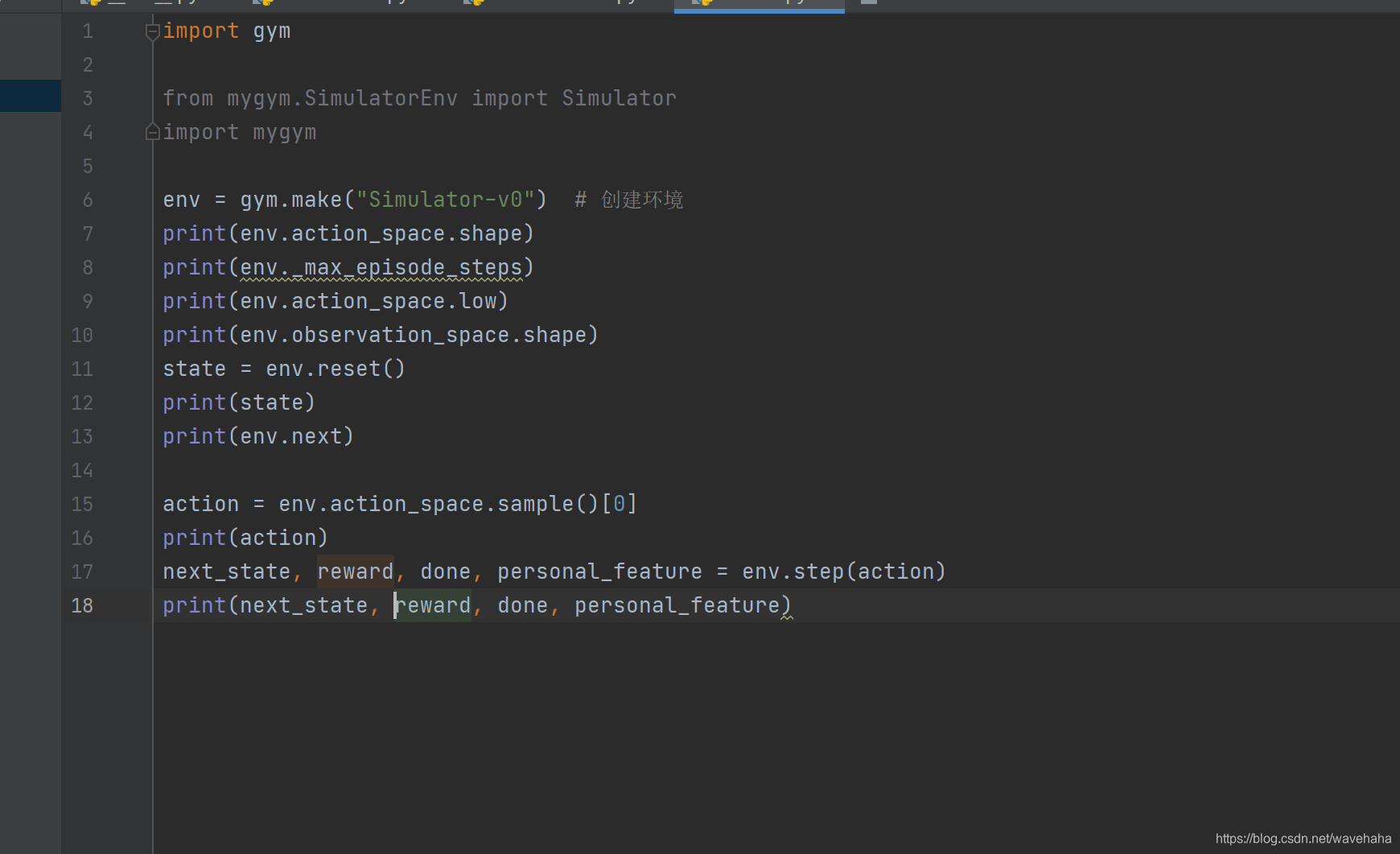
如何注册强化学习测试使用gym仿真环境
如何注册强化学习测试使用gym仿真环境
1、OpenAI Gym是训练强化学习时经常使用的仿真环境,利用python的gym库就可以使用,安装:pip install gym 2、注册环境,有时训练模型时需要自己的环境,可以自行注册。代码结构如图…
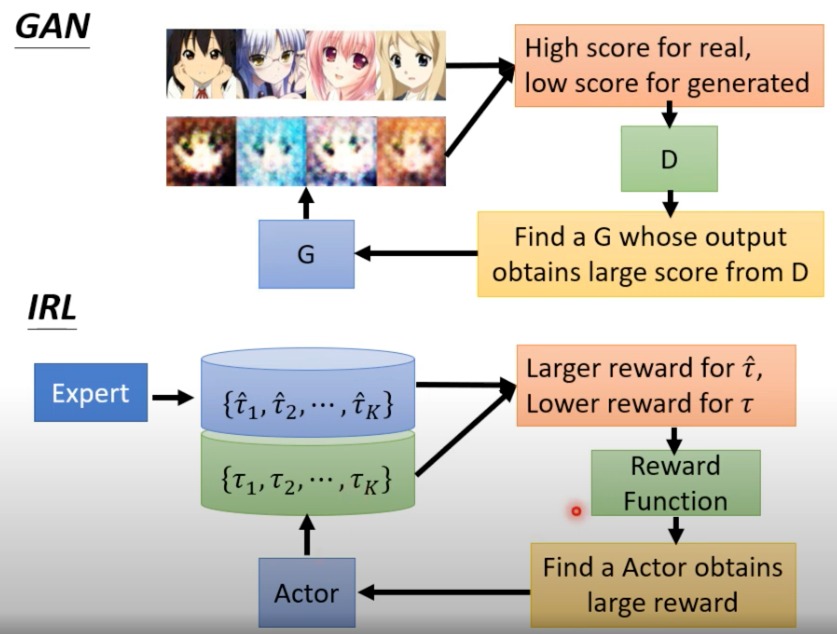
Learning to summarize from human feedback
Abstract 人工参考总结以及 ROUGE 指标只是我们真实关心的目标(总结质量)的粗略代表。通过优化人工偏好来显著提升总结质量使用大量高质量的人类比较来训练一个模型来预测人类偏好的总结使用这个模型作为奖励函数对总结策略进行强化学习微调我们模型的效果在 TL;DR 数据集上显…

【强化学习论文合集】ICML-2021 强化学习论文
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现…

【强化学习】17 ——DDPG(Deep Deterministic Policy Gradient)
文章目录 前言DDPG特点 随机策略与确定性策略DDPG:深度确定性策略梯度伪代码代码实践 前言
之前的章节介绍了基于策略梯度的算法 REINFORCE、Actor-Critic 以及两个改进算法——TRPO 和 PPO。这类算法有一个共同的特点:它们都是在线策略算法,…
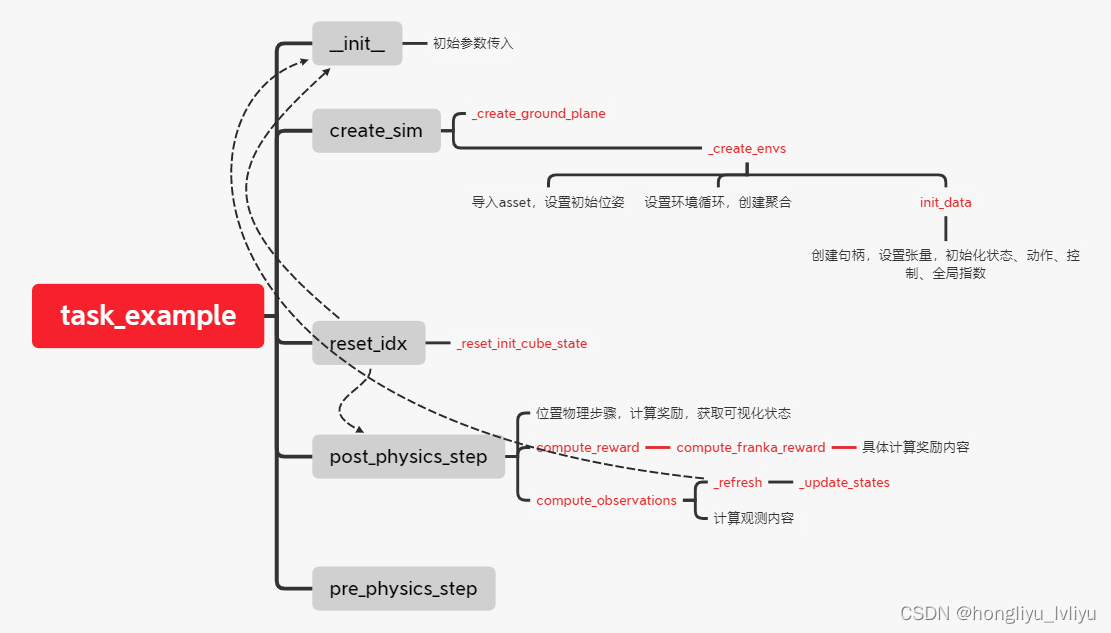
Isaac-gym(9):项目更新、benchmarks框架梳理
一、项目更新
近期重新git clone isaac gym的强化部分(具体见系列第5篇)时发现官方的github库有跟新,git clone下来后发现多了若干个task,在环境配置上也有一定区别。 例如新旧两版工程项目的setup.py区别如下: git …
深度强化学习调参技巧
在深度强化学习中,调参是一个非常重要的任务,它直接影响到模型的性能和收敛速度。下面是一些常用的深度强化学习调参技巧: 选择合适的环境和任务: 首先要确保选择的环境和任务适合深度强化学习。不同的环境和任务对算法的表现有着不同的要求,因此需要根据具体情况选择合适…
【深度强化学习】(3) Policy Gradients 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下基于策略的深度强化学习方法,策略梯度法是对策略进行建模,然后通过梯度上升更新策略网络的参数。我们使用了 OpenAI 的 gym 库,基于策略梯度法完成了一个小游戏。完整代码可以从我的 GitHub 中获得&…

强化学习在文生图中的应用:Training Diffusion Models with Reinforcement Learning
论文链接:Training Diffusion Models with Reinforcement Learning项目地址:Training Diffusion Models with Reinforcement Learning官方代码:https://github.com/kvablack/ddpo-pytorch/tree/maintrl实现:https://huggingface.co/docs/trl/ddpo_trainer🤗关注公众号 fu…

【强化学习】Deep Q Learning
Deep Q Learning
在前两篇文章中,我们发现RL模型的目标是基于观察空间 (observations) 和最大化奖励和 (maximumize sum rewards) 的。
如果我们能够拟合出一个函数 (function) 来解决上述问题,那就可以避免存储一个 (在Double Q-Learning中甚至是两个…

西湖大学的强化学习数学原理视频学习总结
断断续续在B站把西湖大学邵老师的‘【强化学习的数学原理】课程:从零开始到透彻理解’看完了,感觉非常棒的一门课程视频,涉及了一些基础的数学定理,也很多细节,用起来可以直接用,但如果不懂得整个脉络&…
强化学习稀疏奖励问题(sparse reward)及解决方法
参考 《EasyRL》
1.稀疏奖励
通常在训练智能体时,我们希望每一步动作都有相应的奖励。但是某些情况下,智能体并不能立刻获得奖励,比如全局奖励的围棋,最终获胜会得到奖励,但是人们很难去设定中间每步的奖励ÿ…
Python-DQN代码阅读(9)
目录 1.代码阅读
1.1 代码总括
1.2 代码分解
1.2.1 replay_memory.pop(0)
1.2.2 replay_memory.append(Transition(state, action, reward, next_state, done))
1.2.3 samples random.sample(replay_memory, batch_size)
1.2.4 q_values_next target_net.predict(sess,…
Python-DQN代码阅读(7)
目录 1.代码
1.1设置ε值
代码总括
代码分解
1.2 设置时间步长总数
1.3主循环贯穿整个回合
1.4跟踪时间步长
1.5更新目标网络 1.代码
1.1设置ε值
代码总括
# epsilon start
if (train_or_test train):# 计算训练初期和训练后期的 epsilon 值的差值delta_epsilon1 …
Python-DQN代码阅读(11)
1.代码
1.1代码阅读
tf.compat.v1.reset_default_graph() # 重置 TensorFlow 的默认计算图# Q 和 target 网络
q_net QNetwork(scope"q", VALID_ACTIONSVALID_ACTIONS) # 创建 Q 网络
target_net QNetwork(scope"target_q", VALID_ACTIONSVALID_ACTI…

Science | 华盛顿大学Baker团队提出AI新范式设计全新蛋白复合物
蛋白质的结构形态和生物学功能是由氨基酸序列决定的。 人工蛋白质设计的目标就是创造可以折叠成特定结构以实现特定功能的新型氨基酸序列。 当然,这并不是一个简单的问题,因为它需要了解蛋白质如何在细胞中折叠,而这一过程在很大程度上仍不为…

论文解析-基于 Unity3D 游戏人工智能的研究与应用
1.重写 AgentAction 方法
1.1 重写 AgentAction 方法 这段代码是一个重写了 AgentAction 方法的方法。以下是对每行代码解释:
①public override void AgentAction(float[] vectorAction)
这行代码声明了一个公共的、重写了父类的 AgentAction 方法的方法。它接受…

MADDPG-学习笔记(1)
文献链接:https://arxiv.org/abs/1706.02275
"Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments"(作者:Lowe, Ryan等人,2017年)
环境搭建:https://zhuanlan.zhihu.co…

David Silver Lecture 9:Exploration and Exploitation
1 Introduction
1.1 Outline
1.1.1 Exploration vs. Exploitation Dilemma 1.1.2 examples 1.1.3 principles Naive Exploration 在前面的章节主要使用的是naive exploration的方法Optimistic Initialisation 这种方法的思想是,我们对每个动作的奖励给出一个乐观的…

小试牛刀:应用深度强化学习优化文本摘要思路及在裁判文书摘要上的实践效果
一、引言
近期,随着大模型的出现,强化学习再一次的引起了本人的兴趣,本文将应用深度强化学习来优化文本摘要模型,使生成的摘要更加的流畅。在此之前,大家都采用了很多种方式训练摘要系统,例如:…
《Reinforcement Learning: An Introduction》第1章笔记
文章目录 1.1 强化学习1.2 强化学习的例子1.3 强化学习的要素1.4 局限和范围1.5 拓展例子:井字游戏1.6 总结1.7 强化学习的早期历史参考资料 1.1 强化学习
强化学习是学习做什么—如何将情景映射到动作—以便最大化数字奖励信号。学习者不会被告知该采取什么动作&a…

强化学习系列之Policy Gradient算法
一. 背景
1.1 基础组成部分 强化学习里面包含三个部件:Actor,environment,reward function Actor : 表示角色,是能够被玩家控制的。 Policy of Actor:在人工智能中,Policy π \pi π 可以表示为一个神经网络,参数为 θ \theta

基于深度强化学习的目标驱动型视觉导航泛化模型
深度强化学习在目标驱动型视觉导航的泛化
参考论文《Towards Generalization in Target-Driven Visual Navigation by Using Deep Reinforcement Learning》 文章目录 深度强化学习在目标驱动型视觉导航的泛化1. 目标驱动型视觉导航问题2. 创新点和解决的问题2.1 创新点2.2 解…

强化学习Q-learning实践
1. 引言
前篇文章介绍了强化学习系统红的基本概念和重要组成部分,并解释了Q-learning算法相关的理论知识。本文的目标是在Python3中实现该算法,并将其应用于实际的实验中。 闲话少说,我们直接开始吧!
2. Taxi-v3 Env
为了使本文…

强化学习笔记-0910 On-policy Method with Approximation
前几章我们所讨论的强化学习方法都是将价值函数建模为一个table形式,通过状态来查询具体状态的价值。但是当状态-动作空间极大,且多数状态-动作并没有太大意义时,这种table查询效率是极低的。
因此本节是将价值函数建模为一个参数模型&#…

强化学习笔记-12 Eligibility Traces
前篇讨论了TD算法将MC同Bootstrap相结合,拥有很好的特性。本节所介绍的Eligibility Traces,其思想是多个TD(n)所计算预估累积收益按权重进行加权平均,从而得到更好的累积收益预估值。 价值预估模型的参数更新式子可以调整为: 1. O…
【深度强化学习】TRPO、PPO
策略梯度的缺点 步长难以确定,一旦步长选的不好,就导致恶性循环 步长不合适 → 策略变差 → 采集的数据变差 → (回报 / 梯度导致的)步长不合适 步长不合适 \to 策略变差 \to 采集的数据变差 \to (回报/梯度导致的&am…
一文打通RLHF的来龙去脉
文章目录 1. RLHF的发展历程2. 强化学习2.1 强化学习基本概念2.2 强化学习分类2.3 Policy Gradient2.3.1 add a baseline2.3.2 assign suitable credit2.4 TRPO和PPO算法2.4.1 on-policy2.4.2 Important Sampling2.4.3 Off Policy2.4.4 TRPO 和 PPO 算法2.4.5 P

【强化学习】PPO:近端策略优化算法
近端策略优化算法 《Proximal Policy Optimization Algorithms》 论文地址:https://arxiv.org/pdf/1707.06347.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架 【强化学习】PPO:近端策略优化算法 一、 置…
20. 完整的蒙特卡洛强化学习算法
文章目录 1. 回顾2. 约定3. MC强化学习环境对象的表示4.MC强化学习算法的表示5. MC方法的进一步分类 1. 回顾
第16篇给出了强化学习算法框架,随后的第17、18篇给出了该框架下如何进行策略评估以估计出Q ( s , a ) (s,a) (s,a),第19篇给出了该框架下如何…
19. 蒙特卡洛强化学习之策略控制
文章目录 1. MC学习中的策略控制是什么2. 基于贪心算法的策略改进的基本描述3.MC学习中完全使用贪心算法可行否4. 如何改进完全贪心算法5. 何谓 ε − \varepsilon- ε−贪心算法5.1 基本思想5.2 基于 ϵ − 贪心算法 \epsilon-贪心算法 ϵ−贪心算法的策略控制的形式化描述5.3…
【基础知识】DPO(Direct Preference Optimization)的原理以及公式是怎样的?
论文:Direct Preference Optimization: Your Language Model is Secretly a Reward Model 1.基本原理
DPO(Direct Preference Optimization)的核心思想是直接优化语言模型(LM)以符合人类偏好,而不是首先拟…

【强化学习】09——价值和策略近似逼近方法
文章目录 前言对状态/动作进行离散化参数化值函数近似值函数近似的主要形式Incremental MethodsGradient DescentLinear Value Function ApproximationFeature Vectors特征化状态Table Lookup Features Incremental Prediction AlgorithmsMonte-Carlo with Value Function Appr…
【强化学习】08——规划与学习(采样方法|决策时规划)
文章目录 优先级采样Example1 Prioritized Sweepingon Mazes局限性及改进 期望更新和采样更新不同分支因子下的表现 轨迹采样总结实时动态规划Example2 racetrack 决策时规划启发式搜索Rollout算法蒙特卡洛树搜索 参考 先做个简单的笔记整理,以后有时间再补上细节
…

基于强化学习的五子棋算法设计-python代码完整实现
目录
1 课程设计目的
2 设计任务与要求
3 设计原理
3.1 强化学习
3.2 蒙特卡洛树搜索
4 模型介绍
4.1 模拟
4.2 走子
4.3 神经网络
5 仿真过程与结果
参考资料 可以直接运行的源码下载地址:https://download.csdn.net/download/weixin_43442778/15877803 …
史上最全的冲压模具资料
一、弹簧的压缩量和计算
在一套冲压模具中,需要用到比较多的弹性材料,其中包括各种不同规格的弹簧、优力胶、氮气弹簧等,按照不同的需要选用不同的弹性材料。像折弯、冲孔一般用普通的扁线弹簧就可以了,比如棕色弹簧,…

基于Qlearning强化学习的路径规划算法matlab仿真
目录
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1 Q值更新规则
4.2 基于Q-learning的路径规划算法设计
4.3 Q-learning路径规划流程
5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本
MATLAB2022A
3.部分核心程序
..…
深入理解强化学习——马尔可夫决策过程:状态价值函数
分类目录:《深入理解强化学习》总目录 我们用 V ∗ ( s ) V^*(s) V∗(s)表示在马尔可夫决策过程中基于策略 π \pi π的状态价值函数(State-value Function),定义为从状态 s s s出发遵循策略 π \pi π能获得的期望回报࿰…
【Hung-Yi Lee】强化学习笔记
文章目录 What is RLPolicy GradientPolicy Gradient实际是怎么做的On-policy v.s. Off-policyExploration配音大师 Actor-Critic训练value function的方式网络设计DQN Reward ShapingNo Reward:Learning from Demonstration What is RL 定义一个策略网络࿰…

学习深度强化学习---第3部分----RL蒙特卡罗相关算法
文章目录 3.1节 蒙特卡罗法简介3.2节 蒙特卡罗策略评估3.3节 蒙特卡罗强化学习3.4节 异策略蒙特卡罗法 本部分视频所在地址:深度强化学习的理论与实践
3.1节 蒙特卡罗法简介
在其他学科中的蒙特卡罗法是一种抽样的方法。 如果状态转移概率是已知的,则是…
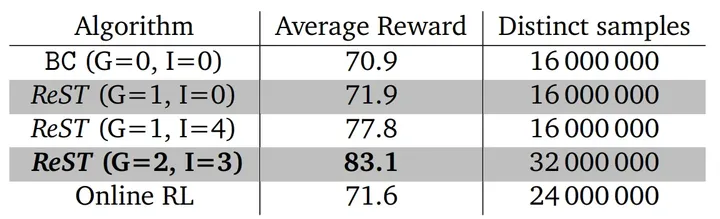
大模型RLHF算法更新换代,DeepMind提出自训练离线强化学习框架ReST
文章链接: https://arxiv.org/abs/2308.08998 大模型(LLMs)爆火的背后,离不开多种不同基础算法技术的支撑,例如基础语言架构Transformer、自回归语言建模、提示学习和指示学习等等。这些技术造就了像GPT-3、PaLM等基座…
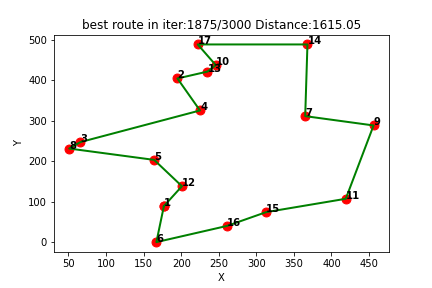
强化学习应用(六):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…
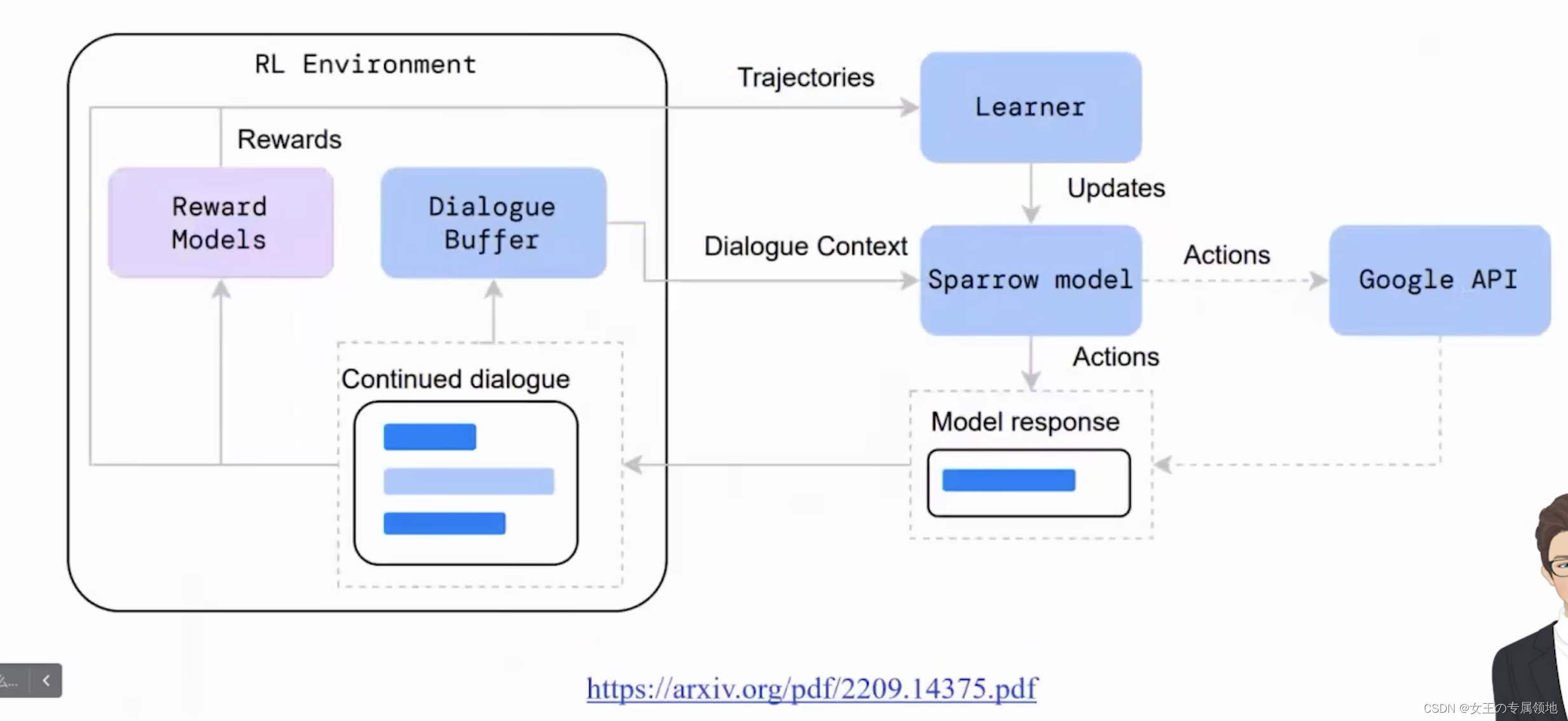
一文读懂「RLHF,Reinforcement Learning from Human Feedback」基于人类反馈的进行强化学习
一、背景由来
过去几年里,以ChatGPT为代表的基于prompt范式的大型语言模型 (Large Language Model,LLM) 取得了巨大的成功。然而,对生成结果的评估是主观和依赖上下文的,这些结果难以用现有的基于规则的文本生成指标 (如 BLUE 和…

每公里配速9分18秒,双足机器人完成5公里慢跑
内容描述:俄勒冈州立大学的 Cassie 在 53 分钟里完成了一段五公里慢跑,刷新了双足机器人的运动记录。 近日,来自美国俄勒冈州立大学的知名机器人研究团队 Agility Robotics 打造的双足机器人 Cassie ,耗时 53 分钟完成了一段 5 公…
Python-DQN代码阅读-填充回放记忆(replay memory)
1.代码
def populate_replay_mem(sess, env, state_processor, replay_memory_init_size, policy, epsilon_start, epsilon_end, epsilon_decay_steps, VALID_ACTIONS, Transition):"""填充回放记忆(replay memory)的函数参数࿱…
Python-DQN代码阅读(6)-dpn.py
目录 1.代码
(1)导入所需要的包
(2)设置游戏并选择有效的操作
(3)设置模式(train/test)和开始迭代
(4)创建环境
代码总括:
代码分解:
(5&a…

强化学习原理及应用作业之动态规划算法【SYSU_2023SpringRL】
强化学习原理及应用作业之动态规划算法【SYSU_2023SpringRL】 题目描述:任务一:动态规划方法一、策略迭代算法1、代码2、结果3、思路讲解策略评估策略提升二、价值迭代算法1、代码2、结果3、思路讲解算法整个流程总结题目描述:
本次实践作业将在以下环境进行: 该环境由一…
Unity-ML-Agents-代码解读-RollerBall
使用版本:https://github.com/Unity-Technologies/ml-agents/releases/tag/release_19
文件路径:ml-agents-release_19/docs/Learning-Environment-Create-New.md
20和19的在rollerBall上一样:https://github.com/Unity-Technologies/ml-ag…

强化学习笔记-06 Temporal-Difference TD时分学习
本文是博主对《Reinforcement Learning- An introduction》的阅读笔记,不涉及内容的翻译,主要为个人的理解和思考。 TD学习是现代强化学习方法的核心,其是蒙特卡罗法和动态规划法的结合,一方面,其同蒙特卡罗法一样&…
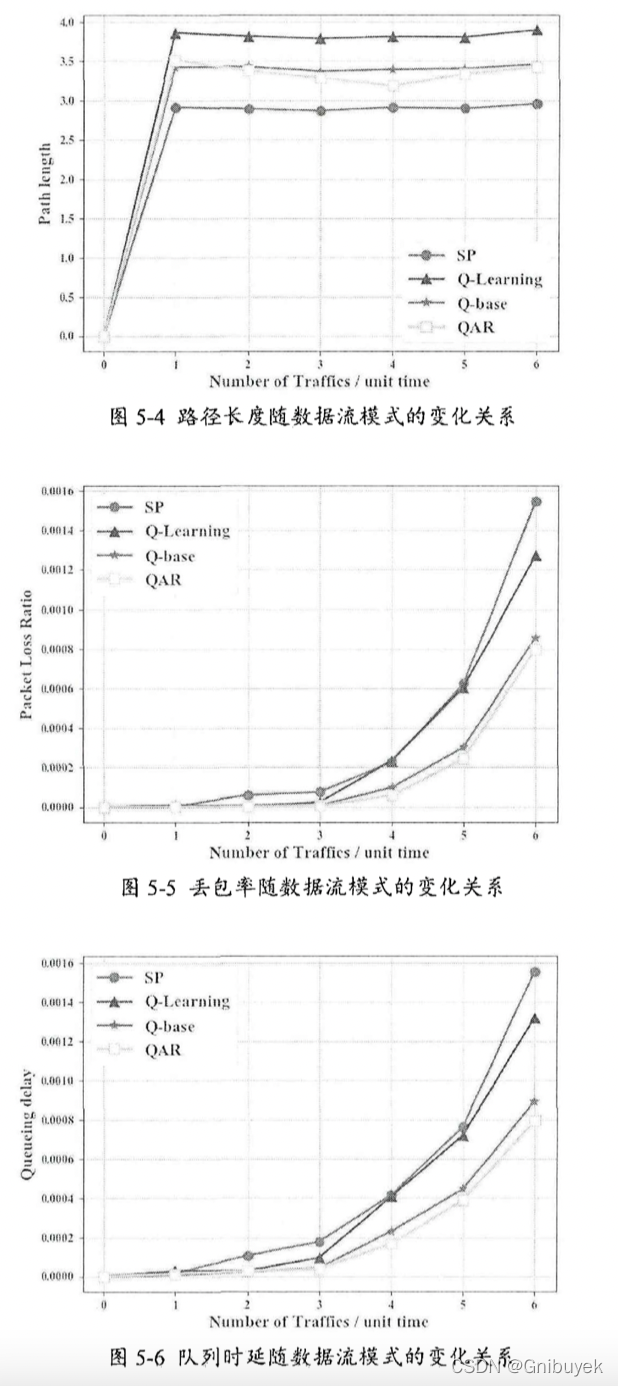
论文阅读七:面向软件定义网络的负载均衡智能路由策略
名词解释:
Machine Learning Aided Load Balance Routing Scheme Considering Queue Utilization, MLQU:考虑队列利用率的基于机器学习的负载均衡路由算法
QoS-oriented Adaptive Routing Scheme Based on Deep Reinforcement Learning, QAR࿱…

【Arxiv 2021】《 Putting Humans in the Natural Language Processing Loop: A Survey》阅读笔记
英文标题:Putting Humans in the Natural Language Processing Loop: A Survey 中文翻译:调查报告:将人类置于自然语言处理循环中 原文链接: https://arxiv.org/pdf/2103.04044.pdf. 文章目录Abstract1. Introduction本文的创新点:…

图解强化学习 原理 超详解 (三)
上一篇博客中 我们讲述了马尔可夫决策过程中的策略优化及相关问题,在这一篇博客中我们将讲述Q-learn方法,以及深度强化学习的相关概念
六.Q-learn
QLearning是强化学习算法中value-based的算法,Q即为Q(s,a)就是在某一…
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)。 MedicalGPT: Training Your Own Medical GPT Model with ChatGPT Training Pipeline. 训练医疗大模型,实现了包括增量预训练、有监督微…

强化学习(一):简介——什么是强化学习?
本文将介绍强化学习的基本含义,了解什么是强化学习、强化学习的概念与基本框架以及强化学习中常见的问题类型。
什么是强化学习? 强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,…


马尔科夫过程,马尔科夫奖励过程和马尔科夫决策过程
马尔科夫决策过程是强化学习中的一个基本框架,用来表示agent与环境的交互过程:agent观测得到环境的当前状态之后,采取动作,环境进入下一个状态,agent又得到下一个环境状态的信息,形成一个循环回路。 在理解…
深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[计算马尔可夫奖励过程价值的蒙特卡洛方法]
分类目录:《深入理解强化学习》总目录 文章《[深入理解强化学习——马尔可夫决策过程:马尔可夫奖励过程-[贝尔曼方程]]](https://machinelearning.blog.csdn.net/article/details/134407229)》介绍了计算马尔可夫奖励过程价值的解析方法,但解…

深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明
分类目录:《深入理解强化学习》总目录 通过将梯度赌博机算法理解为梯度上升的随机近似,我们可以深人了解这一算法的本质。在精确的梯度上升算法中,每一个动作的偏好函数 H t ( a ) H_t(a) Ht(a)与增量对性能的影响成正比: H t …

MAPPO 算法的深度解析与应用和实现
【论文研读】 The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games
说明:
来源:36th Conference on Neural Information Processing Systems (NeurIPS 2022) Track on Datasets and Benchmarks. 是NIPS文章,质量有保障&…

Pytorch深度强化学习案例:基于Q-Learning的机器人走迷宫
目录 0 专栏介绍1 Q-Learning算法原理2 强化学习基本框架3 机器人走迷宫算法3.1 迷宫环境3.2 状态、动作和奖励3.3 Q-Learning算法实现3.4 完成训练 4 算法分析4.1 Q-Table4.2 奖励曲线 0 专栏介绍
本专栏重点介绍强化学习技术的数学原理,并且采用Pytorch框架对常见…

RL 实践(7)—— CartPole【TPRO PPO】
本文介绍 PPO 这个 online RL 的经典算法,并在 CartPole-V0 上进行测试。由于 PPO 是源自 TPRO 的,因此也会在原理部分介绍 TPRO参考:张伟楠《动手学强化学习》、王树森《深度强化学习》完整代码下载:8_[Gym] CartPole-V0 (PPO) 文…
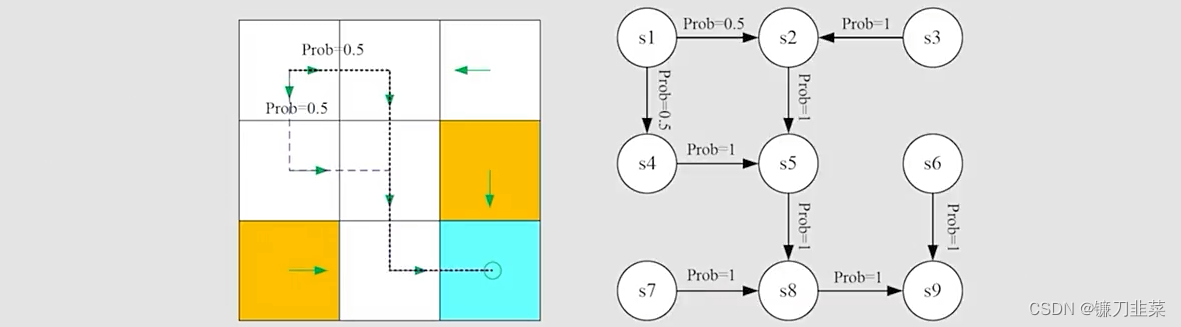
【强化学习】强化学习数学基础:基本概念
强化学习数学基础:基本概念初识强化学习基本概念State(状态)和State Space(状态空间)Action(动作)与Action Space(动作空间)State transition(状态转移&#…
【RL】(task2)策略梯度算法
note 文章目录 note一、策略梯度算法二、策略梯度算法的优缺点时间安排Reference 一、策略梯度算法
策略梯度(Policy Gradient)算法是一类用于解决强化学习问题的算法,它通过直接对策略进行参数化,并利用梯度上升的方法来优化策略…

差分进化算法求解基于移动边缘计算 (MEC) 的无线区块链网络的联合挖矿决策和资源分配(提供MATLAB代码)
一、优化模型介绍
在所研究的区块链网络中,优化的变量为:挖矿决策(即 m)和资源分配(即 p 和 f),目标函数是使所有矿工的总利润最大化。问题可以表述为: max m , p , f F miner …

深度强化学习(王树森)笔记09
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…

基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
Reinforcement Learning from Human Feedback
基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
课程地址:https://www.deeplearning.ai/short-courses/reinforcement-learning-from-human-feedback/
Topic:
Get a conceptual understanding of Reinforcemen…

强化学习_06_pytorch-PPO实践(Hopper-v4)
一、PPO优化
PPO的简介和实践可以看笔者之前的文章 强化学习_06_pytorch-PPO实践(Pendulum-v1) 针对之前的PPO做了主要以下优化:
batch_normalize: 在mini_batch 函数中进行adv的normalize, 加速模型对adv的学习policyNet采用beta分布(0~1): 同时增加MaxMinScale …

政安晨:专栏目录【TensorFlow与Keras实战演绎机器学习】
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎机器学习 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本篇是作者政安晨的专栏《TensorFlow与Keras…
Coppeliasim倒立摆demo
首先需要将使用Python远程控制的文件导入到文件夹,核心是深蓝色的三个文件。 本版本为4.70,其文件所在位置如下图所示,需要注意的是,目前不支持Ubuntu22的远程api: 双击Sphere这一行的灰色文件,可以看到远程…
政安晨:专栏目录【TensorFlow与Keras机器学习实战】
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras机器学习实战 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本篇是作者政安晨的专栏《TensorFlow与Keras机器…
Ubuntu上安装d4rl数据集
Ubuntu上安装d4rl数据集
D4RL的官方 github: https://github.com/Farama-Foundation/D4RL
一、安装Mujoco
1.1 官网下载mujoco210文件
如果装过可以跳过这步 链接:https://github.com/deepmind/mujoco/releases/tag/2.1.0
下载第一个文件即可。我这里是在windo…
ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT-N、instructGPT
写在最前面,23年2.27日起,我个人和十来位博士朋友精读100篇ChatGPT相关技术的论文(每天一篇,100天读完100篇,这100篇的论文清单附在本文最后),过程中几乎每天都会不断优化本文,优化记录见本文文末的“后记”…
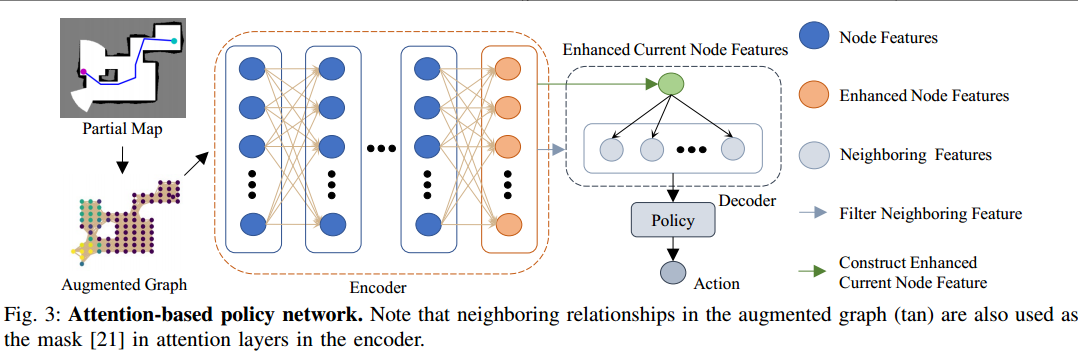
基于注意力神经网络的深度强化学习探索方法:ARiADNE
ARiADNE:A Reinforcement learning approach using Attention-based Deep Networks for Exploration 文章目录 ARiADNE:A Reinforcement learning approach using Attention-based Deep Networks for Exploration机器人自主探索(ARE)ARE的传统边界法非短视路径深度强化学习的方…
ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
写在最前面,23年2.27日起,我个人和十来位博士朋友精读100篇ChatGPT相关技术的论文(每天一篇,100天读完100篇,这100篇的论文清单见此文),过程中几乎每天都会不断优化本文,优化记录见本文文末的“后记”中.. …

百度工程师浅析强化学习
作者 | Jane 导读 本文主要介绍了强化学习(Reinforcement Learning,RL)的基本概念以及什么是RL。强化学习让智能体通过与环境的交互来学习如何做出决策,以获得最大的累积奖励。文章还介绍了策略梯度(Policy Gradient&a…
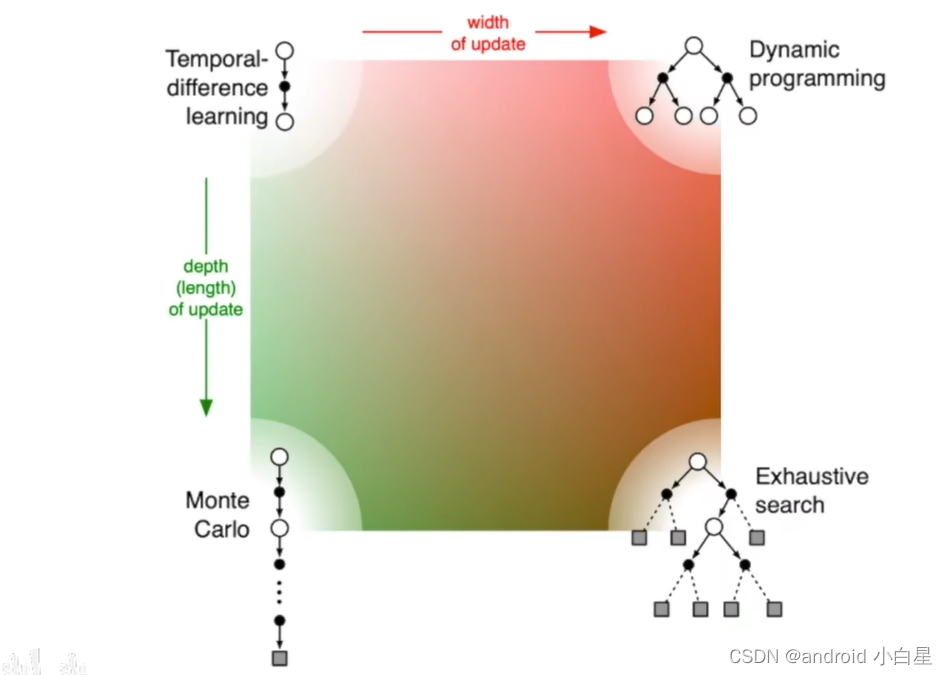
强化学习之蒙特卡罗(MC)、动态规划(DP)、时间差分(TD)
强化学习笔记1.马尔可夫决策过程(MDP)1.马尔可夫性质2.马尔可夫过程3.马尔可夫奖励过程(MRP)4.马尔可夫决策过程(MDP)2.蒙特卡罗(MC)、动态规划(DP)、时间差分(TD)1.蒙特卡罗(MC)2.动态规划(DP)3.时间差分(…
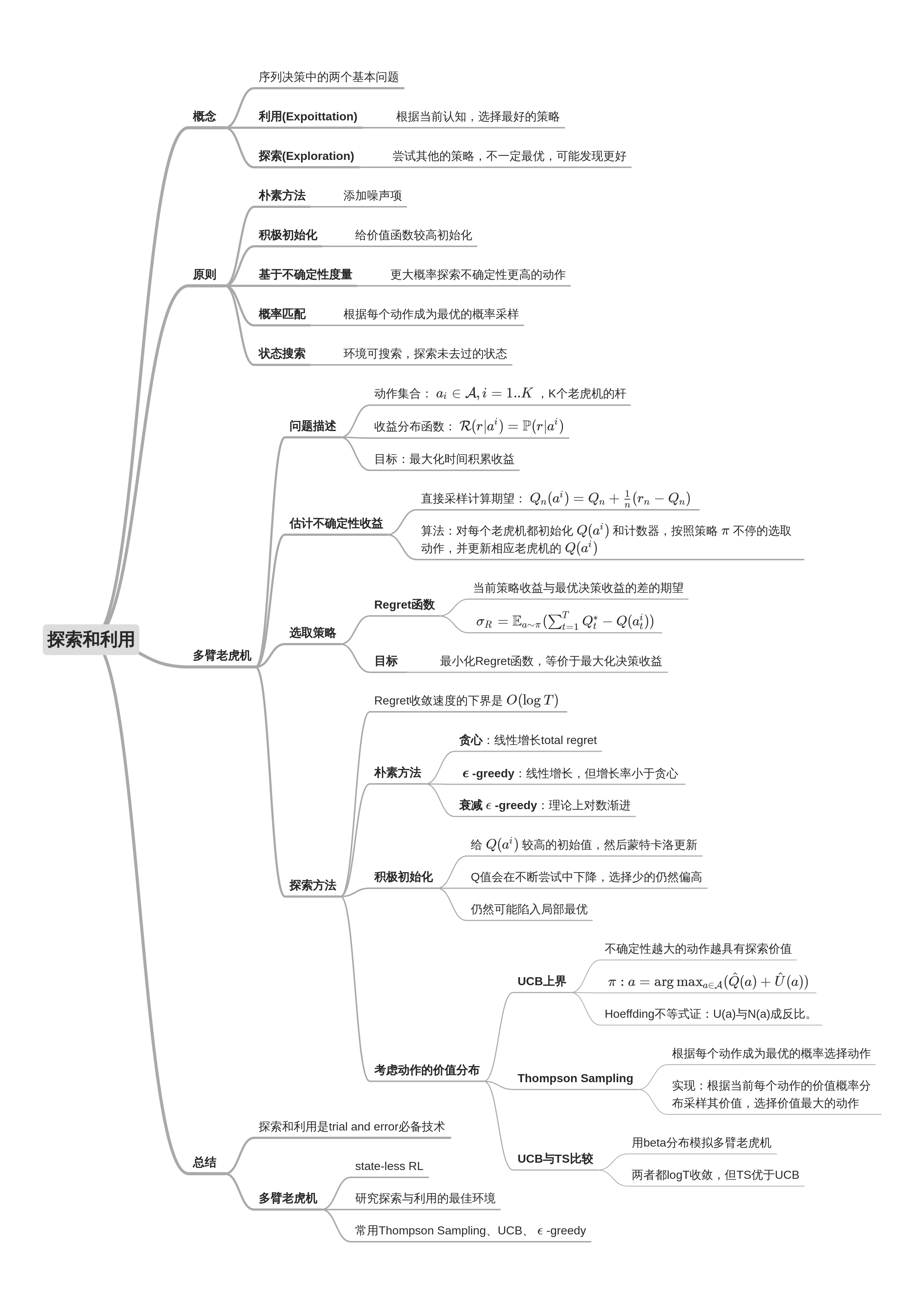
【强化学习】02—— 探索与利用
文章目录 1. 探索与利用2. 探索策略3. 多臂老虎机3.1. 形式化描述3.2. 估计期望奖励3.3. 懊悔regret函数 4. 贪心策略和 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略5. 积极初始化6. 显示地考虑动作的价值分布7. UCB上置信界算法8. 汤普森采样算法总结参考 1. 探索与利用…
论文阅读:机器人跑酷学习
项目开源地址:https://github.com/ZiwenZhuang/parkour
摘要:
跑酷对腿部机动性是一项巨大的挑战,要求机器人在复杂环境中快速克服各种障碍。现有方法可以生成多样化但盲目的机动技能,或者是基于视觉但专门化的技能,…

【强化学习】03 ——马尔可夫决策过程
文章目录 1. 马尔科夫决策过程(Markov Decision Process,MDP)1.1. 马尔科夫性质1.2. 状态转移矩阵1.3. 马尔可夫过程1.3.1. 一个简单的例子 2. 马尔可夫奖励过程2.1. 回报2.2. 价值函数 3. 马尔科夫决策过程3.1. MDP五元组3.2. 策略3.3. 价值函数3.3.1. 状态价值函数…

【强化学习】05 —— 基于无模型的强化学习(Prediction)
文章目录 简介蒙特卡洛算法时序差分方法Example1 MC和TD的对比偏差(Bias)/方差(Variance)的权衡Example2 Random WalkExample3 AB 反向传播(backup)Monte-Carlo BackupTemporal-Difference BackupDynamic Programming Backup Boot…
![[通俗易懂]《动手学强化学习》学习笔记1-第1章 初探强化学习](https://img-blog.csdnimg.cn/direct/c387aa2bf11d4302b81ac81cc9eaece7.png)
[通俗易懂]《动手学强化学习》学习笔记1-第1章 初探强化学习
文章目录 前言第1章 初探强化学习1.1 简介序贯决策(sequential decision making)任务:强化学习与有监督学习或无监督学习的**区别**:改变未来 1.2 什么是强化学习环境交互与有监督学习的区别1:改变环境 (说…
论文阅读:Walk These Ways: 通过行为多样性调整机器人控制以实现泛化
Walk These Ways: 通过行为多样性调整机器人控制以实现泛化
摘要:
通过学习得到的运动策略可以迅速适应与训练期间经历的类似环境,但在面对分布外测试环境失败时缺乏快速调整的机制。这就需要一个缓慢且迭代的奖励和环境重新设计周期来在新任务上达成良…

机器人路径规划:基于Q-learning算法的移动机器人路径规划(可以更改地图,起点,终点),MATLAB代码
一、Q-learning算法
Q-learning算法是强化学习算法中的一种,该算法主要包含:Agent、状态、动作、环境、回报和惩罚。Q-learning算法通过机器人与环境不断地交换信息,来实现自我学习。Q-learning算法中的Q表是机器人与环境交互后的结果&#…
强化学习基础篇[3]:DQN、Actor-Critic详解
【强化学习原理+项目专栏】必看系列:单智能体、多智能体算法原理+项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现 专栏详细介绍:【强化学习原理+项目专栏】必看系列:单智能体、多智能体算法原理+项目实战、相关技巧(调参、画图等、趣味项目实现、学术应…
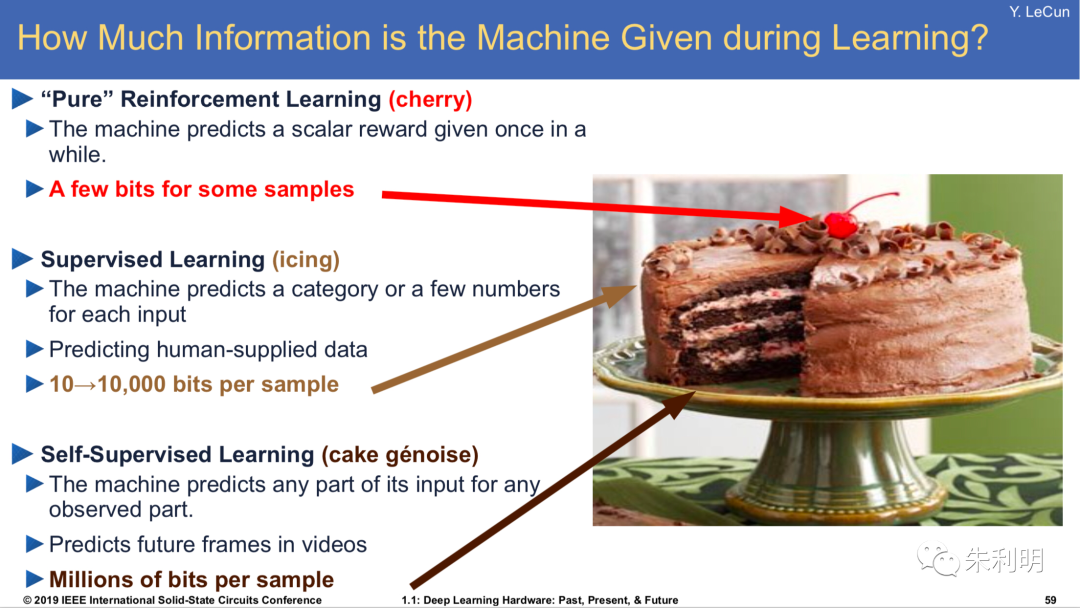
人工智能的奥秘:机器学习的各大门派
本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。 文章分类在学习摘录和笔记专…


【深度强化学习】7. 稀疏奖励和模仿学习
【DataWhale打卡】李宏毅老师视频中的最后两部分,sparse reward和imitation learning。 文章目录1. Sparse Reward1.1 Reward Shaping1.2 Curriculum Learning1.3 Hierarchical RL2. Imitation Learning2.1 Behavior Cloning2.2 Inverse Reinforcement Learning3. 参…

多智能体强化学习理论与算法总结
多智能体强化学习理论与算法总结
先搞明白on-policy和off-policy 【强化学习】一文读懂,on-policy和off-policy 我的理解:on-policy就是使用最新的策略来执行动作收集数据,off-policy的训练数据不是最新策略收集的。on-policy也是使用同个策…
深入理解强化学习——强化学习的基础知识
分类目录:《深入理解强化学习》总目录 在机器学习领域,有一类任务和人的选择很相似,即序贯决策(Sequential Decision Making)任务。决策和预测任务不同,决策往往会带来“后果”,因此决策者需要为…

一文弄懂 if __name__ == “__main__“:(洒洒水啦!)
本篇文章是博主在AI、无人机、强化学习等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在AI学…
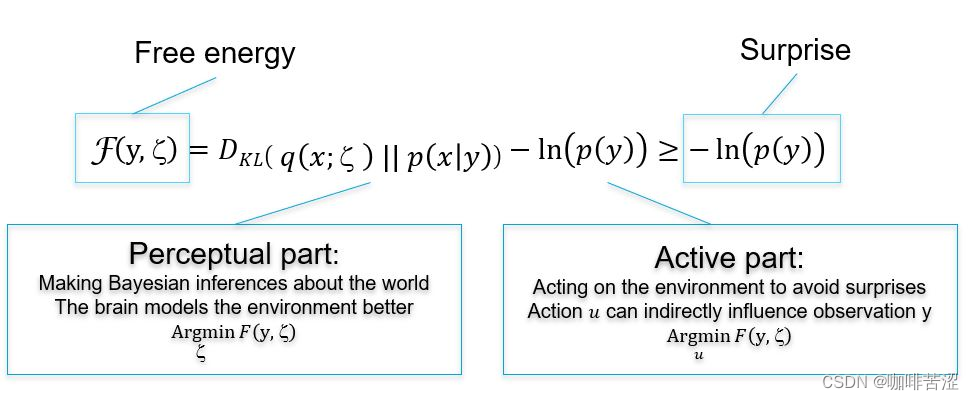
自由能(Free Energy)(一)
博客内容参考,本篇博客所有内容基于在这个链接内容做的一些加工以及思考,强烈建议去看一遍原文。
前言
假设一个场景,你在球场投篮,那么你是如何完成这个投篮动作呢?你的大脑会先根据抛物线公式计算一下角度高度等&a…

【强化学习】Sarsa(lambda)
【强化学习】相关基本概念【强化学习】 Q-Learning【强化学习】 Q-Learning 案例分析【强化学习】 Sarsa【强化学习】 Sarsa(lambda)Sarsa(λ)
1. Sarsa(λ) 是基于Sarsa算法的一种提速算法,为什么是提速呢?
Sarsa算法ÿ…

大规模语言模型人类反馈对齐--PPO算法代码实践
在前面的章节我们已经知道,人类反馈强化学习机制主要包括策略模型、奖励模型、评论模型以及参考模型等部分。需要考 虑奖励模型设计、环境交互以及代理训练的挑战, 同时叠加大语言模型的高昂的试错成本。对于研究人员来说, 使用人类反馈强化学…

【强化学习】相关基本概念
【强化学习】相关基本概念【强化学习】 Q-Learning【强化学习】 Q-Learning 案例分析【强化学习】 Sarsa【强化学习】 Sarsa(lambda)强化学习
强化学习(Reinforcement Learning,RL),也叫增强学习ÿ…
深入理解强化学习——马尔可夫决策过程:预测与控制
分类目录:《深入理解强化学习》总目录 预测(Prediction)和控制(Control)是马尔可夫决策过程里面的核心问题。预测(评估一个给定的策略)的输入是马尔可夫决策过程 < S , A , R , P , γ > …

【深度强化学习】策略梯度方法:REINFORCE、Actor-Critic
参考
Reinforcement Learning, Second Edition
An Introduction
By Richard S. Sutton and Andrew G. Barto非策略梯度方法的问题
之前的算法,无论是 MC,TD,SARSA,Q-learning, 还是 DQN、Double DQN、Dueling DQN…
深入理解强化学习——强化学习的历史:近代强化学习的发展
分类目录:《深入理解强化学习》总目录 在《深入理解强化学习——强化学习的历史》前面的文章中我们讨论了最优控制和试错学习学习的思想,接下来,我们将讨论一些在20世纪60年代和70年代,在试错学习计算和理论研究被相对忽视的时候&…
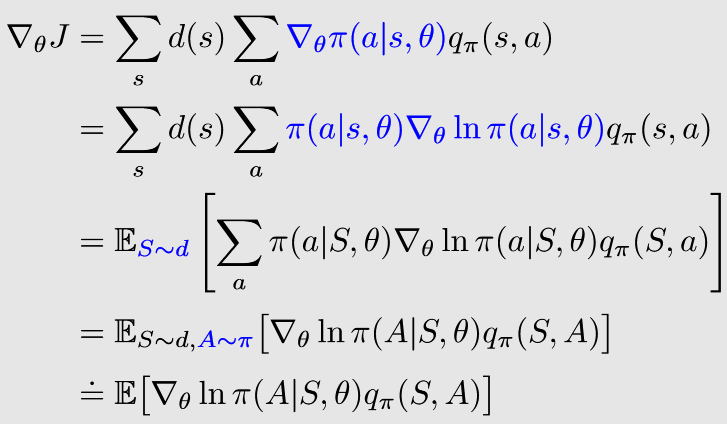
强化学习的数学原理学习笔记 - 策略梯度(Policy Gradient)
文章目录 概览:RL方法分类策略梯度(Policy Gradient)Basic Policy Gradient目标函数1:平均状态值目标函数2:平均单步奖励🟡PG梯度计算 🟦REINFORCE 本系列文章介绍强化学习基础知识与经典算法原…
强化学习的数学原理学习笔记 - 蒙特卡洛方法(Monte Carlo)
文章目录 概览:RL方法分类蒙特卡洛方法(Monte Carlo,MC)MC BasicMC Exploring Starts🟦MC ε-Greedy 本系列文章介绍强化学习基础知识与经典算法原理,大部分内容来自西湖大学赵世钰老师的强化学习的数学原理…
强化学习的数学原理学习笔记 - RL基础知识
文章目录 Roadmap🟡基础概念贝尔曼方程(Bellman Equation)基本形式矩阵-向量形式迭代求解状态值 vs. 动作值 🟡贝尔曼最优方程(Bellman Optimality Equation,BOE)基本形式迭代求解 本系列文章介…

强化学习应用(七):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的…

【强化学习】13 —— Actor-Critic 算法
文章目录 REINFORCE 存在的问题Actor-CriticA2C: Advantageous Actor-Critic代码实践结果 参考 REINFORCE 存在的问题
基于片段式数据的任务 通常情况下,任务需要有终止状态,REINFORCE才能直接计算累计折扣奖励 低数据利用效率 实际中&#…

深度强化学习(王树森)笔记04
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…
深度强化学习(王树森)笔记08
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…
Softmax Strategy
1. epsilon-greedy strategy
11111
2. UCB strategy
222
3. Softmax strategy
333
4. Gradient strategy
444 References
[1] 科学网—【RL系列】Multi-Armed Bandit笔记——Softmax选择策略 - 管金昱的博文
[2] The Epsilon-Greedy Algorithm | James D. McCaffrey
Double-DQN算法
Double-DQN算法的原理简介、与DQN对比等。 参考深度Q网络进阶技巧
1. 原理简介
在DQN算法中,虽然有target_net和eval_net,但还是容易出现Q值高估的情况,原因在于训练时用通过target_net选取最优动作 a ⋆ argmax a Q ( s t 1 , a ; w…

Talk|加州大学圣地亚哥分校程旭欣:视觉反馈下足式机器人的全身操作与运动
本期为TechBeat人工智能社区第576期线上Talk。 北京时间3月6日(周三)20:00,加州大学圣地亚哥分校博士生—程旭欣的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “视觉反馈下足式机器人的全身操作与运动”,向大家系统地介绍…

开悟Optimization guide for intermediate tracks
目录 认识模型
参考方案(按模块拆解) 认识模型
模型控制1名英雄进行镜像1 v 1对战
Actor集群资源为64核CPU
问题特点:单一公平对抗场景(同英雄镜像对赛),单位时间样本产能低,累计训练资源相…

Talk | 马里兰大学博士生吴曦旸:分布式多智能体强化学习在复杂交通轨迹规划中的应用
本期为TechBeat人工智能社区第545期线上Talk! 北京时间11月09日(周四)20:00,马里兰大学博士生—吴曦旸的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “分布式多智能体强化学习在复杂交通轨迹规划中的应用”,介…

【rl-agents代码学习】02——DQN算法
文章目录 Highway-env Intersectionrl-agents之DQN*Implemented variants*:*References*:Query agent for actions sequence探索策略神经网络实现小结1 Record the experienceReplaybuffercompute_bellman_residualstep_optimizerupdate_target_network小结2 exploration_polic…
强化学习算法TRPO的理解
Trust Region Policy Optimization 角度一:off-policy重要性采样 Importance Sampling梯度优化 角度二:数值优化置信域优化蒙特卡洛近似 TRPO算法的全称是 Trust Region Policy Optimization,即信赖域策略优化。 角度一:off-polic…
政安晨:【TensorFlow与Keras实战演绎机器学习】专栏 —— 目录
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎机器学习 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本篇是作者政安晨的专栏《TensorFlow与Keras…
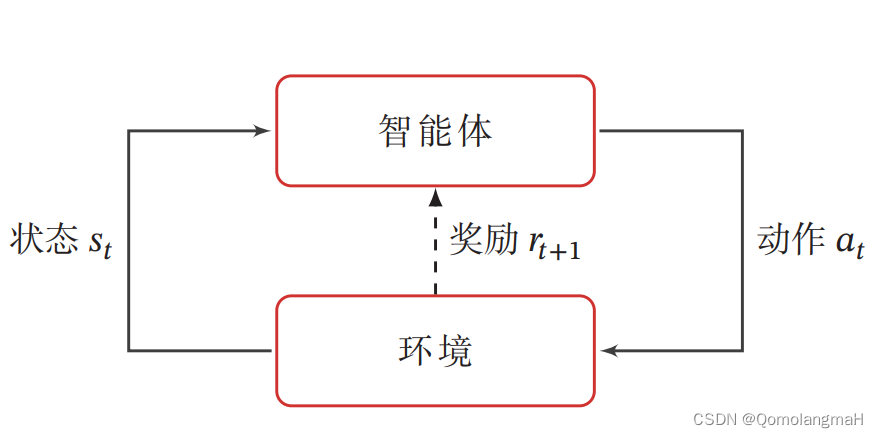
【深度学习】强化学习(一)强化学习定义
文章目录 一、强化学习问题1、交互的对象1. 智能体(Agent)2. 环境(Environment) 2、强化学习的基本要素1. 状态 𝑠2. 动作 𝑎3. 策略 𝜋(𝑎|𝑠)4. 状态转移概率 …

分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey 摘要一、介绍二、基础知识回顾2.1 强化学习2.2 分层强化学习2.2.1 子任务符号2.2.2 基于半马尔可夫决策过程的HRL符号 2.3 通用项定义 三、分层强化学习方法3.1 学习分层策略 (LHP)3.1…
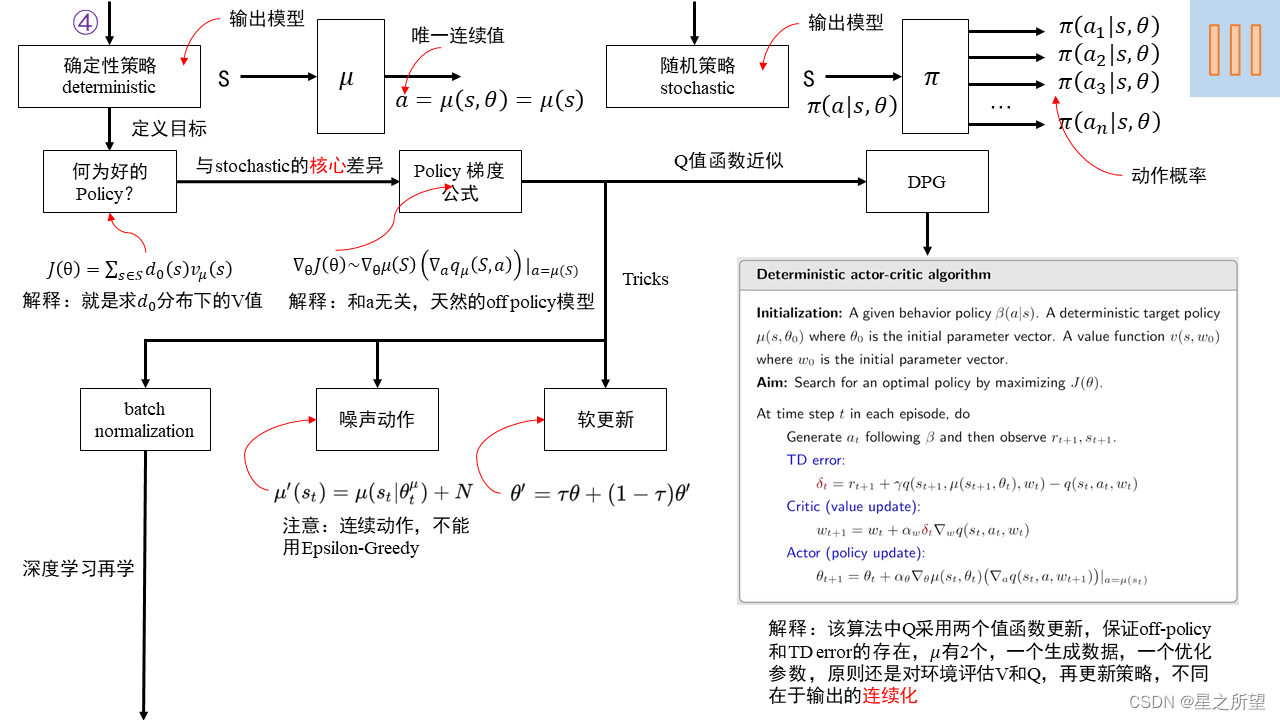
《强化学习的数学原理》思维导图,供初学者参考
对应课程:
【强化学习的数学原理】课程:从零开始到透彻理解(完结)_哔哩哔哩_bilibili
![强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient-Cart pole游戏展示](https://img-blog.csdnimg.cn/img_convert/7172e31965f4a38632ef542815a3cbf2.png)
强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient-Cart pole游戏展示
强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient-Cart pole游戏展示
强化学习(Reinforcement learning,简称RL)是机器学习中的一个领域,区别与监督学习和无监督学习,强调如何基于环境而行动&#x…
深入理解强化学习——强化学习的局限性与适用范围
分类目录:《深入理解强化学习》总目录 强化学习十分依赖“状态”这个概念,它既作为策略和价值函数的输人,又同时作为模型的输人与输出。一般,我们可以把状态看作传递给智能体的一种信号,这种信号告诉智能体“当前环境如…
深入理解强化学习——强化学习的复杂性、局限性和适用范围
分类目录:《深入理解强化学习》总目录 强化学习的复杂性
首先要注意的是,强化学习中的观察结果取决于智能体选择的动作,某种程度上可以说是动作导致的结果。如果智能体选择了无用的动作,观察结果不会告诉你做错了什么或如何选择动…

值迭代和策略迭代【强化学习】
强化学习笔记 主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门.
第一章 强化学习基本概念 第二章 贝尔曼方程 第三章 贝尔曼最优方程 第四章 值迭代和策略迭代 文章目录 强化学习笔记一、Value It…

Pytorch深度强化学习2-1:基于价值的强化学习——DQN算法
目录 0 专栏介绍1 基于价值的强化学习2 深度Q网络与Q-learning3 DQN原理分析4 DQN训练实例 0 专栏介绍
本专栏重点介绍强化学习技术的数学原理,并且采用Pytorch框架对常见的强化学习算法、案例进行实现,帮助读者理解并快速上手开发。同时,辅…

深度学习的进展及其在各领域的应用
深度学习,作为人工智能的核心分支,近年来在全球范围内引起了广泛的关注和研究。它通过模拟人脑的学习机制,构建复杂的神经网络结构,从大量数据中学习并提取有用的特征表示,进而解决各种复杂的模式识别问题。
一、深度…
Humanoid-Gym 开源人形机器人端到端强化学习训练框架!星动纪元联合清华大学、上海期智研究院发布!
系列文章目录 前言
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer
GitHub Repository: GitHub - roboterax/humanoid-gym: Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer 一、介…
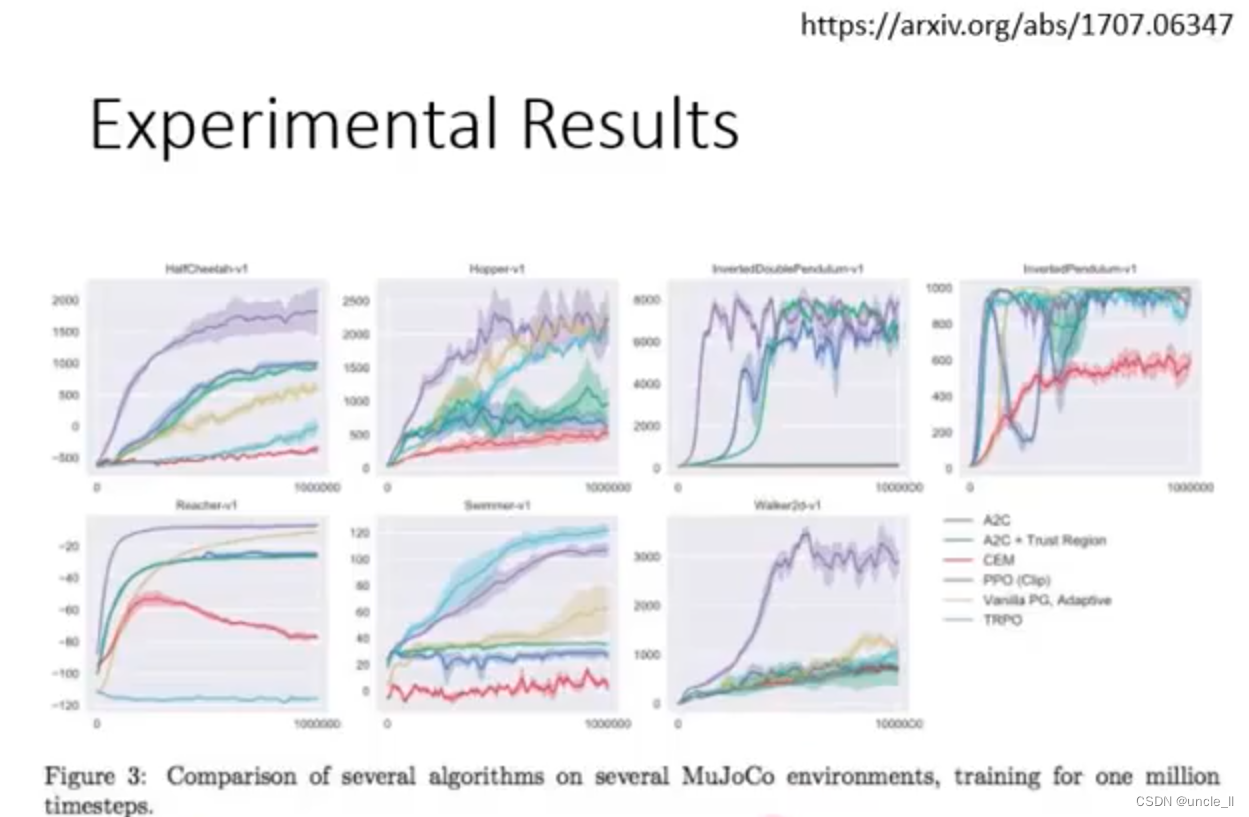
机器学习——PPO补充
On-policy vs Off-policy 今天跟环境互动,并学习是on-policy 只是在旁边看,就是Off-policy 从p中选q个重要的,需要加一个weight p(x)/q(x) p和q不能相差太多 采样数太少导致分布差很多,导致weight发生变化
On-Policy -&g…

【强化学习】14 —— A3C(Asynchronous Advantage Actor Critic)
A3C算法( Asynchronous Methods for Deep Reinforcement Learning)于2016年被谷歌DeepMind团队提出。A3C是一种非常有效的深度强化学习算法,在围棋、星际争霸等复杂任务上已经取得了很好的效果。接下来,我们先从A3C的名称入手&…

优先经验回放(prioritized experience replay)
prioritized experience replay 思路
优先经验回放出自ICLR 2016的论文《prioritized experience replay》。
prioritized experience replay的作者们认为,按照一定的优先级来对经验回放池中的样本采样,相比于随机均匀的从经验回放池中采样的效率更高&…

深度强化学习(王树森)笔记11
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.c…
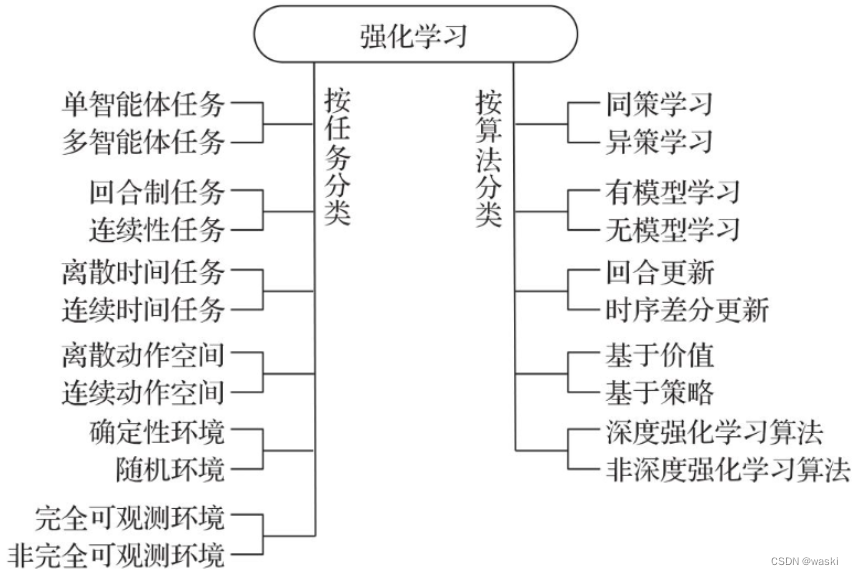
【强化学习笔记一】初识强化学习(定义、应用、分类、性能指标、小车上山案例及代码)
文章目录 第1章 初识强化学习1.1 强化学习及其关键元素1.2 强化学习的应用1.3 强化学习的分类1.3.1 按任务分类1.3.2 按算法分类 1.4 强化学习算法的性能指标1.5 案例:基于Gym库的智能体/环境接口1.5.1 安装Gym库1.5.2 使用Gym库1.5.3 小车上山1.5.3.1 有限动作空间…

深度学习与强化学习的绝妙融合:引领未来智能科技新潮流!
深度学习在强化学习中的应用已经取得了显著的成果,特别是在处理复杂环境和大规模数据方面。
一、概述
强化学习是一种独特的机器学习范式,其核心在于通过代理与环境的交互来学习最优行为策略。这种学习方式是试错性的,代理在不断地尝试、接…